本文主要是介绍【Q2—30min】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.socket服务端创建过程
socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。我的理解就是Socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭)。

socket()//创建套接字
bind()//分配套接字地址
listen()//等待连接请求状态
accept()//允许连接,类似于打电话过程中的“接听”功能。
read()/write()//进行数据交换
close()//断开连接
启动服务端并测试:gcc server.c -o server ./server
2.mysql建表 其他的数据库
数据库,建立索引的好处
创建Student表:
use student_course;
create table Student(
-> Sno int not null auto_increment primary key,
-> Sname varchar(10) not null,
-> Sex char(1) not null,
-> Sage tinyint(100) not null,
-> Sdept char(4) not null)comment = ‘学生表’;
插入数据:
insert into Student (Sname, Sex, Sage, Sdept) values (‘李勇’, ‘男’, 20, ‘CS’);
查看全表内容:
select * from Student;
一个表可以创建多个索引,但每个索引在该表中的名称是唯一的。
创建索引的优点:
1)创建索引可以大幅提高系统性能,帮助用户提高查询的速度;
2)通过索引的唯一性,可以保证数据库表中的每一行数据的唯一性;
3)可以加速表与表之间的链接;
4)降低查询中分组和排序的时间。
索引的缺点:
1)索引的存储需要占用磁盘空间;
2)当数据的量非常巨大时,索引的创建和维护所耗费的时间也是相当大的;
3)当每次执行CRU操作时,索引也需要动态维护,降低了数据的维护速度。
3.linux gcc编译.cpp文件 常用命令
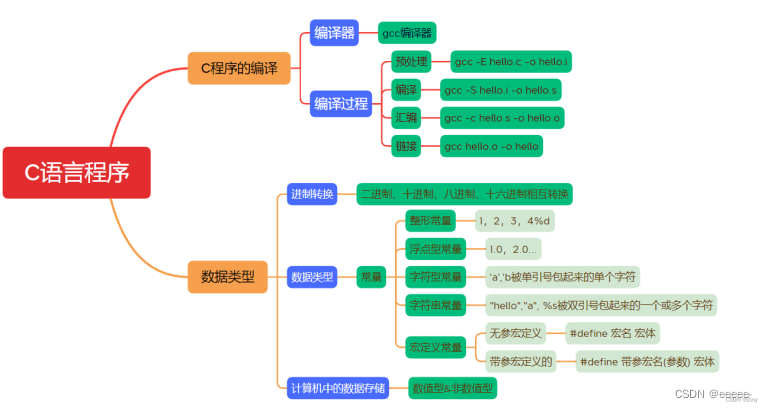
4.编译的四个过程:预处理,编译,汇编,链接。
使用gcc把C文件编译成可执行文件可分为四步:预编译、编译、汇编、连接。
1、预编译(生成.i文件)
预编译器cpp把源文件和相关的头文件(如实例代码中的头文件stdio.h)预编译成一个.i的文件。
执行的命令:gcc -E hello.c -o hello.i
预编译的作用:
a、处理所有的“#include”预编译指令
b、处理所有的"#define"指令,将代码中所有的"#define"删除,并展开所有的宏定义
c、处理所有的条件预编译指令,如#if #elif #else #ifdef #ifnodef #endif等
d、删除所有的注释
e、添加行号和文件名标识,以便产生错误时给出提示信息
2、编译(生成.s文件)
编译器gcc把预处理后的文件进行语法分析、语义分析以及优化后生成汇编代码文件。
执行的命令:gcc -S hello.i -o hello.s
3、汇编(生成.o文件)
汇编器把汇编代码文件转换成中间目标文件
执行的命令:gcc -c hello.s -o hello.o
4、链接(生成可执行文件)
链接器ld把目标文件与所需要的所有的附加的目标文件(如静态链接库、动态链接库)链接起来成为可执行的文件
执行的命令:gcc hello.o -o hello.out
5.stl常用的 vector底层原理 数组和链表区别。查询,插入,删除哪个快
STL是一个打包了数据结构的函数库,STL的所有对象都没必要提前分配内存大小,它会根据对象存取数据的大小来分配空间大小(系统自动扩张)
1.vector(向量)(底层是数组)
向量没有确定数据类型,所以向量可以是多种数据类型,但是注意一个向量对象只能有一种数据类型,可以构造二维向量(二维数组)比如二维整型向量vector 值得注意的是二维向量的大元素和小元素(行元素和最小元素)都是一个向量可以不分配大小而是通过数据的规模分配大小。
vector的find函数是一个比较特殊的函数他的返回值必须用迭代器接收。
迭代器即为一个存储某个值在向量中的地址。
整型迭代器的定义方式:vector::iterator 可以接收vector的元素的地址
vector的find函数: vector::iterator it; it=find(a.begin(),a.end(),int) 其中a为vector的对象
此时为查找a开头到结尾是否有这个值,如果没有就会返回a.end().
