本文主要是介绍白鳝:聊聊IvorySQL的Oracle兼容技术细节与实现原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
两年前听瀚高的一个朋友说他们要做一个开源数据库项目,基于PostgreSQL,主打与Oracle的兼容性,并且与PG社区版内核同步发布。当时我听了有点不太相信,瀚高的Highgo是在PG内核上增加了一定的Oracle兼容性的特性,一般也会比PG社区版慢上几个版本,如果他们开源这么个数据库产品,会不会影响Highgo的发展。虽然我对瀚高投资开源数据库表示一些担忧,不过IvorySQL社区还是发展起来了,前几天还正式发布了3.0版本,在GITHUB上也获得了630+ STAR,在墨天轮国产数据库热度榜上排名136,排在中游偏上的水平。一个开源产品做到3.0版本,应该算是进入比较良性的阶段了。
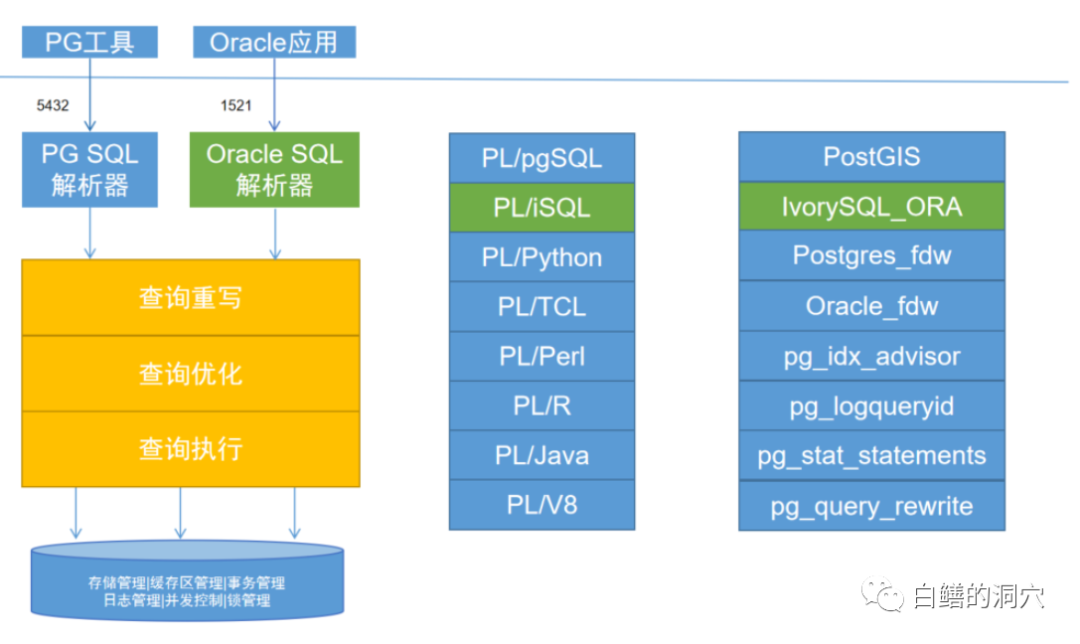
在SQL引擎上,IvorySQL采用了一种特殊的双解析器模式,对于Oracle兼容模式和PG兼容模式分别有独立的解析树。大部分国产数据库产品对于Oracle数据库兼容的方法是在语法解析器中增加Oracle兼容的语法,而不是这种方式。IvorySQL这样设计的好处是Oracle兼容解析器的发展与PG解析器的发展是独立的,相互的影响较小。
