本文主要是介绍擅长捉弄的内存马同学:Valve内存马,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
内存马的文章已经很久没有更新过了, 这篇文章不太适合想直接学习利用Valve内存马的师傅
,因为我这篇文章可能会有大篇笔墨去说Tomcat容器,至于原因就是我想更深入的了解一些Tomcat,而Valve内存马属于已经被师傅们玩烂了的一种方式,并且Valve内存马的实现如果看过之前我写的内存马文章这个内存马实现起来并不难。所以与其说这篇文章是讲Valve内存马,不如说是我学习Tomcat的个人总结,废话也不多说,我们直接开始吧。
一、Tomcat基本结构
首先我们在学习内存马之前先来重新学习一下Tomcat的基本架构。我们一层一层来进行分析。

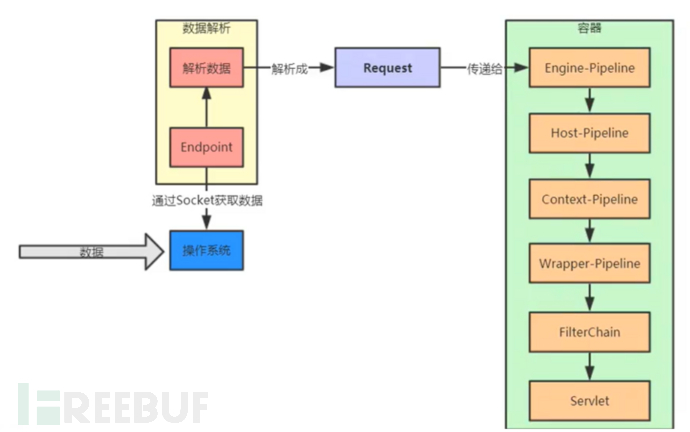
可以看到上面我搬来的这张图,这个图就将各个结构画的很简单了,当然其中的流程还有一些步骤,这里我们慢慢说。
首先我们将结构进行单独梳理:
一个Tomcat容器中只有一个Server
一个Server可以包含多个Service
一个Service只有一个Container,但是可以有多个Connectors
一个Connector会绑定一个port和protocol
接下来我们可以将Tomcat分为两个部分,一部分为Connector,另一部分为Container。分别为图中的左右两边的部分。(这块的图片我就直接贴大哥们的图了)
Connector
:顾名思义是用于接受请求并封装Request和Response,然后交给Conntainer进行处理。它使用ProtocolHandler来处理请求。
我们来说明一下它的各个部分处理流程,首先Acceptor来监听请求(前面提到一个Service只有一个Container,但是可以有多个Connectors,这是因为请求有不同的协议,但不同的协议的字节流通过不同Connectors最终都会得到统一的处理),AsyncTimeout用于检查Request超时,当接收到请求后,提交给Handler来处理接收到的Socket并将Socket字节流发送给Processor进行处理(这之中应该有一个线程池用于提高处理速度),Processor在接收到EndPoint发送过来的Socket的后将其封装成了Tomcat
Request并交给Adapter进行处理,Adapter在接收到Tomcat
Request后将其封装为ServletRequest并将请求交给Container进行适配并进行具体的请求。

