本文主要是介绍PolyMapper论文简读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 1 摘要
- 2 方法
- 2.1 Polygon Representation
- 2.2 Multiple Targets
- 2.3 From Graphs to Polygons
- 2.4 Pipeline
- CNN Part
- RNN Part
- 2.5 Implementation Details
- 3 结果
1 摘要
我们提出了一种新的方法,名为PolyMapper,以绕过传统的(空中)图像的像素分割,并直接预测向量表示中的对象。直接从头顶的图像中提取一个城市的拓扑图,作为建筑足迹和道路网络的集合。为了统一不同类型对象的形状表示,我们还提出了一种新的序列化方法,将图结构重新定义为封闭多边形。在几个城市现有的和自收集的大规模数据集上进行了实验。我们的实证结果表明,我们的端到端可学习模型能够以完全自动化的方式绘制建筑足迹的多边形,非常接近现有在线地图服务的结构。与最先进的定量和定性的比较也表明,我们的方法取得了良好的性能水平。据我们所知,大尺度拓扑图的自动提取是遥感界的一个新贡献,我们相信这将有助于开发具有更知情的几何约束条件的模型。
2 方法
我们介绍了一种新的、通用的方法来提取使用多边形的拓扑图。我们首先讨论使用多边形表示来描述图像中的对象。

2.1 Polygon Representation
我们将对象表示为多边形。正如在PolygonRNN和PolygonRNN++中一样,我们依靠CNN基于图像证据找到关键点,然后通过RNN进行顺序连接。PolyMapper的一个根本区别是,它完全自动运行,没有任何人工干预,而不是PolygonRNN和PolygonRNN++,后者最初是为了加速人工对象注释。PolygonRNN和PolygonRNN++中讨论的所有模型(包括其“预测模式”)要求用户首先绘制包含目标对象的边界框,如果对象描述不正确,可能提供额外手动干预(例如拖动/添加/删除一些关键点)。
我们完全避免了任何手动干预,并提出了一个全自动的工作流程。然而,这主要有两个原因:(1)在给定的图像补丁中会出现多个感兴趣的对象,(2)不同目标对象的形状会显著不同。例如,建筑在图像中是有限范围的封闭形状,而道路网络跨越整个场景,最好用一般的图拓扑来描述。因此,我们提出了两个增强功能来解决这些问题,然后介绍了一般的流程,如上图所示,用于生成对象多边形。
2.2 Multiple Targets
以前的工作,如PolygonRNN和PolygonRNN++,只适用于为每个感兴趣的对象提供一个边界框。因此,这些方法不能检测对象,如给定图像中的多个建筑物。首先,我们通过添加一个边界框检测步骤来将图像分割到单独的建筑实例中,这允许计算所有建筑的单独多边形。
为此,我们将功能金字塔网络(FPN)集成到我们的工作流中,并使其成为一个端到端模型。FPN进一步利用CNNs的多尺度、金字塔层次,提高了更快的RCNN使用的区域建议网络(RPN)的性能,并形成了一套所谓的特征金字塔。一旦生成了各个建筑的图像,流程的其余部分将按照描述的一般程序进行处理。
2.3 From Graphs to Polygons
道路或河流等物体的固有拓扑是一个一般图,而不是一个多边形,而该图的顶点不一定以顺序连接。为了将这些对象的拓扑重新表述为多边形,我们遵循迷宫求解算法的原理,即墙跟随器,也被称为左/右规则(如下图所示): 如果迷宫是简单连接,那么通过一只手与迷宫的一面墙接触,算法保证到达一个出口。
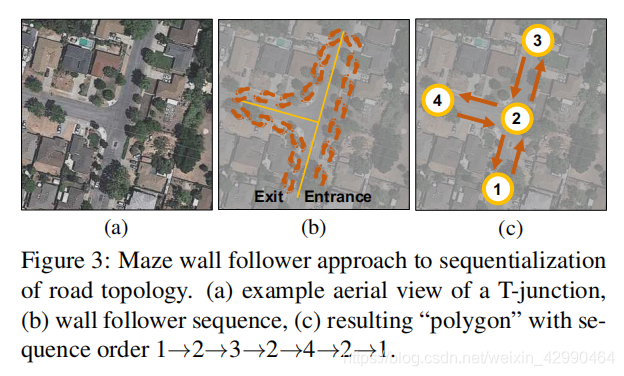
我们应用这一原理来提取道路序列。如图3所示,道路网可以看作是一个有向图。每个路段都有两个方向相反的定向边缘。我们假设,对于给定的一对有向边,当你面对旅行方向时,一个边的合作伙伴总是在其左边。假设我们站在任意的边缘,我们按照下面的入口出口2 3 4 1 2 3 4 57 6 8 9 1规则旅行:(1)总是沿着边缘的方向走;(2)遇到十字路口时右转;(3)遇到死胡同时转身。按照这组规则,我们在完成完整循环后返回起点(见图。3b)。最后,我们按行驶顺序连接途中的所有关键点(即十字路口和死胡同),以获得一个“多边形”(见图。3c)。这样,道路图中最初不是顺序的顶点就会变成有序的。
对于较大的影像切片或更密集的道路网,可以存在多个多边形,如图所示。4.然而,我们只能按照上述规则得到单个多边形。为了获取图中的所有多边形,我们需要遍历所有路段两次(前后两段)。在实践中,序列生成过程如下:我们首先遍历任意多边形中的所有边,对于未访问的有向边,我们随机选择一个边,并按照规则集遍历它,直到图中的所有边都被访问为止。