通过分离解析器还有一些其他的好处,首先解析器的复杂度降低,隔离故障,更不容易出错。另外当PG升级时可以直接使用开源社区的原生解析器,不需要考虑Oracle语法的变化,Oracle语法变化时,也不会影响PG解析器,只需要独立升级就可以了。不过这么做也有一点不好的地方,那就是不能混搭使用PG和ORACLE语法。对于大多数应用场景而言,目前必须融合二者需求的需求并不多。
在Oracle数据库向IvorySQL迁移之时,IvorySQL的Oracle SQL解析器可以帮助用户降低迁移工作的难度,加快迁移速度。系统今后升级后,系统可以逐步兼容PG语法 ,从而慢慢平移到PG SQL解析器上。IvorySQL通过PL/iSQL插件实现与Oracle PL/SQL过程语言的兼容。PL/iSQL不仅支持存储过程,还支持匿名块等Oracle专用语法。
半个月前,IvorySQL的同学问我有没有兴趣试试他们马上要发布的V3.0版本,据说与2.x版本相比,在与Oracle兼容性方面有了较大的增强。对于测试数据库产品,我向来是比较有兴趣的,更何况是一个与Oracle有相当兼容性的PG数据库产品。
与原生态的 PG相比,IvorySQL的部署还是略微复杂一些的,需要安装一些依赖包。因为对Python的LIB库版本有要求,因此我刚开始在公司实验室已经安装了无数PG类国产数据库的环境中的安装部署没有成功,因为里面冲突的依赖库太多了。因此我就改为在笔记本电脑的wsl 环境中体验了。在一个干净的CentOS7环境中,部署起来还是很顺利的。
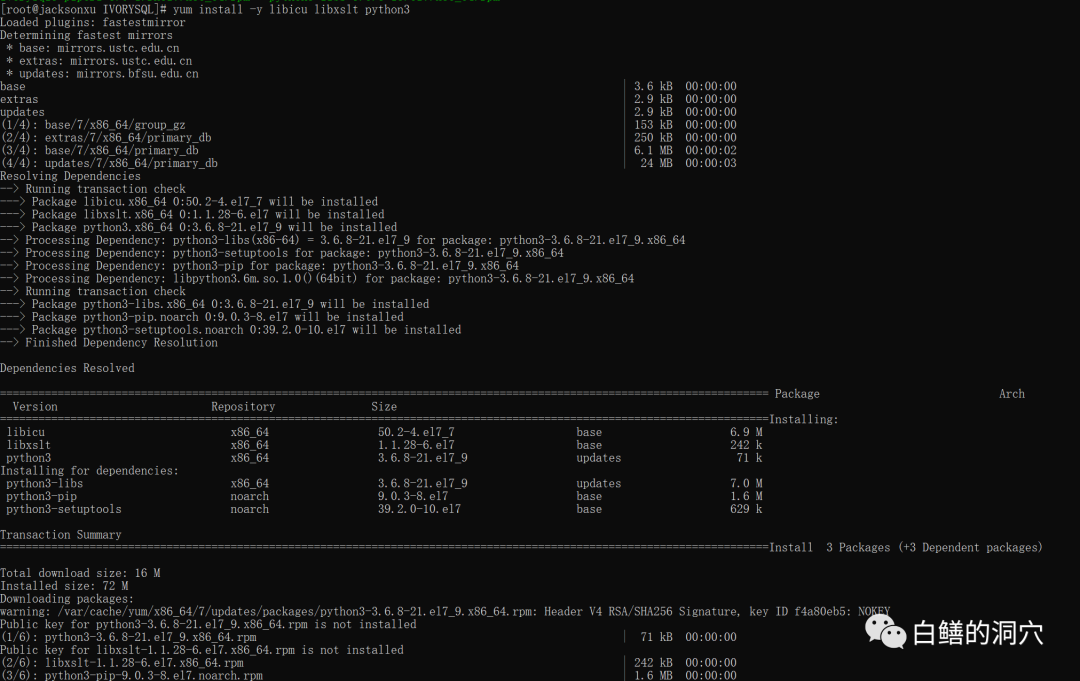
首先yum install -y libicu libxslt python3安装Python3和libicu、libxslt等依赖包。然后就可以安装IvorySQL提供的各种安装包了。

