本文主要是介绍KGAT推荐系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1:数据处理,数据分割。2:模型构建。包括各个网络的搭建损失函数的设计等。3:构建trainer,包括模型训练fit,和模型评估evaluate。4:数据预测
1:数据处理,数据分割
根据需要的数据集合inter,link,kg数据。进行remap。数据进行分割操作包括以8:1:1的方式分割成train,valid,test。并且根据模型的不同计算neg_item。kg_neg_item。最后返回三个dataloader。
2:KGAT模型构建
网络层的设计,Loss设计,以及Aggarater设计,A的初始化,Cal_Loss,Cal_kg_loss,Updata_A,predict。
3:构建trainer,包括,构建优化器,fit函数,和evaluate函数。
1:数据处理
拼接路径
kg_path = os.path.join(dataset_path, f’{token}.kg’)
‘/Users/apple/Desktop/Code/Recommendation_System/rec/config/…/dataset_example/ml-100k/ml-100k.kg’
这个为拼接起来的路径加文件。
with open(kg_path, ‘r’) as f:
head = f.readline()[:-1]
‘head_id:token\trelation_id:token\ttail_id:token’
for field_type in head.split(field_separator):
field, ftype = field_type.split(‘:’)
columns.append(field)
usecols.append(field_type)
dtype[field_type] = np.float64 if ftype == FeatureType.FLOAT else str
columns->[‘head_id’, ‘relation_id’, ‘tail_id’]
usecols->[‘head_id:token’, ‘relation_id:token’, ‘tail_id:token’]
dtype->{‘head_id:token’: <class ‘str’>, ‘relation_id:token’: <class ‘str’>, ‘tail_id:token’: <class ‘str’>}
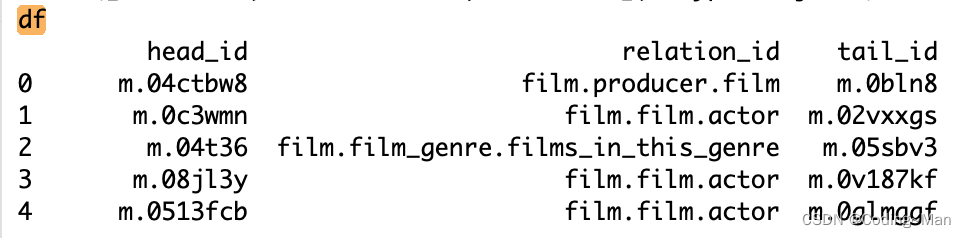
之后用df = pd.read_csv(filepath, delimiter=self.config[‘field_separator’], usecols=usecols, dtype=dtype)读取数据
读取的kg数据
这篇关于KGAT推荐系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