Container :Container是用来处理请求的,它通过使用Pipeline-Valve(管道-
阀门)来进行处理(我们内存马就是在这之中进行添加)
我们依旧来说明一下它的各个部分处理流程,当Container接收到Adapter发来的ServletRequest请求后首先会去调用最顶层的容器(EnginePipline)的Pipline来进行处理。之后在EnglinePipline的管道中依次执行,然后到下一个Pipline,最后到StandardWrapperValve,当执行到StandardWrapperValve后,会在StandardWrapperValve中创建FilterChain并调用doFilter方法来处理请求(这里其实看过之前三个内存马文章的师傅应该比较清楚这里)doFilter方法会依次调用所有Filter的doFilter方法和Servlet下的所有service方法,到这里Tomcat就成功处理了请求。
我们通过上面的学习,大概已经简单了解到了Tomcat的基本结构,当然这结构之中的细节其实有很多,有兴趣的同学可以深入去跟一下各个位置配置读取、请求处理和处理细节等。
二、Valve基础知识
在我们刚才的学习中已经了解到了Valve在Tomcat中所处的位置,我们的Valve实际上属于自定义Valve的位置当中,当然,在我们学习之前,我们先简单了解一下Valve的基础知识。
对于Valve的定义,其实我们通过上面的学习应该已经知道了Pipeline-Valve机制就是Container是用来处理请求的方式。
Valve:
译文为阀门,在Container的四个容器类(StandardEngine、StandardHost、StandardContext、StandardWrapper)中都有一个PipeLine和多个Vavle,和我们之前上面分析Container的图一样,而Valve顾名思义就是像阀门一样来控制我们管道当中的水流,。
在PipeLine生成时,同时会生成一个缺省Valve实现,就是我们在调试中经常看到的StandardEngine、ValveStandardHostValve、StandardContextValve、StandardWrapperValve,当各个容器类调用getPipeLine().getFirst().invoke(Request
req, Response resp)时,会首先调用用户添加的Valve,最后再调用缺省的Standard-Valve。

注意,每一个上层的Valve都是在调用下一层的Valve,并等待下层的Valve返回后才完成的,这样上层的Valve不仅具有Request对象,同时还能获取到Response对象。使得各个环节的Valve均具备了处理请求和响应的能力。
三、Valve简单实现
首先我们去看一下valve的接口
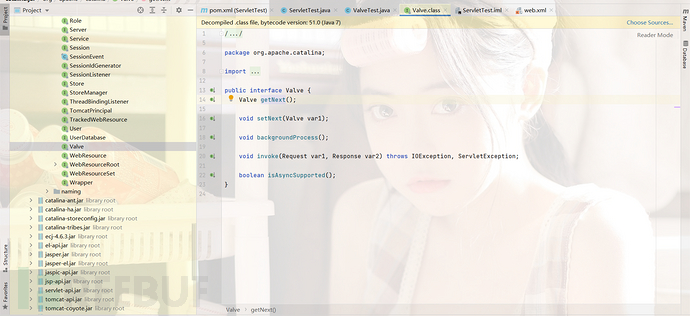
getNext方法是获取当前这个责任链节点的上一个节点。
setNext方法是设置当前这个责任链节点的上一个节点
invoke方法是逻辑处理位置
isAsyncSupported方法是表示是否支持异步
接下来我们写一个类,实现这个接口。
 然后我们在server.xml配置文件中配置一下我们自定义的Valve
然后我们在server.xml配置文件中配置一下我们自定义的Valve
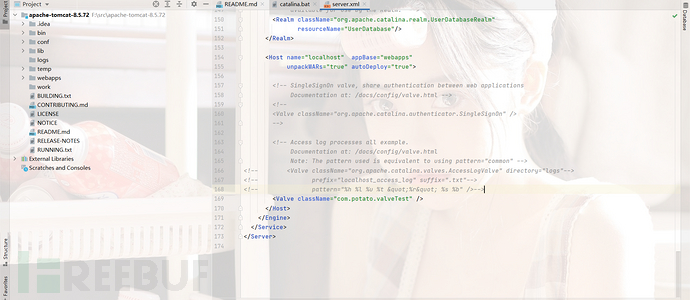 然后我们运行tomcat,最简单实现了这个功能
然后我们运行tomcat,最简单实现了这个功能
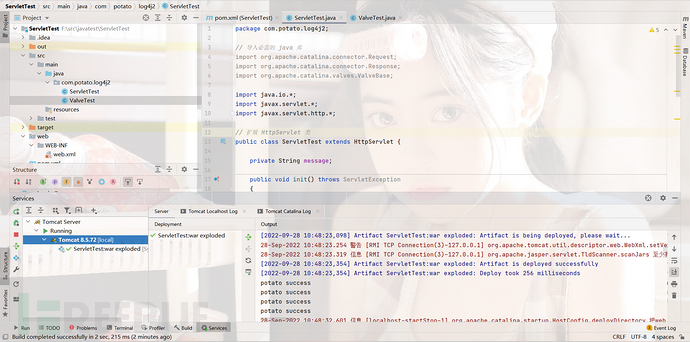
到这里就出现了一个问题,我们所有的请求走到我们自定义的valve后就断了。这是因为valve的动作定义在invoke中,通过调用this.getNext().invoke(req,
resp)将请求传入下一个valve构成了pipeline管道,如果我们不调用下一个的invoke请求到此中断,所以我们这么写是没调用到下一个invoke请求的,所以我们一般不采取实现valve接口的方法,而是选择继承ValveBase类来简单实现了valve接口,制作一个简单的valve基类。我们继承一个ValveBase来实现valve接口,接下来还是按上面的步骤来一遍。