顺次安装ivorysql3-libs-3.0-1.rhel7.x86_64.rpm、ivorysql3-3.0-1.rhel7.x86_64.rpm、 ivorysql3-contrib-3.0-1.rhel7.x86_64.rpm、ivorysql3-server-3.0-1.rhel7.x86_64.rpm,一分钟齐活。对于RPM安装,安装文档中的创建ivorysql用户和用户组是不需要的,实际上安装ivorysql3的时候,这些都已经自动创建了。设置好环境变量后就可以直接初始化数据库了。
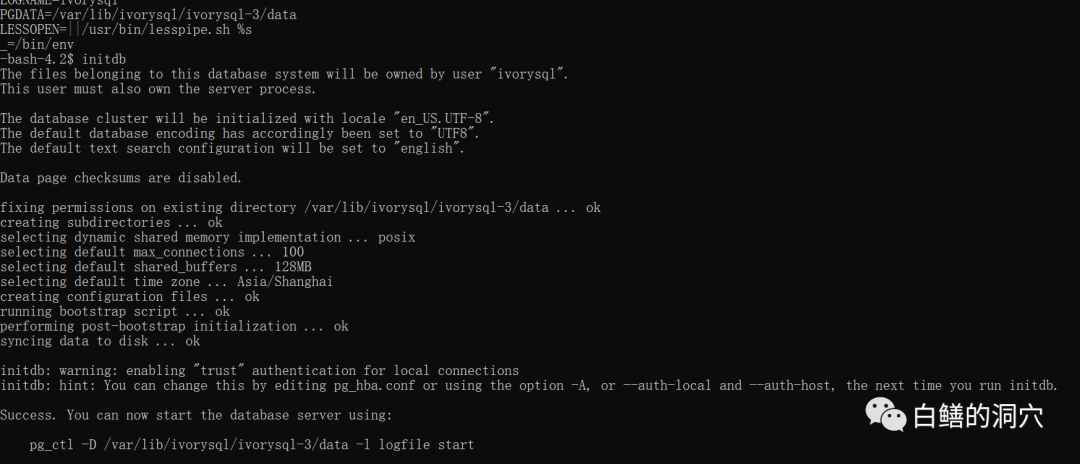
从安装的体验来说,虽然安装包比较多,而且Python3对环境的依赖包有些要求,不过在一个全新的CentOS7环境上安装还是比较丝滑的。接下来我们来初步体验一下IvorySQL的功能。

我们首先来体验一下PG兼容模式,这里我们遇到了一个小BUG,连接IvorySQL数据库默认的数据库是ivorysql,不过当前的IvorySQL 3.0BETA版initdb的时候只创建了postgres数据库,没有创建ivorysql数据库。我想3.0正式版中这个问题应该很容易解决。
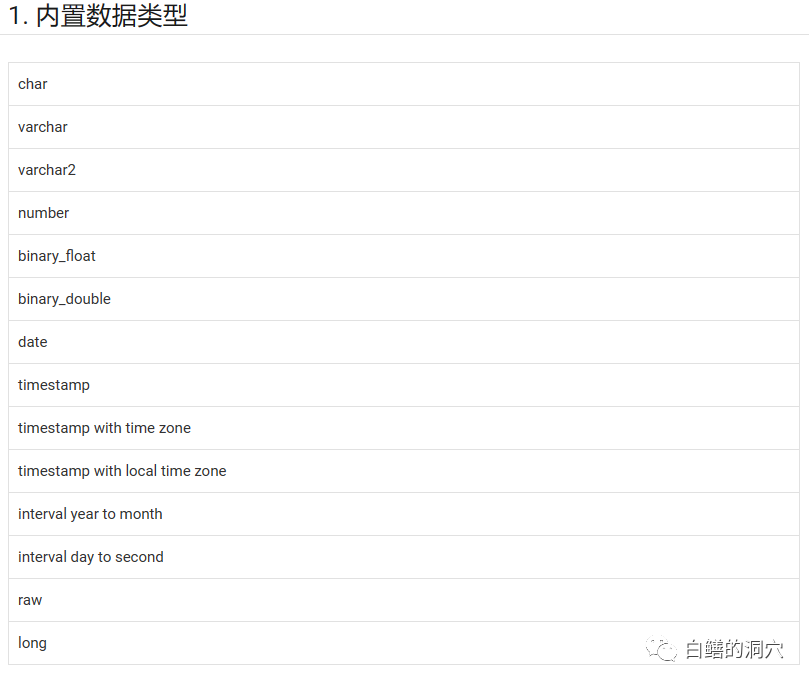
目前IvorySQL支持大多数的Oracle数据类型,不过好像目前还不支持LOB/CLOB之类的大字段。不过我们可以在建表时使用PG存储BLOB的模式来存储LOB字段。
