本文主要是介绍为什么你学不会递归?谈谈我的经验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文已收录到 GitHub · AndroidFamily,有 Android 进阶知识体系,欢迎 Star。技术和职场问题,请关注公众号 [彭旭锐]。
前言
大家好,我是小彭。
今天分享到计算机科学中一个基础又非常重要的概念 —— 递归。递归是计算机中特有的概念,你很难在现实世界中找到一个恰当的例子与之关联起来。因此,对于很多初学编程的人,一开始会很难理解。
那么,究竟什么是递归,我们为什么要使用递归?我们今天就围绕这两个问题展开。
学习路线图:
1. 什么是递归?
递归(Recursion)是一种通过 “函数自己调用自己” 的方式,将问题重复地分解为同类子问题,并最终解决问题的编程技巧。
举个例子,要求一个数 n n n 的阶乘 n ! = n ∗ ( n − 1 ) ∗ ( n − 2 ) ∗ … ∗ 2 ∗ 1 n! = n*(n-1)*(n-2)*…*2*1 n!=n∗(n−1)∗(n−2)∗…∗2∗1 ,有 2 种思考问题的思路:
- 递推(一般思维): 我们从 1 1 1 开始,用 1 1 1 乘以 2 2 2 得到 2 ! 2! 2! 问题的解,用 3 3 3 乘以 2 ! 2! 2! 得到 3 ! 3! 3! 问题的解。依次类推,直到用 n n n 乘以 ( n − 1 ) ! (n-1)! (n−1)! 得到原问题 n ! n! n! 的解。这就是用递推解决问题,这是相对简单直接的思考方式;
- 递归(计算机思维): 我们把 n ! n! n! 的问题拆分为一个 ( n − 1 ) ! (n-1)! (n−1)! 的问题,如果我们知道 ( n − 1 ) ! (n-1)! (n−1)! 的解,那么将它乘以 n n n 就可以得出 n ! n! n! 的解。以此类推,我们将一个 ( n − 1 ) ! (n-1)! (n−1)! 的问题拆分为同类型的规模更小的 ( n − 2 ) ! (n-2)! (n−2)! 子问题,直到拆分到无法拆分,可以直接得出结果 1 ! 1! 1! 问题。此时,我们再沿着拆分问题的路径,反向地根据子问题的解求出原问题的解,最终得到原问题 n ! n! n! 的结果。这就是用递归解决问题。
求 n!
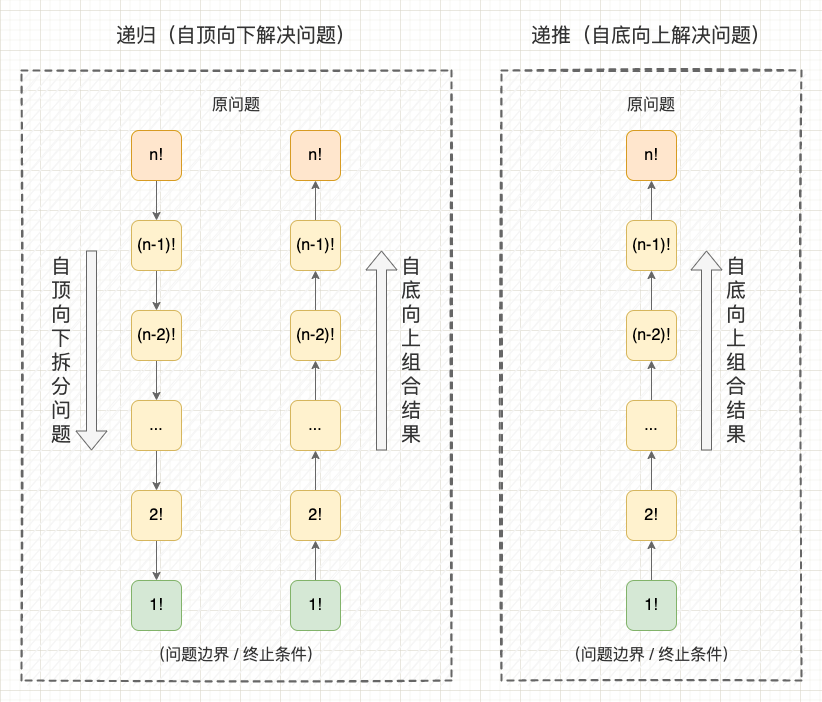
从这个例子可以看出, 递归其实是在重复地做 2 件事:
- 1、自顶向下拆分问题: 从一个很难直接求出结果的、规模较大的原问题开始,逐渐向下拆分为规模较小的子问题(从 n ! n! n! 拆分到 ( n − 1 ) ! (n-1)! (n−1)!),直到拆分到问题边界时停止拆分,这个拆分的过程就是 “递”(问题边界也叫基准情况或终止条件);
