本文主要是介绍linux ptrace 读内存,[原创] Linux ptrace详细分析系列(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Linux ptrace 详解
(该系列将深入分析Linux ptrace的方方面面,争取一次把它搞定,对后续调试或开发都有益处。不定期更新。)
备注:文章中使用的Linux内核源码版本为Linux 5.9,使用的Linux版本为Linux ubuntu 5.4.0-65-generic
一、简述
ptrace系统调用提供了一个进程(tracer)可以控制另一个进程(tracee)运行的方法,并且tracer可以监控和修改tracee的内存和寄存器,主要用作实现断点调试和系统调用追踪。
tracee首先要被attach到tracer上,这里的attach以线程为对象,在多线程场景(这里的多线程场景指的使用clone CLONE_THREAD flag创建的线程组)下,每个线程可以分别被attach到tracer上。ptrace的命令总是以下面的调用格式发送到指定的tracee上:
一个进程可以通过调用fork()函数来初始化一个跟踪,并让生成的子进程执行PTRACE_TRACEME,然后执行execve(一般情况下)来启动跟踪。进程也可以使用PTRACE_ATTACH或PTRACE_SEIZE进行跟踪。
当处于被跟踪状态时,tracee每收到一个信号就会stop,即使是某些时候信号是被忽略的。tracer将在下一次调用waitpid或与wait相关的系统调用之一)时收到通知。该调用会返回一个状态值,包含tracee停止的原因。tracee发生stop时,tracer可以使用各种ptrace的request来检查和修改tracee。然后,tracer使tracee继续运行,选择性地忽略所传递的信号(甚至传递一个与原来不同的信号)。
当tracer结束跟踪后,发送PTRACE_DETACH信号释放tracee,tracee可以在常规状态下继续运行。
二、函数原型及初步使用
1. 函数原型
ptrace的原型如下:
其中request参数表明执行的行为(后续将重点介绍), pid参数标识目标进程,addr参数表明执行peek和poke操作的地址,data参数则对于poke操作,指明存放数据的地址,对于peek操作,指明获取数据的地址。
返回值,成功执行时,PTRACE_PEEK请求返回所请求的数据,其他情况时返回0,失败则返回-1。
2. 函数定义
ptrace的内核实现在kernel/ptrace.c文件中,内核接口是SYSCALL_DEFINE4(ptrace, long, request, long, pid, unsigned long, addr, unsigned long, data)。其代码如下,整体逻辑简单,需要注意的是对PTRACE_TRACEME和PTRACE_ATTACH进行了特殊处理(对于该函数的参数后续将进行深入解析)。
系统调用都改为了SYSCALL_DEFINE的方式。如何获得上面的定义的呢?这里需要穿插一下SYSCALL_DEFINE的定义(syscall.h):
宏定义进行展开:
__SYSCALL_DEFINEx中的x表示系统调用的参数个数,且sys_ptrace的宏定义如下:
所以对应的__SYSCALL_DEFINEx应该是SYSCALL_DEFINE4,这与上面的定义SYSCALL_DEFINE4(ptrace, long, request, long, pid, unsigned long, addr, unsigned long, data)一致。
仔细观察上面的代码可以发现,函数定义其实在最后一行,结尾没有分号,然后再加上花括号即形成完整的函数定义。前面的几句代码并不是函数的实现(详细的分析可以跟踪源码,出于篇幅原因此处不放出每个宏定义的跟踪)。