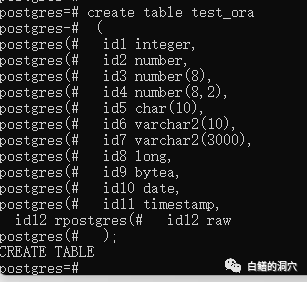
以PG兼容的端口号登录数据库,可以看到IvorySQL对待Oracle兼容模式的数据类型方面,采用的是一种混合策略,如果数据类型与PG完全兼容,则用PG原生的类型,如果类型与PG不完全兼容,则使用新创建的数据类型。
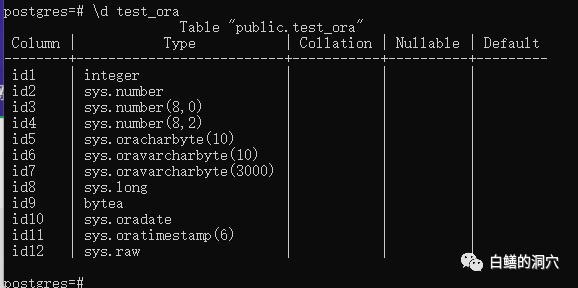
我们再来看看在PG兼容模式下创建的表。
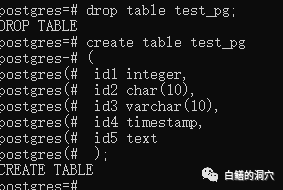
在Oracle兼容模式下我们来看看刚才这张表是如何表示的。

PG与Oracle在数据类型方面存在一定的差异,因此要拉平两种模式的数据类型,还是需要一个比较适当的策略的,并不是直接做成兼容就可以的,因为精度和访问特点还是有很大的差异的,在双模式下,如果强行拉平可能会引入很多BUG,我猜测这可能是当前IvorySQL采用此种策略的原因。当前的策略可以接受,不过是不是还可以做得更好一些呢?希望随着新版本的出现,这方面会给我们更多的惊喜。
下面我们测试下在PG兼容模式下是否具有Oracle兼容性支持的特性。用5432端口登录IvorySQL后,执行一些Oracle特有的匿名块和查询sysdate等操作。
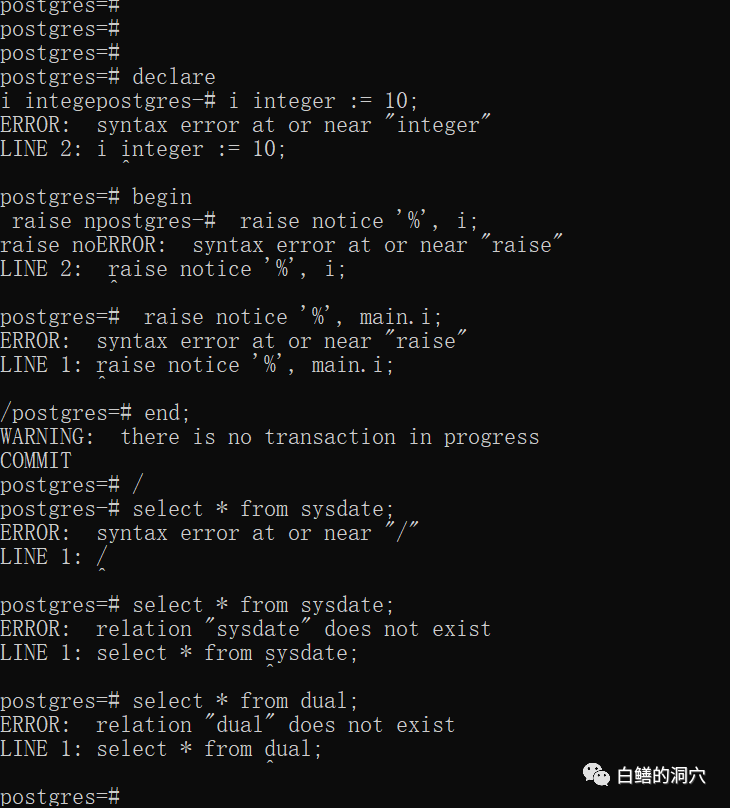
从上面的结果可以看出,标准的PG兼容端口登录数据库的时候,是不支持Oracle语法的。
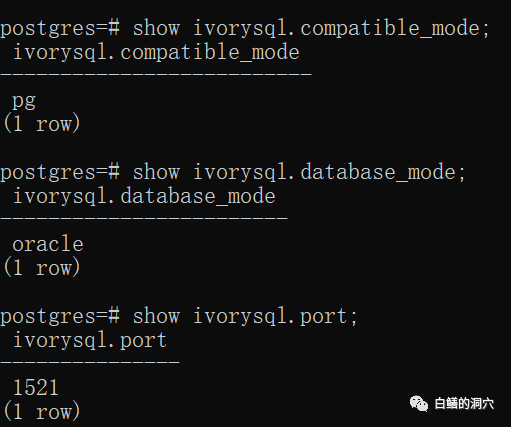