四、Valve加载流程(Tomcat启动流程)
我们通过简单实现一个Valve,可以知道我们是通过在server.xml中设置了一个Valve,从而实现了自定义的Valve,但是Tomcat是如何读取并加载我们自定义的Valve信息的呢,接下来我们就从Tomcat的启动流程开始分析我们是如何加载我们自定义的Valve的。
首先我们先要了解一些基础知识,Tomcat启动的简单流程如下图

所以我们Tomcat是从Bootstrap开始运行的,我们跟到Tomcat的入口点开始分析,也就是Bootstrap的main方法,如下图所示,首先Bootstrap进行了实例化、初始化操作,然后调用daemon的load方法和start方法,我们直接跟进load方法。
(1)bootstrap启动流程



(2)Catalina.load()初始化操作
进入load方法,这一块我们通过反射调用了Catalina的load方法,我们继续向下跟进

(3)Digester解析server.xml
里我就不再多做赘述了,大家可以去自学一下。我们首先执行了this.createStartDigester(),这一步一句话概括就是将server.xml中的pattern、rule信息放入了cache中,将rule信息放入了rules中,当返回给digester.parse进行解析的时候,读取的节点规则信息都放到了rules下面。


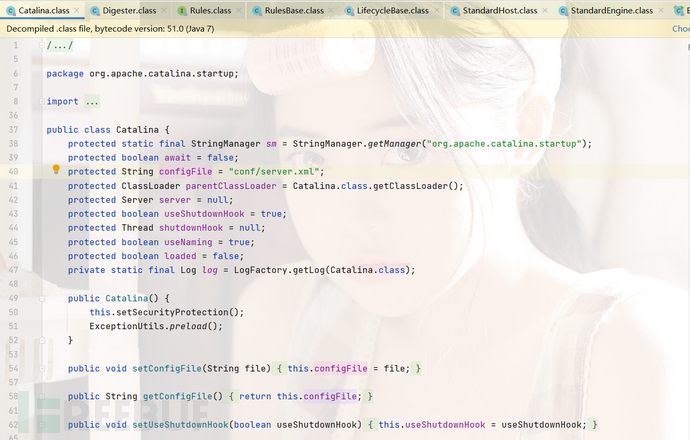
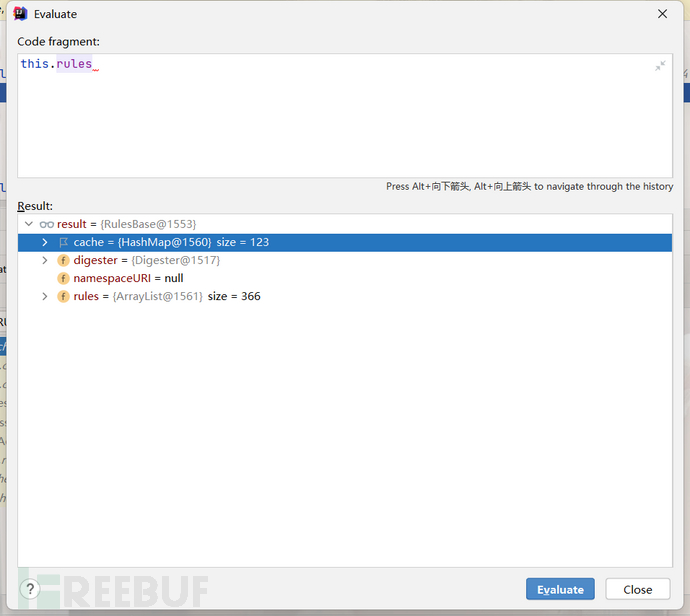
当我们将节点和规则都设置完毕后,开始执行digester.parse对其开始进行解析操作,这一步实际上就是将Tomcat各组件都实例化出来(这里面其实Context比较特殊)

