本文主要是介绍利用python第三方selenium库爬取QS大学排名,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
众所周知QS全球大学排名是全球最具权威性,和影响力的大学排名榜之一。今天我就来分享一下用Python爬取QS大学排名的过程。
首先看一下要爬取的QS大学排名的网址:
url = "https://www.topuniversities.com/university-rankings/world-university-rankings/2018"如果用requests库爬取的话,获取的源代码是不完整的。由此我们也可以知道这个要爬取的网页是动态网页,因此可以选用selenium库进行爬取。使用selenium库的话,我们要提前安装好selenium库,并安装好浏览器驱动,且将其添加至系统环境变量中。
第一步:获取源代码
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
# 定位‘All’元素
option = driver.find_element_by_xpath('//*[@id="qs-rankings_length"]/label/select/option[5]')
# 模拟鼠标点击,点击 ‘All’
option.click()
time.sleep(3)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
# Waitting for html5 page loading
# get page source code
time.sleep(5)
html_src = driver.page_source从上面的获取源代码的函数中,我们可以看到一个option.click(),这是一个模拟鼠标点击的动作。目的是让大学排名全部显示出来,这样获取源代码就会简单多。下面看一下当时的网页:
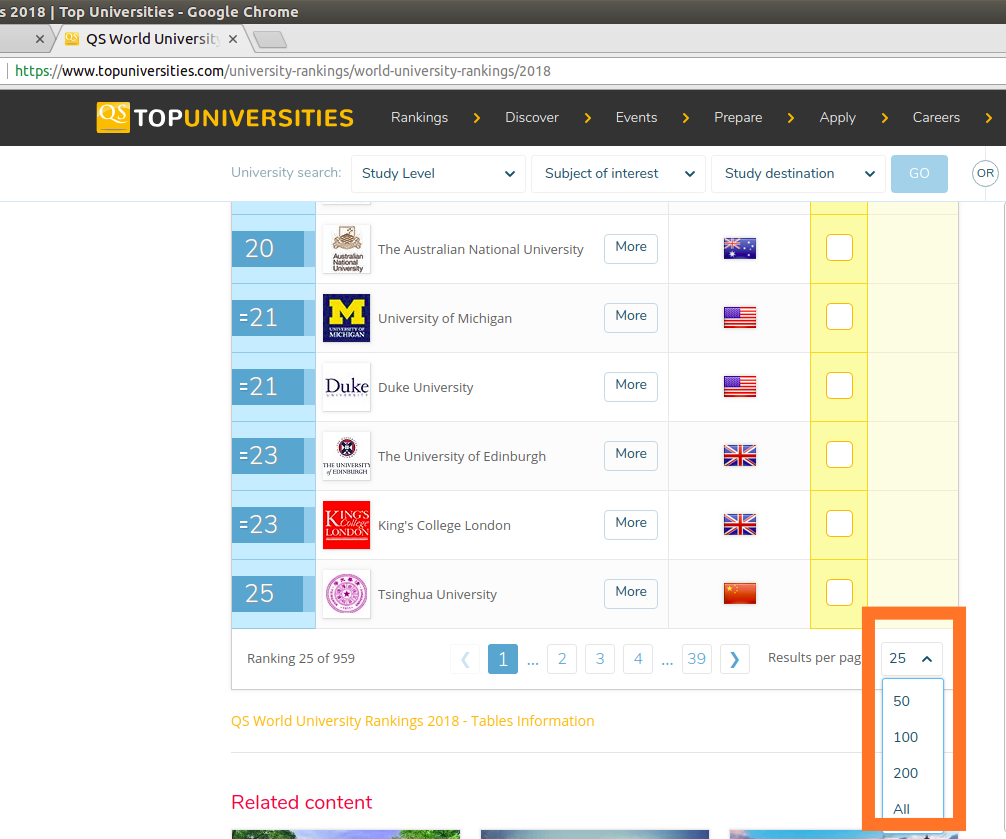
为了让大学排名全部显现出来,就需要点击 “All”。为了让大家更加明白上面的代码,我在Python console中分别执行上面代码中的几段重要的代码,然后再分别查看一下现象。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.topuniversities.com/university-rankings/world-university-rankings/2018')
此时,我们会看到:
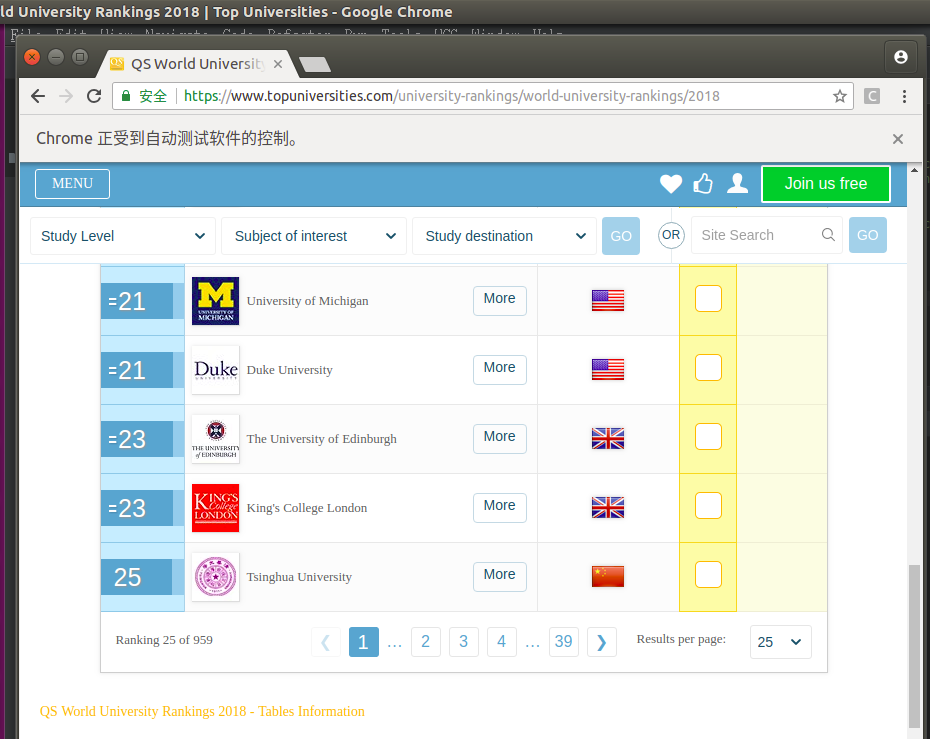
可以看到每页的结果还是 25。接着执行:
span = driver.find_element_by_xpath('//*[@id="qs-rankings_length"]/label/span[2]/span[1]/span')
span.click()这一步我用selenium模拟了鼠标,点击了数字 25 所在的区域。于是就出现了:
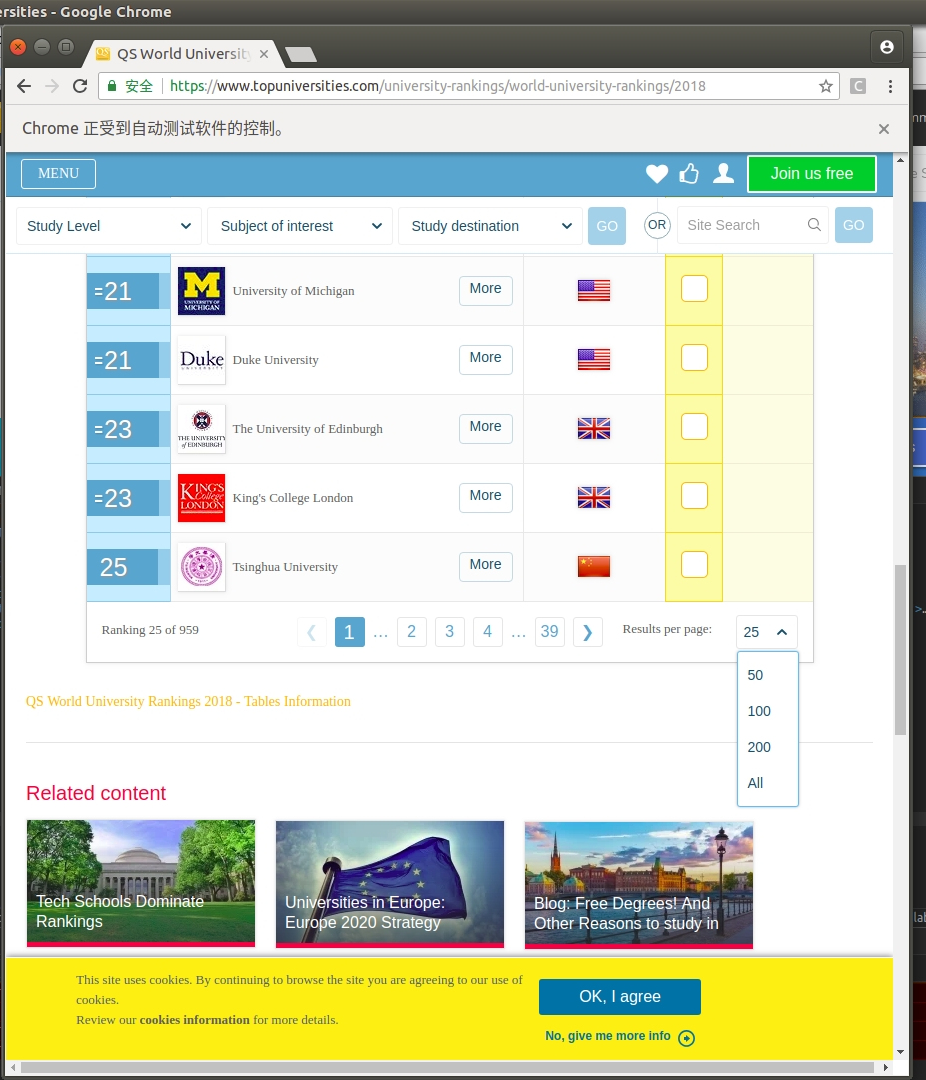
然后定位到 “All”所在的位置,点击一下即可。