可以看出当前这个数据库的兼容模式是pg模式,数据库模式是oracle模式,说明当前的数据库是可以使用Oracle兼容模式去访问的。IvorySQL的database_mode有Oracle、PG两种数据库模式。PG数据库模式不能使用Oracle兼容模式访问,而oracle数据库模式可以通过PG或者Oracle兼容模式访问。Oracle兼容模式的端口是1521。
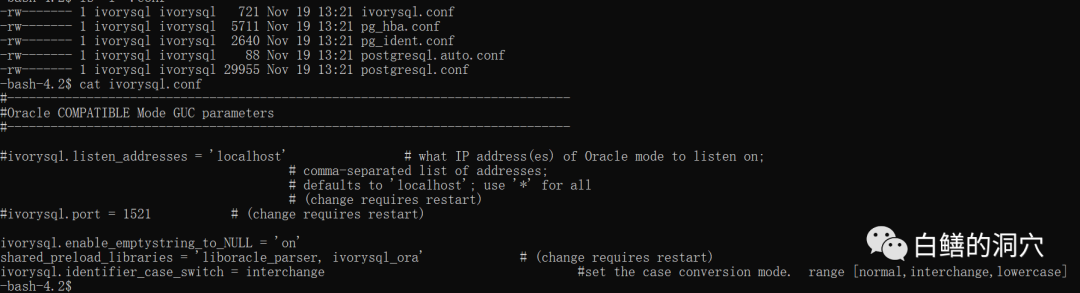
IvorySQL在原有PG的配置文件的基础上,新增了一个ivorysql.conf配置文件。这个文件中可以配置Oracle兼容模式的端口以及一些兼容性的配置。shared_preload_libraries = 'liboracle_parser, ivorysql_ora',从这一行配置中,我们可以看出liboracle_parser和ivorysql_ora是实现Oracle兼容性的关键组件,其代码在src/backend/oracle_parser目录下。
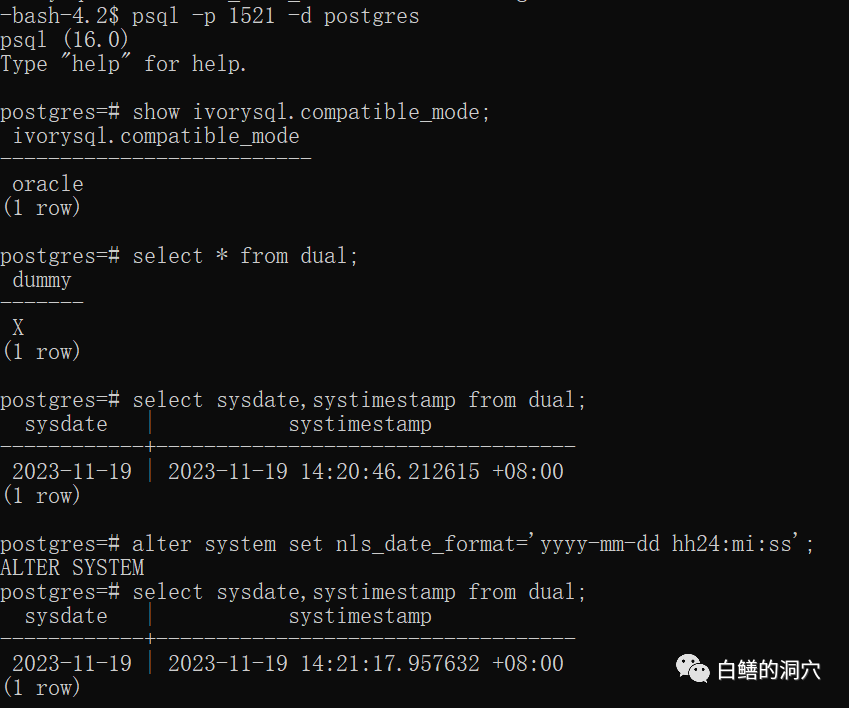
通过Oracle 兼容模式的1521端口登录数据库,可以看到兼容模式已经是Oracle了。下面我们来看看Oracle兼容模式和Oracle到底兼容到什么程度。似乎sysdate,dual等Oracle语法都不报错了。连设置nls_date_format都不报错,不过似乎没有起作用。