- 2、自底向上组合结果: 从问题边界开始,逐渐向上传递并组合子问题的解(从 ( n − 1 ) ! (n-1)! (n−1)! 得到 n ! n! n!),直到最终回到原问题获得结果,这个组合的过程就是 “归”。
看到这里你会不会产生一个疑问: 我们直接从问题边界 1 ! 1! 1! 一层层自底向上组合结果也可以得到 n ! n! n! 的解,自顶向下拆分问题的过程显得没有必要。确实,对于对于这种原问题与子问题只是 “线性” 地减少一个问题规模的情况,确实是这样。但是对于很多稍微复杂一些的问题,原问题与子问题会构成一个树型的 “非线性” 结构,这个时候就适合用递归解决,很难用递推解决。
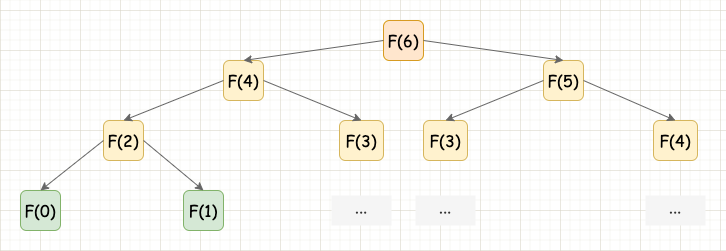
举个例子, 求斐波那契数列,这个问题同时也是 LeetCode 上的一道典型例题:LeetCode · 509. 斐波那契数:该数列从 1 1 1 开始,每一项数字都是前面两项数字的和。
LeetCode 例题

虽然,我们可以利用递推的方式从 F ( 0 ) F(0) F(0) 和 F ( 1 ) F(1) F(1) 自底向上推导出 F ( n ) F(n) F(n) 的解,但是这种非线性的方式在编程语言中很难实现,而使用递归的方式自顶向下地解决问题,在编码上是很容易实现的。
当然,这段代码中存在非常多的重复计算,最终使得整个算法的时间复杂度达到惊人的指数级 O ( 2 n ) O(2^n) O(2n)。例如在计算 F ( 5 ) = F ( 3 ) + F ( 4 ) F(5)=F(3)+F(4) F(5)=F(3)+F(4) 和 F ( 6 ) = F ( 4 ) + F ( 5 ) F(6)=F(4)+F(5) F(6)=F(4)+F(5) 的时候, F ( 4 ) F(4) F(4) 就被重复计算 2 次,这种重复计算完全相同的子问题的情况就叫 重叠子问题 ,以后我们再专门讨论。
用递归解决斐波那契数列
用递归解决(无优化)
class Solution {fun fib(N: Int): Int {if(N == 0){return 0}if(N == 1){return 1}// 拆分问题 + 组合结果return fib(N - 1) + fib(N - 2)}
}
2. 递归的解题模板
- 1、判断当前状态是否异常,例如数组越界,
n < 0等; - 2、判断当前状态是否满足终止条件,即达到问题边界,可以直接求出结果;
- 3、递归地拆分问题,缩小问题规模;
- 4、组合子问题的解,结合当前状态得出最终解。
fun func(n){// 1. 判断是否处于异常条件if(/* 异常条件 */){return}// 2. 判断是否满足终止条件(问题边界)if(/* 终止条件 */){return result}// 3. 拆分问题result1 = func(n1)result2 = func(n2)...// 4. 组合结果return combine(result1, result2, ...)
}
3. 计算机如何实现递归?