如果需要查找vector其中一个元素的下标是多少那么就用it-a.begin()即可求出下标。
2.string(字符串)
字符串也能根据其值的大小来自动分配空间,相当于字符数组但是不需要提前分配空间。string 可用+直接连接字符串。
3.set(集合)(底层红黑树)
set即为一个红黑树(是一种自平衡二叉查找树,红黑树和AVL树类似,都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能.它虽然是复杂的,但它的最坏情况运行时间也是非常良好的可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目),其作用是将排入的数据自动进行去重并且按照树的特性(左孩子的值一定比父节点的小,右孩子的值一定比父节点大) 可起到二分搜索的一个作用,但是这里一般常用的是查找是否右一个值在set里面和去重。
set集合的两个特点,有序和不重复。自动排序。
4.priority_queuqe(优先队列)(底层为大根堆小根堆)
priority_queue的底层为堆,大根堆(根节点的值是整个堆最大的,所有的子节点都比父节点的值小)和小根堆(根节点的值是整个堆最小的,所有的子节点都比父节点大)
5.queue(队列)(底层list或者deque)
queue 模板类的定义在头文件中。
与stack 模板类很相似,queue 模板类也需要两个模板参数,一个是元素类型,一个容器类型,元素类型是必要的,容器类型是可选的,默认为deque 类型。
6.map(映射)(底层为红黑树)
map提供一对一的hash,Map主要用于资料一对一映射(one-to-one)的情況,map内部的实现自建一颗红黑树,这颗树具有对对象自动排序的功能。比如一个班级中,每个学生的学号跟他的姓名就存在一对一的映射关系。
这里介绍常用的方法函数:
map<string, string> mapStudent;//定义变量,一对一数据类型。
7.list(链表)(底层双向链表)
8.stack(栈)(底层为list或者deque)
stack的底层就是一个栈,其底层默认容器为deque(双向队列),栈的特性是后进先出,并且只有一端有接口可以进行操作。
STL 众多容器中,vector 是最常用的容器之一,其底层所采用的数据结构非常简单,就只是一段连续的线性内存空间(泛型的动态类型顺序表)。他以两个迭代器start和finish分别指向配置得来的连续空间中目前已将被使用的空间。迭代器end_of_storage指向整个连续的尾部。
vector在增加元素时,如果超过自身最大的容量,vector则将自身的容量扩充为原来的两倍。扩充空间需要经过的步骤:重新配置空间,元素移动,释放旧的内存空间。一旦vector空间重新配置,则指向原来vector的所有迭代器都失效了,因为vector的地址改变了。
vector扩大容量的本质:当 vector 的大小和容量相等(size==capacity)也就是满载时,如果再向其添加元素,那么 vector 就需要扩容。vector 容器扩容的过程需要经历以下 4 步:
1.完全弃用现有的内存空间,重新申请更大的内存空间;
2.将旧内存空间中的数据,按原有顺序移动到新的内存空间中;
3.将旧的内存空间释放。
4.使用新开辟的空间
vector支持随机访问,但vector不适宜做任意位置的插入和删除操作,因为要进行大量元素的搬移。
所谓数组,就是相同数据类型的元素按一定顺序排列的集合;数组的存储区间是连续的,占用内存比较大,故空间复杂的很大。但数组的二分查找时间复杂度小,都是O(1);数组的空间是从栈分配的。(栈:先进后出)
数组的特点是:查询简单,增加和删除困难;
数组的优点:随机访问性强,查找速度快,时间复杂度是O(1)
数组的缺点:
-
从头部删除、从头部插入的效率低,时间复杂度是o(n),因为需要相应的向前搬移和向后搬移。
-
空间利用率不高
-
内存空间要求高,必须要有足够的连续的内存空间。
-
数组的空间大小是固定的,不能进行动态扩展。
所谓链表,链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。链表的空间是从堆中分配的。(堆:先进先出,后进后出)
链表:链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。
链表的特点是:查询相对于数组困难,增加和删除容易。
链表的优点:- 任意位置插入元素和删除元素的速度快,时间复杂度是o(1)
- 内存利用率高,不会浪费内存
- 链表的空间大小不固定,可以动态拓展。
链表的缺点:随机访问效率低,时间复杂度是o(1)
对于想要快速访问数据,不经常有插入和删除元素的时候,选择数组;对于需要经常的插入和删除元素,而对访问元素时的效率没有很高要求的话,选择链表。
6. get和post的区别:
(1)Get请求的数据(参数)会显示在地址栏,而Post不会,所以,Post比Get更加安全。
(2)Post请求的参数存放到了请求实体中,而Get没有请求实体,Get是存储在请求行中。
(3)数据传输Post有优势:Get方式请求的数据不能超过2k,而Post 没有上限。
(4)浏览缓存Get有优势:Get具有数据缓存,而Post没有。
从优势角度看,数据传输使用Post,数据浏览查询使用Get。即查询时使用Get,其他时候使用Post。表单全部使用Post提交。
这篇关于【Q2—30min】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!