2.4 Pipeline
CNN Part
对于输入图像,我们首先使用一个没有尾层的VGG-16作为CNN主干来提取输入图像1/8大小的跳跃特征(见图。2).同时,FPN还从主干的不同层获取特征来构建一个特征金字塔,并预测包含建筑的多个边界框。
对于一个跳过特征图及其边界框,然后是RoIAlign,获得局部特征F。我们将卷积层应用于该特征,以生成一个描述感兴趣对象的建筑边界B的热图掩模。接下来是额外的卷积层,输出一个候选关键点的掩模,用V表示。B和V的大小都等于输入图像大小的1/8。在所有的候选关键点中,我们选择那些在V中得分最高的w点作为起点y0(与yy1相同,见图。5).

如图所示。2、路网提取的主要程序与建筑物的情况相同。我们只根据道路的情况调整RoI定义和顶点选择。在构建RoI在图像补丁中采样时,道路RoI对应于整个图像补丁。当然,生成的热图B指的是道路的中心线,而不是建筑边界。顶点选择通过在图像边缘选择起点候选点,并选择得分最高的点作为起点y0(与yy1相同)的唯一外部多边形,顶点选择适应道路拓扑。请注意,外部多边形的每个段应传递两次,除非该段与内部多边形共享。因此,在预测了外多边形后,我们选择了一个段的两个顶点,它们只作为y-1和y0(以反向方向传递了一次),以进一步预测一个潜在的内多边形。
RNN Part
如图所示。5、RNN在每个步骤t输出yt的潜在位置P(yt+1|yt、yt-1、y0)。我们同时输入yt和yt-1来计算yt+1的条件概率分布,因为它允许定义唯一的方向。如果给定具有多边形顺序的两个相邻顶点,则该多边形中的下一个顶点将唯一确定。注意,分布还涉及端信号(序列端),表示多边形达到闭合形状,预测程序应达到结束。因此,多边形中的最后一个端顶点对应于第一个起始顶点y0,因此必须在每个步骤中包含它。
在实践中,我们最终连接F、B、V、y0(也用于yy1预测多边形),并将得到的张量与ConvLSTM[45]单元供给多层RNN,以便顺序预测描述感兴趣对象的顶点,直到它预测符号。对于建筑,我们只需简单地连接所有按顺序预测的顶点来获得最终的建筑多边形。就道路而言,预测的多边形本身并不需要直接使用,而是用作顶点之间的一组边缘。因此,我们使用构成多边形的所有这些单独的线段来进行进一步的处理。具体地说,每个预测段e与作为se=R01B(e(u))du∈[0,1]计算的分数se相关,其中e(u)=ue1+(11u)e2、b是中心线的热图,e1和e2是e的两端,我们删除分数段,将其余段连接起来形成整个图。
2.5 Implementation Details
我们使用F、B、V和yt的尺寸28×28设置模型参数,并将RNN的层数设置为3(建筑)和4(道路)。两种情况下训练设置为序列时的最大长度为30。建筑案例的总损失是FPN、CNN和RNN部分的总损失。FPN损失包括锚分类的交叉熵损失和锚回归的平滑L1损失。CNN损失是指边界和顶点掩码的对数损失,RNN损失是指每个时间步长的多类分类的交叉熵损失。在道路案例中,不包括FPN损失。
对于训练,我们使用Adam优化器,批量大小为4,初始学习率为0.0001,以及默认的β1和β2。我们在4个GPUs上训练了一天的建筑模型,12个小时的道路模型。在训练过程中,我们强制访问建筑多边形边缘的顺序为逆时针,而对于道路多边形,我们遵循第三节描述的一组规则。
在推理阶段,我们使用宽度为w的光束搜索(在我们的实验中是5)。对于构建,我们选择V中概率最高的顶w顶点作为起始顶点,然后是一般的光束搜索过程。在w多边形候选对象中,我们选择概率最高的一个作为输出。同样地,对于道路,我们选择图像边缘的顶点,然后选择得分最高的顶部w作为起点,并遵循一般的光束搜索算法。在预测了外部多边形后,我们可以进一步预测潜在的内部多边形(s),如第四节中所述。最后,我们在实验中使用0.7的阈值(发现可以产生良好的结果)来排除不匹配的边缘。
此外,对于从相对较大的城市开销图像中提取拓扑图,我们首先将整个图像分成几个覆盖范围为50%的补丁。在建筑脚印的训练阶段,仍使用图像边缘的不完整脚印,但在推理方案中被排除在外。在道路方面,为了得到一个完整的城市道路网络,进行了一些后处理,如在相邻的补丁中拼接道路网络,去除图的小循环以及重复的顶点和边缘。
至于效率,单个GPU上的平均推断时间为0.38s,每张图像补丁的道路为0.29s(300×300像素)。
3 结果


这篇关于PolyMapper论文简读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