递归程序在解决子问题之后,需要沿着拆分问题的路径一层层地原路返回结果,并且后拆分的子问题应该先解决。这个逻辑与栈 “后进先出” 的逻辑完全吻合:
- 拆分问题: 就是一次子问题入栈的过程;
- 组合结果: 就是一次子问题出栈的过程。
事实上,这种出栈和入栈的逻辑,在编程语言中是天然支持的,不需要程序员实现。程序员只需要维护拆分问题和组合问题的逻辑,一次函数自调用和返回的过程就是一次隐式的函数出栈入栈过程。在程序运行时,内存空间中会存在一块维护函数调用的区域,称为 函数调用栈 ,函数的调用与返回过程,就天然对应着一次子问题入栈和出栈的过程:
- 调用函数: 程序会创建一个新的栈帧并压入调用栈的顶部;
- 函数返回: 程序会将当前栈帧从调用栈栈顶弹出,并带着返回值回到上一层栈帧中调用函数的位置。
我们在分析递归算法的空间复杂度时,也必须将隐式的函数调用栈考虑在内。
4. 递归与迭代的区别
递归(Recursion)和迭代(Iteration)都是编程语言中重复执行某一段逻辑的语法。
语法上的区别在于:
- 迭代: 通过迭代器(for/while)重复执行某一段逻辑;
- 递归: 通过函数自调用重复执行函数中的一段逻辑。
核心区别在于解决问题的思路不同:
- 迭代:迭代的思路认为只要从问题边界开始,在所有元素上重复执行相同的逻辑,就可以获得最终问题的解(迭代的思路与递推的思路类似);
- 递归:递归的思路认为只要将原问题拆分为子问题,在每个子问题上重复执行相同的逻辑,最终组合所有子问题的结果就可以获得最终问题的解。
例如, 在计算 n! 的问题中,递推或迭代的思路是从 1! 开始重复乘以更大的数,最终获得原问题 n! 的解;而递归的思路是将 n! 问题拆分为 (n-1)! 的问题,最终通过 (n-1)! 问题获得原问题 n! 的解。
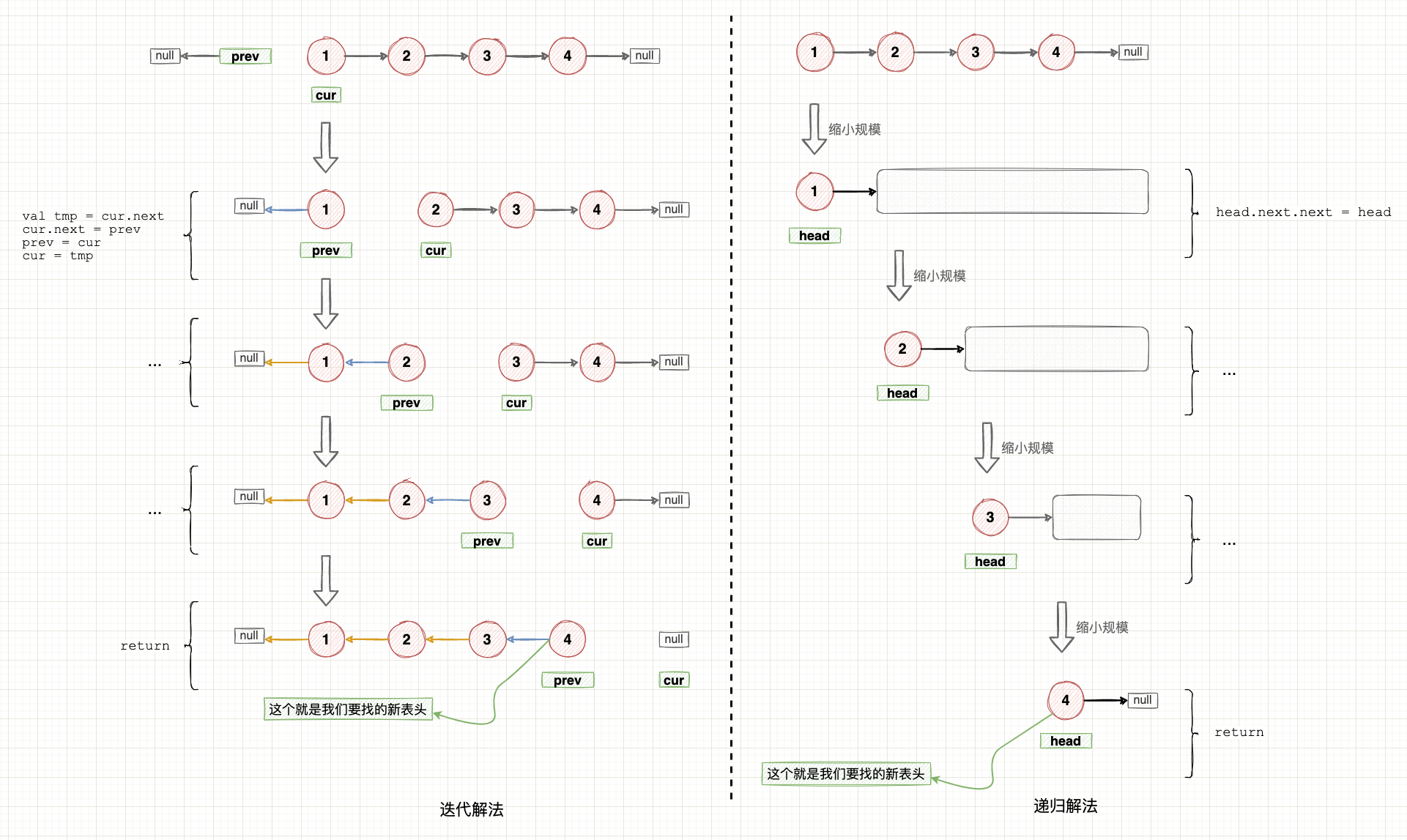
再举个例子,面试中出现频率非常高的反转链表问题,同时也是 LeetCode 上的一道典型例题:LeetCode 206 · 反转链表。假设链表为 1 → 2 → 3 → 4 → ∅,我们想要把链表反转为 ∅ ← 1 ← 2 ←3 ←4,用迭代和递归的思路是不同的:
- 迭代: 迭代的思路认为,只要重复地在每个节点上处理同一个逻辑,最终就可以得到反转链表,这个逻辑是:“将当前节点的 next 指针指向前一个节点,再将游标指针移动到后一个节点”。
- 递归: 递归的思路认为,只要将反转链表的问题拆分为 “让当前节点的 next 指针指向后面整段子链的反转链表”,在每个子链表上重复执行相同的逻辑,最终就能够获得整个链表反转的结果。
这两个思路用示意图表示如下:
示意图
迭代题解
class Solution {fun reverseList(head: ListNode?): ListNode? {var cur: ListNode? = headvar prev: ListNode? = nullwhile (null != cur) {val tmp = cur.nextcur.next = prevprev = curcur = tmp}return prev}
}
迭代解法复杂度分析:
- 时间复杂度:每个节点扫描一次,时间复杂度为 O ( n ) O(n) O(n);
- 空间复杂度:使用了常量级别变量,空间复杂度为 O ( 1 ) O(1) O(1)。
递归题解
class Solution {fun reverseList(head: ListNode?): ListNode? {if(null == head || null == head.next){return head}val newHead = reverseList(head.next)head.next.next = headhead.next = nullreturn newHead}