这里的parse的执行太多了,我就不一个一个进行跟进了,我们直接跟到解析我们自定义Valve的位置上,首先我们看一下之前的定义,可以看到匹配到/Host/Valve节点的时候最终是去触发了addValve方法(这里的匹配Object是standardHost)。
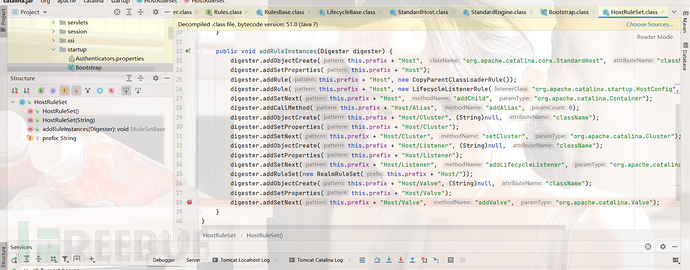
然后我们跳到解析到这个节点的位置上去,进入ContainerBase中,最终执行this.pipeline.addValve(valve),我们进行跟进


我们向下最后跟进到了StandardPipline.addValve(),这里其实就相当于按照容器作用域的配置顺序来组织valve,将每个valve都设置了指向下一个valve的next引用。我们继续向下。
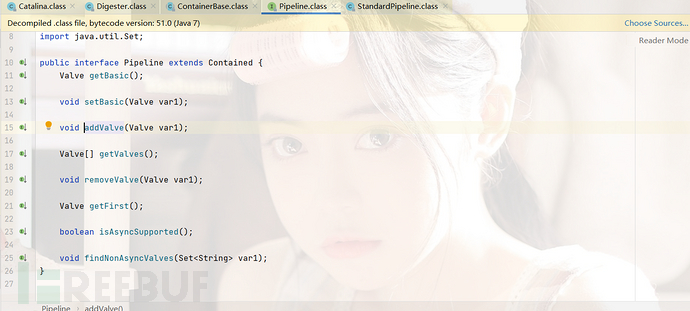
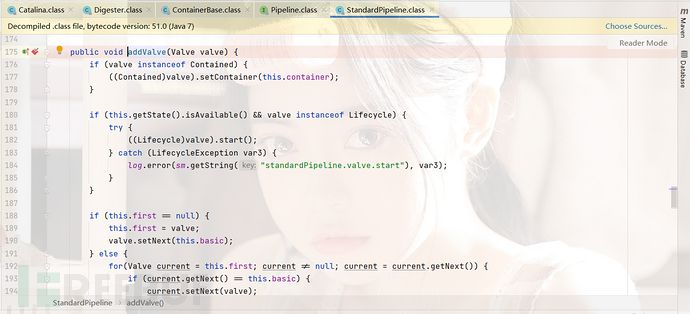
我们回到Catalina然后继续向下查看,我们走到了Server初始化的位置this.getServer().init()接下来我们就快速过一下容器初始化和启动的流程然后直接到Valve的位置。

接下来就是进行JMX注册Mbean,jmx这块大家玩的应该也比较熟了,然后接下面开始循环调用service.init(),对service进行初始化,我们进去查看一下