# 定位'All'元素
option = driver.find_element_by_xpath('//*[@id="qs-rankings_length"]/label/select/option[5]')
# 点击
option.click()
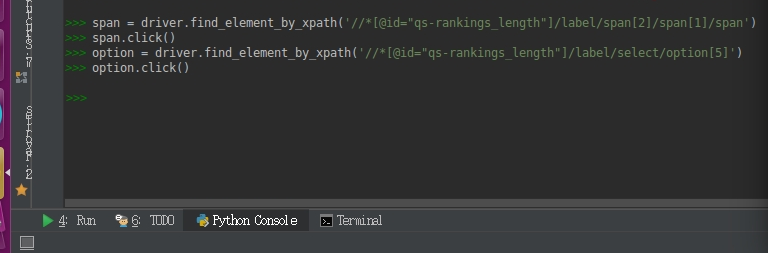
这里用driver.find_element_by_xpath()这个方法来查找元素位置,它的具体操作方法是:
光标置于网页元素位置处----鼠标右键,检查元素----点击选中这行----右键----copy----copy XPath
执行后所有的大学排名便会显现出来:
# 获取网页源代码
html_src = driver.page_source
第二步:解析网页
这里可以定义一个解析函数parser_html_page(html), html是第一步中获取到的网页源代码。
def parser_html_page(html):soup = BeautifulSoup(html, 'html5lib')p_length = eval(soup.find('span', 'cp').string)# get universities namespattern2 = '<a class="title" href=".*?">(.*?)</a>'nui_ls = re.findall(pattern2, html)# get the country namespattern3 = 'data-original-title="(.*?)"'country_ls = re.findall(pattern3, html)# return the three lists# p_length 是参与排名的大学数量return nui_ls, country_ls, p_length第三步:将数据写入到本地