定义的转换过程:
而对__MAP宏和__SC_DECL宏的定义如下:
按照如上定义继续进行展开
最后调用asmlinkage long sys_ptrace(long request, long pid, unsigned long addr, unsigned long data);。
为什么要将系统调用定义成宏?主要是因为2个内核漏洞CVE-2009-0029,CVE-2010-3301,Linux 2.6.28及以前版本的内核中,将系统调用中32位参数传入64位的寄存器时无法作符号扩展,可能导致系统崩溃或提权漏洞。
内核开发者通过将系统调用的所有输入参数都先转化成long类型(64位),再强制转化到相应的类型来规避这个漏洞。
2. 初步使用
1. 最简单的ls跟踪
首先通过一个简单的例子来熟悉一下ptrace的使用:
运行结果如下:

打印出系统调用号,并等待用户输入。查看/usr/include/x86_64-linux-gnu/asm/unistd_64.h文件(64位系统)查看59对应的系统调用:
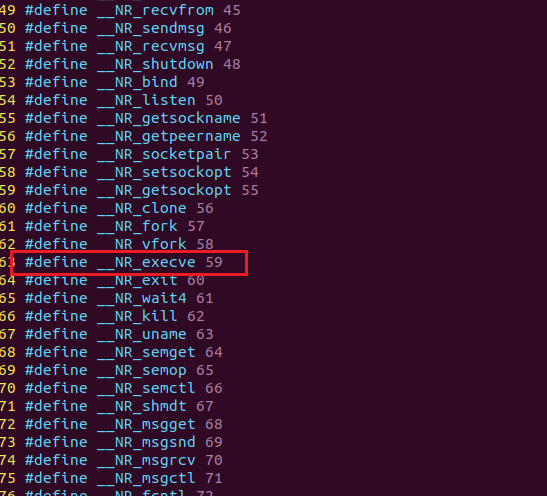
59号恰好为execve函数调用。对上面的过程进行简单总结:
父进程通过调用fork()来创建子进程,在子进程中,执行execl()之前,先运行ptrace(),request参数设置为PTRACE_TRACEME来告诉kernel当前进程正在被trace。当有信号量传递到该进程,进程会stop,提醒父进程在wait()调用处继续执行。然后调用execl(),执行成功后,新程序运行前,SIGTRAP信号量被发送到该进程,子进程停止,父进程在wait()调用处收到通知,获取子进程的控制权,查看子进程内存和寄存器相关信息。
当发生系统调用时,kernel保存了rax寄存器的原始内容,其中存放的是系统调用号,我们可以使用request参数为PTRACE_PEEKUSER的ptrace来从子进程的USER段读取出该值。
系统调用检查结束后,子进程通过调用request参数为PTRACE_CONT的ptrace函数继续执行。
2. 系统调用查看参数
执行结果:
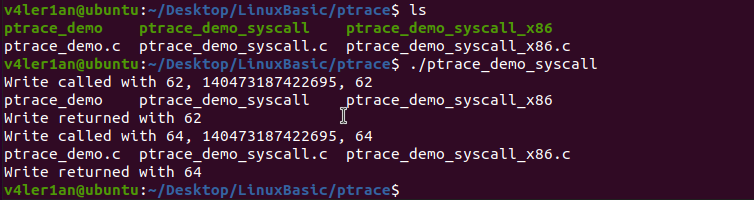
在上面的程序中,跟踪的是wirte的系统调用,ls命令总计进行了三次write的调用。request参数为PTEACE_SYSCALL时的ptrace使kernel在进行系统调用进入或退出时stop子进程,这等价于执行PTRACE_CONT并在下一次系统调用进入或退出时stop。
wait系统调用中的status变量用于检查子进程是否已退出,这是用来检查子进程是否被ptrace停掉或是否退出的典型方法。而宏WIFEXITED则表示了子进程是否正常结束(例如通过调用exit或者从main返回等),正常结束时返回true。
3. 系统调用参数-改进版
前面有介绍PTRACE_GETREGS参数,使用它来获取寄存器的值相比前面一种方法要简单很多:
执行结果:
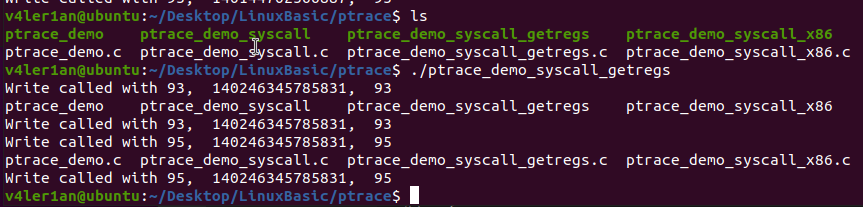
整体输出与前面的代码无所差别,但在代码开发上使用了PTRACE_GETREGS来获取子进程的寄存器的值,简洁了很多。
参考文献
[1]. https://www.linuxjournal.com/article/6100
[2]. https://blog.csdn.net/u012417380/article/details/60468697
[3]. Linux ptrace man page
最后于 2021-3-5 14:38
被有毒编辑
,原因:
这篇关于linux ptrace 读内存,[原创] Linux ptrace详细分析系列(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