这里对engine进行了初始化操作接下来初始化Executor线程池、Connector连接器,最后结束。



(4)Catalina.start()启动操作
到这里可能就有一些疑问了,初始化了sever、service、engine正常来说是不是应该继续初始化Host、Context、Wrapper巴拉巴拉的了,但是到了engine这里就结束了,这是为什么啊。这个的原因就是:我也不知道,但是在start方法中进行了Host组件的初始化然后进行的启动操作,所以我们回到Bootstarp去查看start方法。
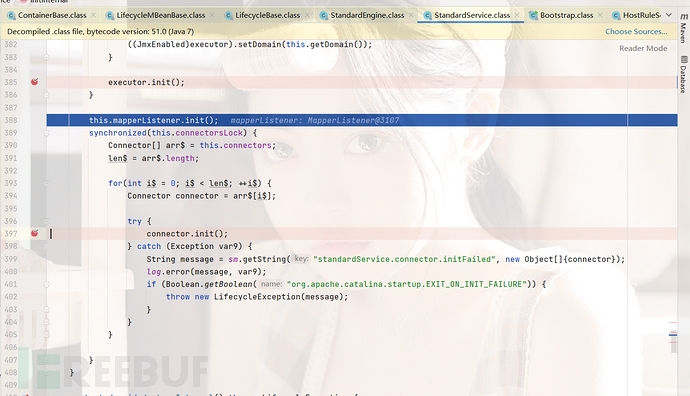
回到Bootstarp,进入start方法
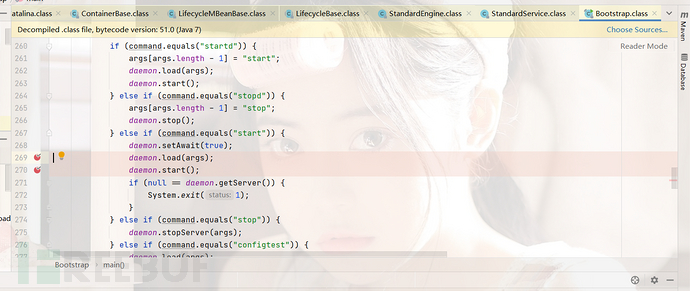
这里我们可以看到一路向下将我们的初始化的容器都进行了启动操作,最后我们跟到了this.engine.start()下面

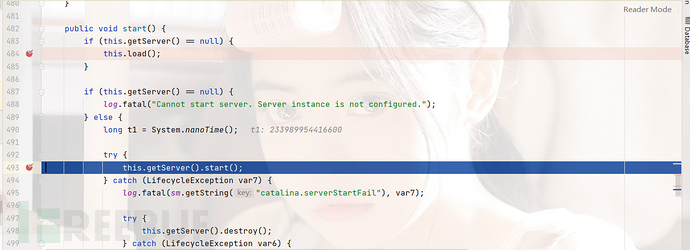
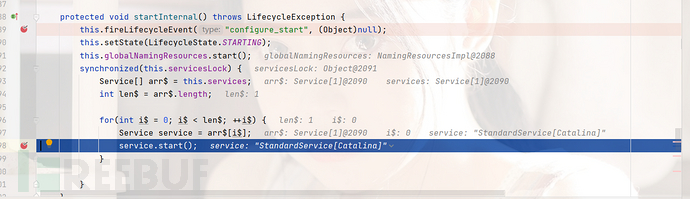
我们进入this.engine.start()下面可以看到它,将子组件到children中,接下来托管给线程池处理。我们跟到这个下面。


进入sumbit,这里其实就是用到了FutureTask传入一个Callable实现,通过线程池去达到异步执行,流程就如下图所示。可以看到这里将FutrueTask的state设置为了NEW,这里的state为以下几个状态
NEW:表示一个新的任务,初始状态
COMPLETING:当任务被设置结果时,处于COMPLETING状态,这是一个中间状态。
NORMAL:表示任务正常结束。
EXCEPTIONAL:表示任务因异常而结束
CANCELLED:任务还未执行之前就调用了cancel(true)方法,任务处于CANCELLED
可能的状态过渡:
1、NEW -> COMPLETING -> NORMAL:正常结束
2、NEW -> COMPLETING -> EXCEPTIONAL:异常结束
3、NEW -> CANCELLED:任务被取消
4、NEW -> INTERRUPTING -> INTERRUPTED:任务出现中断
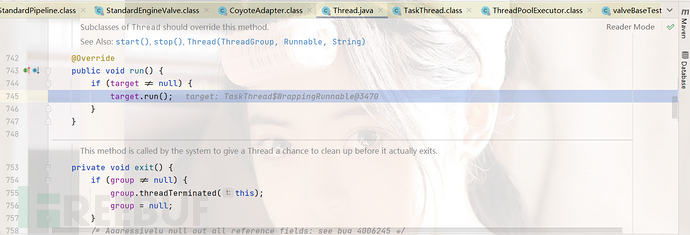
接下来外面就正常执行,跳转到run()下面,我们跟到这个位置