}
递归解法复杂度分析:
- 时间复杂度:每个节点扫描一次,时间复杂度为 O ( n ) O(n) O(n);
- 空间复杂度:使用了函数调用栈,空间复杂度为 O ( n ) O(n) O(n)。
理论上认为迭代程序的运行效率会比递归程序更好,并且任何递归程序(不止是尾递归,尾递归只是消除起来相对容易)都可以通过一个栈转化为迭代程序。但是,这种消除递归的做法实际上是以牺牲程序可读性为代价换取的,一般不会为了运行效率而刻意消除递归。
不过,有一种特殊的递归可以被轻松地消除,一些编译器或运行时会自动完成消除工作,不需要程序员手动消除,也不会破坏代码的可读性。
5. 尾递归
在编程语言中,尾调用是指在一个函数的最后返回另一个函数的调用结果。如果尾调用最后调用的是当前函数本身,就是尾递归。为什么我们要专门定义这种特殊的递归形式呢?因为尾递归也是尾调用,而在大多数编程语言中,尾调用可以被轻松地消除 ,这使得程序可以模拟递归的逻辑而又不损失性能,这叫 尾递归优化 / 尾递归消除 。例如,以下 2 段代码实现的功能是相同的,前者是尾递归,而后者是迭代。
尾递归
fun printList(itr : Iterator<*>){if(!itr.hasNext()) {return}println(itr.next())// 尾递归printList(itr)
}
迭代
fun printList(itr : Iterator<*>){while(true) {if(!itr.hasNext()) {return}println(itr.next())}
}
可以看到,使用一个 while 循环和若干变量消除就可以轻松消除尾递归。
6. 总结
到这里,相信你已经对递归的含义以及递归的强大之处有所了解。 递归是计算机科学中特有的解决问题的思路:先通过自顶向下拆分问题,再自底向上组合结果来解决问题。这个思路在编程语言中可以用函数自调用和返回实现,因此递归在编程实现中会显得非常简洁。 正如图灵奖获得者尼克劳斯·维尔特所说:“递归的强大之处在于它允许用户用有限的语句描述无限的对象。因此,在计算机科学中,递归可以被用来描述无限步的运算,尽管描述运算的程序是有限的。”
另外,你会发现 “先拆分问题再合并结果” 的思想与 “分治思想” 相同,那么你认为递归和分治是等价的吗?这个我们下回说。
发现一个 Google 的小彩蛋:在 Google 搜索里搜索 “递归”,提示词里会显示 “您是不是要找:递归”。这就会产生递归的效果的,因为点击提示词 “递归” 后,还是会递归地显示 “您是不是要找:递归”。哈哈,应该是 Google 跟程序员开的小玩笑。
参考资料
- 数据结构与算法分析 · Java 语言描述(第 1 章 · 引论、第 3 章 · 表栈和队列、第 10 章 · 算法设计技巧)—— [美] Mark Allen Weiss 著
- 算法导论(第 4 章 · 分治策略)—— [美] Thomas H. Cormen 等 著
- 算法吧 · 递归 —— liweiwei1419 著
- Recursion (computer science) —— Wikipedia
- Divide-and-conquer algorithm —— Wikipedia
- Iterator —— Wikipedia
- Tail call —— Wikipedia
这篇关于为什么你学不会递归?谈谈我的经验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