不过从Ivy_guc.c里是能看到Oracle的这个参数的,难道是遇到BUG了吗。后来仔细一想,原来是许久没有怎么好好用Oracle,都有些忘记了。修改会话的NLS参数使用alert session不能用alter system。

这回对了,而且连时间计算与Oracle的兼容性也很不错。

在内置数据类型与内置函数方面,IvorySQL的支持还是不错的,大部分应用中比较常用的语法和函数都支持了。

在SEQUENCE兼容性测试上我遇到了一个小问题,创建语法是可以兼容的,不过使用的时候目前还不支持Oracle的Nextval语法,用PG的nextval函数是可以正常使用SEQUENCE的。经过与IvorySQL的同学交流也确认了这方面的兼容还没有正式开放出来,希望今后IvorySQL能在后续版本中提供支持,毕竟Sequence也是应用中最常用的 功能。
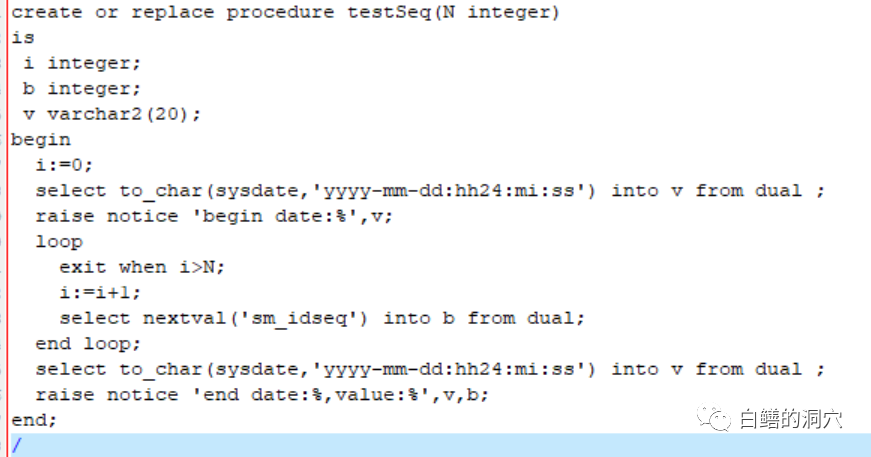

因为兼容性问题,我不得不对存储过程做一些针对PG语法的修改。修改后一个类似Oracle存储过程的PL/iSQL存储过程按照预想的跑了起来。因为兼容性问题,我只能通过 select to_char(sysdate,'yyyy-mm-dd:hh24:mi:ss') into v from dual ;给v赋值,而不能像Oracle的PL/SQL那样直接写v:= to_char(sysdate,'yyyy-mm-dd:hh24:mi:ss')。经过和IvorySQL的同学沟通,目前PL语法方面还在继续改进,目前还不支持直接使用SQL中的内置函数。
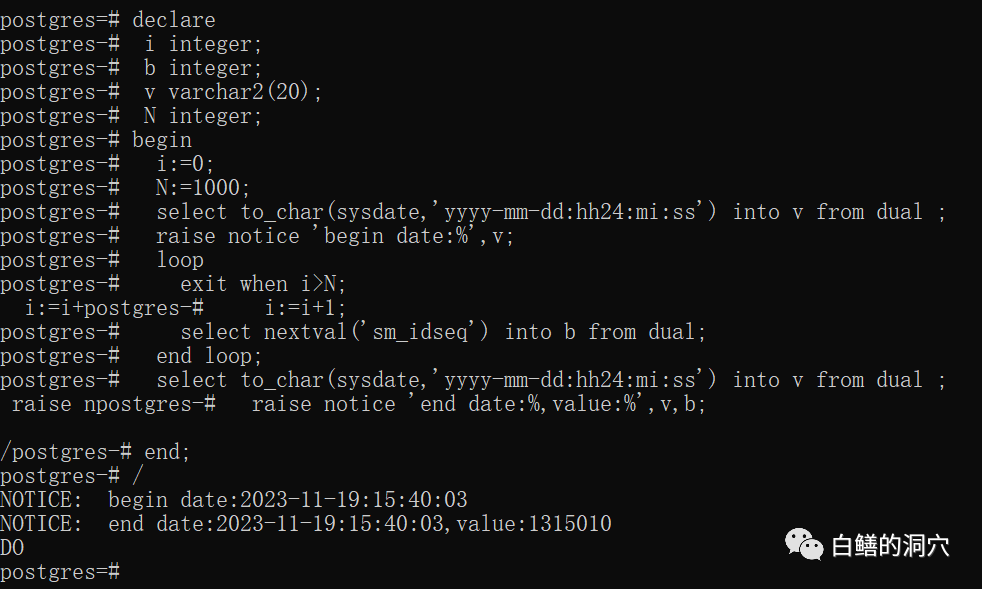