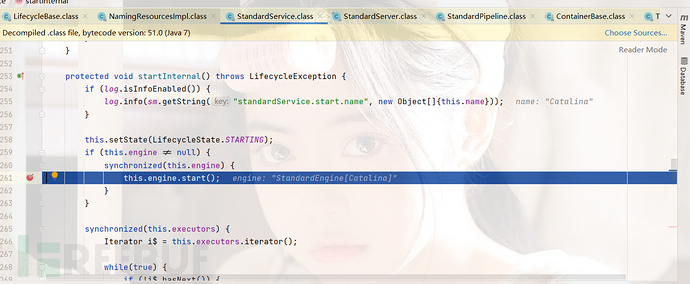
跟进run方法,我们状态为NEW,随后触发call方法,我们跟进call方法
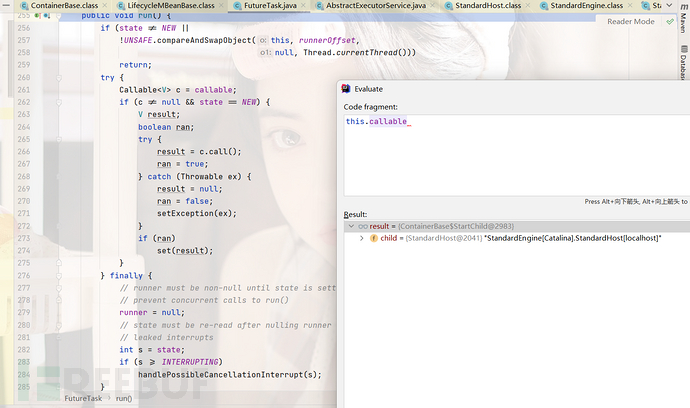
进入call方法,我们来到了ContainerBase下面可以看到,我们执行了this.child.start(),到这里我们就执行了start()方法,我们继续一路向下


到这里我们总算是回到了生命周期的位置,而在这里我们开始了执行了init()和start(),这里其实就是就是上面我们所说的区别,我们的Server、Service、Engine都是先在init()中进行初始化,然后在start()中进行启动的,但是Host直接先初始化后运行了。这里的初始化我们简单跟进去看一下吧,实际上也没初始化啥玩意,就是在jmx里注册一下子。我们回到生命周期去执行startInternal()





跟进startInternal(),这里我们看到了,到这里其实就是在添加一些Valve,然后就去执行父类ContainerBase的startInternal方法了