定义一个写入函数write_file(), 写入模式为 ‘a’。
def write_file(ls1, ls2, ls3, length):# path 是文件存储路径with open(path, 'a') as f:for i in range(length):f.write(str(ls1[i]) + ' ' + str(ls2[i]) + ' ' + str(ls3[i]) + '\n')f.close()最后定义一个主函数将三个函数的功能合并起来:
def main():url = "https://www.topuniversities.com/university-rankings/world-university-rankings/2018"html, ls1 = get_html_page(url)ls2, ls3, length = parser_html_page(html)write_file(ls1, ls2, ls3, length)调用主函数:
if __name__ == "__main__":main()最终得到的QS大学排名结果:
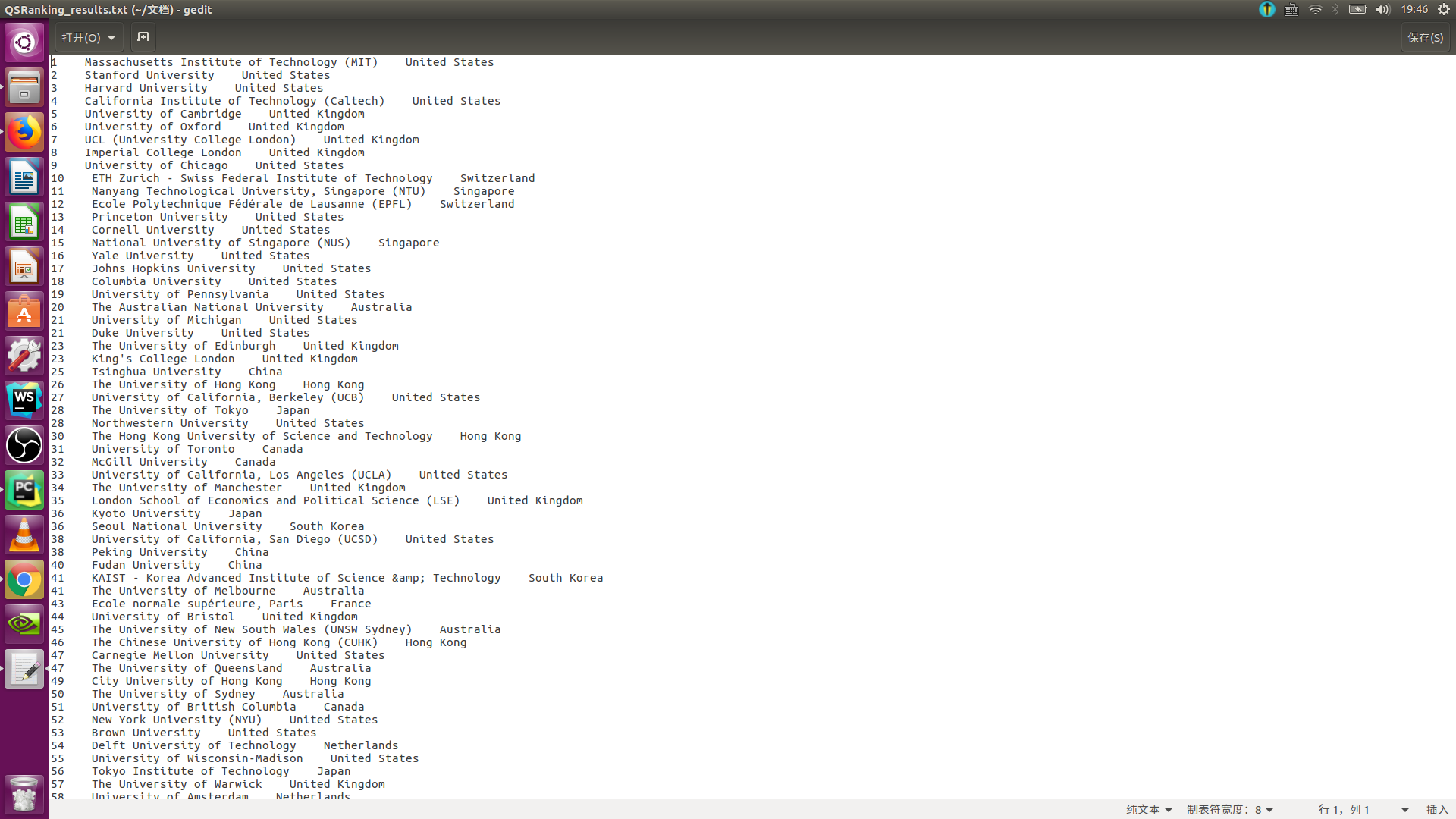
这样爬取QS大学排名的Python爬虫就完成了。
完整的python爬虫代码
这篇关于利用python第三方selenium库爬取QS大学排名的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