对于PL/SQL兼容方面,这回IvorySQL把匿名块的语法也同时安排上了。匿名块在Oracle应用里还是有着广泛的应用的,我们的D-SMART在做数据库指标采集的时候,对于支持匿名块的数据库,优先使用匿名块的方式,这样可以减少RDBMS SERVER与客户端的网络交互,提高应用的效率。
这两天初步体验了一下IvorySQL,比起原生态的PG来,IvorySQL在Oracle的兼容性方面还是可圈可点的。目前的国产开源数据库产品也有不少了,不过提供对Oracle支持的还是比较少。大部分国产数据库企业都把与Oracle兼容的特性都放置到了商用版之中。IvorySQL在这方面还是诚意满满的,希望随着版本的迭代,瀚高会将越来越多的Oracle 兼容特性开放到IvorySQL中。IvorySQL作为一款与PG社区版同步较快的与Oracle保持比较好语法兼容性的开源数据库产品,对于一些想使用开源数据库来完成替代Oracle的用户来说,还是很值得拥有的。
如果对IvorySQL感兴趣,可以参考下面网址:
IvorySQL官网:https://www.ivorysql.org/zh-cn/
GITHUB :https://github.com/IvorySQL/IvorySQL
GITEE :IvorySQL (IvorySQL) - Gitee.com
这篇关于白鳝:聊聊IvorySQL的Oracle兼容技术细节与实现原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