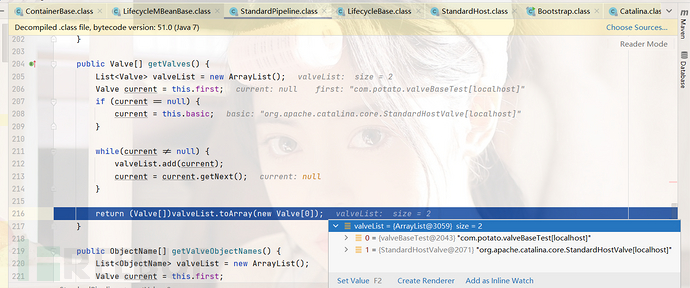
五、Tomcat责任链处理流程
关于Tomcat的启动流程到Host这里我们就不在继续跟进去了,继续向下说的话就要说到我们之前的内存马文章读取configcontext那块了((*_)),跟到了这块的我们应该已经能清楚地了解到Tomcat是如何从自定义的server.xml中读取加载并最终将Valve存储到Standard中的了,接下来我们就从责任链这块都执行了什么。
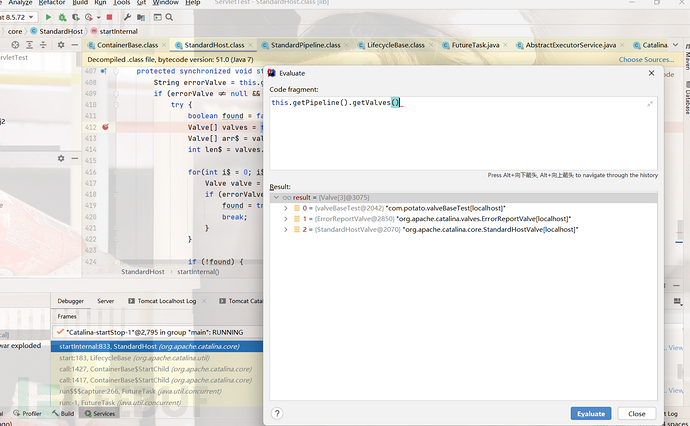
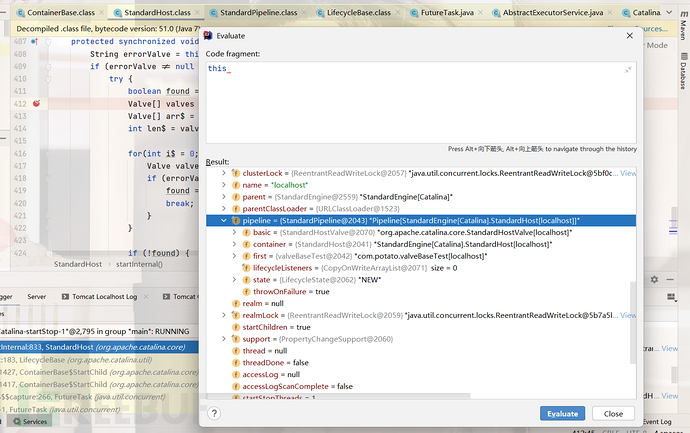
我们直接来到梦开始的位置-从线程一路向下
我们来到了Adapter的文章,从这里开始我们将从connect过来的请求交给最顶层的pipline来处理也就是EngineValve没有我们自定义的Valve直接到了StandardEngineValve。

到了这里继续交给StandardHost的pipline,通过之前我们跟进的启动流程,我们可以清楚的知道first为我们自定义的Valve,直接跳到我们的Valve
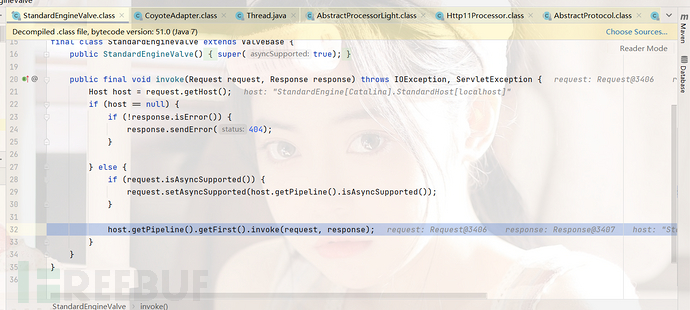
所以我们就直接到达了我们的Valve下面喽,结果就是成功证明了potatosafe is trash
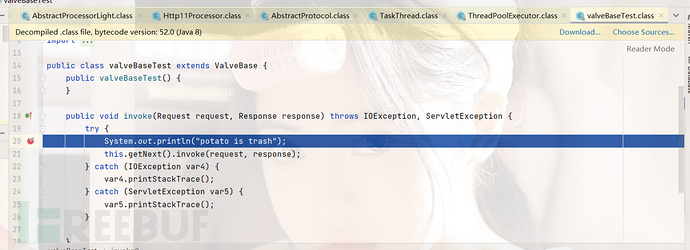
六、Valve内存马思路
其实跟到了这里,Valve内存马其实对我们来说就属于清晰易懂的东西,如果单纯去实现内存马的话,对于看到这个的师傅们应该就很简单了,这里我们就梳理一下思路。
我们回忆一下,我们在分析Tomcat启动流程的时候在两个位置添加过valve(我们分析的是Host),一次是在解析server.xml的时候添加了我们注册的Valve,另一次是在Host启动过程中添加了一些Valve,如下图所示

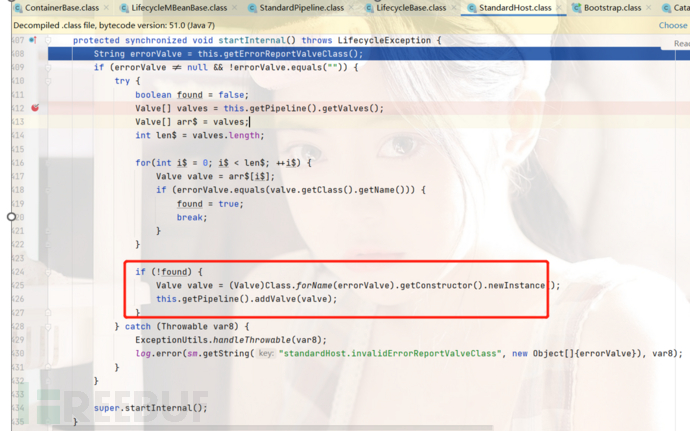
他们都通过this.getPipeline().addValve(valve)进行添加操作,所以我们也按照这个方式进行添加就OK的了,换句话说我们只要能过获取四个容器的其中一个standard,就可以通过当前容器的pipeline直接进行添加操作,添加流程如下:
1.构造一个恶意的Valve
2.通过线程获取standrad
3.通过Standard获取当前容器的Pipeline
4.添加Valve内存马
这里注意添加一下this.getNext().invoke(request, response);防止影响业务,接下来我们就实现一下.
七、Valve内存马实现
首先我们构造一个测试的demo

接下来就是常规操作了,大家这里建议自己去实现一下,和前面的差不太多。这里我搭建一个shiro的测试环境(这里我把头长度限制去掉了)
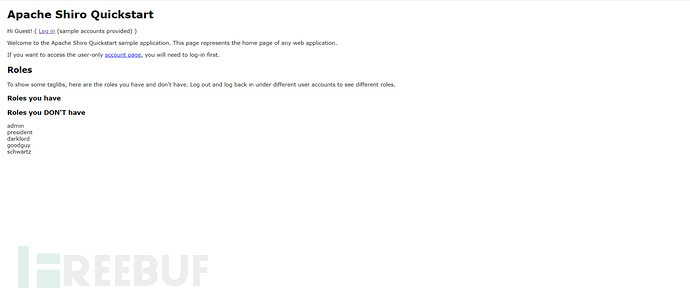
然后我们搓一个shiro反序列化打进去

然后重新访问页面,成功触发
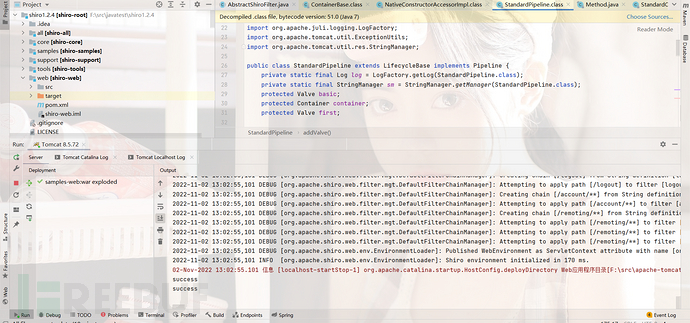 接下来我们和之前的文章一样打一个冰鞋进去
接下来我们和之前的文章一样打一个冰鞋进去
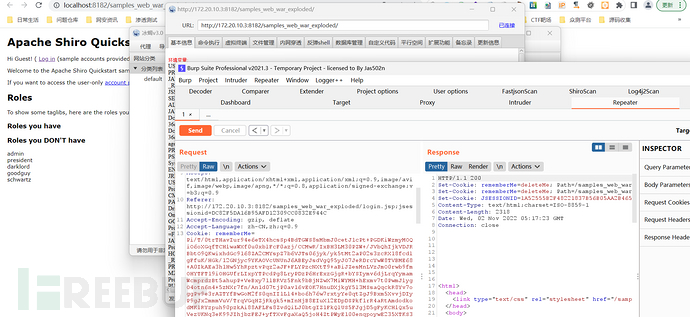
成功连接冰鞋马,也没有影响业务请求,成功实现。
最后
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

因篇幅有限,仅展示部分资料,有需要的小伙伴,可以【扫下方二维码】免费领取:

这篇关于擅长捉弄的内存马同学:Valve内存马的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




