本文主要是介绍Selenium非亚麻,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Expedia Group Technology —软件 (EXPEDIA GROUP TECHNOLOGY — SOFTWARE)
In 2017, the Vrbo™️ search page team (then called the HomeAway® search page team) rewrote the legacy search page application using modern JavaScript technologies such as React and Node. As part of this rewrite, we also wanted to transition from a manually QA-ed biweekly release cycle to a continuous deployment model with automated testing. Since we needed to support IE11, Selenium was the obvious choice for end-to-end release validation.
2017年,Vrbo™️搜索页面团队(当时称为HomeAway®搜索页面团队)使用React和Node等现代JavaScript技术重写了旧版搜索页面应用程序。 作为此重写的一部分,我们还希望从人工进行质量检查的双周发布周期过渡到具有自动测试的连续部署模型。 由于我们需要支持IE11,因此Selenium是端到端版本验证的明显选择。
Since the rewrite, these Selenium tests have proven invaluable for catching page breaking issues (especially IE11) and have caught many P1 issues before making it out to production. Unfortunately, in the beginning of 2020 we noticed that our pass/fail rate for these tests started to approach 50%. This meant that our tests had gotten so flakey over time that developers spent double the amount of time re-running the suite to get a clean build. Something had to be done to get our pass rate back up to an acceptable level.
自重写以来,这些Selenium测试已被证明对于捕获分页问题(尤其是IE11)具有不可估量的价值,并且在投入生产之前已经捕获了许多P1问题。 不幸的是,在2020年初,我们注意到这些测试的通过/失败率开始接近50%。 这意味着随着时间的流逝,我们的测试变得如此困难,以至于开发人员花费了两倍的时间重新运行套件以获得干净的构建。 必须采取一些措施使我们的通过率恢复到可接受的水平。
于是开始调查... (So begins the investigation…)
During a team meeting we discussed what might be causing the flake. Was it our Selenium cloud provider, Saucelabs®? Was it our test environment? Was it Selenium itself? We went so far as to discuss whether it made sense to dump our test suite completely and start over with Puppeteer, but instead we opted to do a deep dive into the failing tests.
在团队会议中,我们讨论了可能导致剥落的原因。 是我们的Selenium云提供商Saucelabs®吗? 是我们的测试环境吗? 是Selenium本身吗? 我们甚至讨论了完全放弃测试套件并从Puppeteer重新开始是否有意义,但我们选择深入研究失败的测试。
我们发现了什么? (What did we find?)
After spending almost a week exhaustively looking through Saucelabs screen-replays and logs we discovered several key issues leading to our test flake, which in order of flakiness included
在花了将近一个星期的时间详尽浏览了Saucelabs的屏幕回放和日志后,我们发现了导致测试薄片出现的几个关键问题,这些问题按薄片的顺序包括
1. Flakey测试环境 (1. Flakey testing environment)
At Vrbo, we have 2 separate testing environments: test and stage. Traditionally test was reserved for developer testing whereas stage was reserved for manual pre-deploy testing and C-team demonstrations. Because of this distinction, test tended to not be stable and many services running in test were either under-provisioned or had poor test data. We found that almost half of all the Selenium test failures were caused by errant errors and timeouts in microservices in test that our app depended upon.
在Vrbo,我们有2个独立的测试环境: test和stage 。 传统上, 测试保留给开发人员测试,而舞台保留给手动部署前测试和C团队演示。 由于存在这种区别, 测试趋于不稳定,并且正在测试的许多服务要么配置不足,要么具有不良的测试数据。 我们发现,几乎所有Selenium测试失败的原因都是应用程序所依赖的测试中微服务中的错误错误和超时引起的。
Because stage was better maintained due to its importance as a demo environment, we reconfigured out tests to run against an instance of our application running in stage rather than test. Since our tests didn’t rely on specific test data, this change was simple and led to a great reduction in errant errors and timeouts, but it still only reduced our failures by ~20% or so.
由于舞台作为演示环境的重要性而得以更好地维护,因此我们重新配置了测试,以针对在舞台而不是test上运行的应用程序实例运行。 由于我们的测试不依赖特定的测试数据,因此此更改很简单,并且大大减少了错误和超时,但仍仅使我们的故障减少了20%左右。
2.第三方脚本 (2. 3rd party scripts)
The 2nd most common error we noticed in our end-to-end suite was Selenium timeouts caused by 3rd party scripts, particularly Google analytics and the Google maps API scripts. Specifically, for maybe about 10% of test suite runs, a Google analytics or Google maps API script would hang, preventing the DOMContentLoaded event from firing. When this happens, Selenium times out waiting for the load event even though the rest of the page is still usable. Since most of the end-to-end tests didn’t require Google maps to load and none of the tests required Google analytics, we were able to disable Google analytics in our test environment and turn off Google maps for all of the non-applicable tests.
我们在端到端套件中发现的第二个最常见的错误是由第三方脚本(尤其是Google Analytics(分析)和Google Maps API脚本)引起的Selenium超时。 具体来说,对于大约10%的测试套件运行,Google分析或Google Maps API脚本将挂起,从而防止DOMContentLoaded事件触发。 发生这种情况时,即使页面的其余部分仍然可用,Selenium也会等待加载事件超时。 由于大多数端到端测试都不需要加载Google地图,并且所有测试都不需要Google Analytics(分析),因此我们能够在测试环境中禁用Google Analytics,并关闭所有不适用的Google地图测试。
3.测试空闲超时不足 (3. Insufficient test idle timeout)
Most Selenium suites at Vrbo are built using WebDriver.io (WDIO). However our search page application is unique in that it uses Jest as a test runner rather than the built in WebDriver.io test runner. This has the advantage of giving us Jest’s watch feature and richer assertion library, but with the added cost of needing to “tweak” Jest’s parallel test execution to play nicely with Saucelabs. Due to the nature of our test setup we discovered that Jest was setting up test instances in Saucelabs far ahead of when Jest would actually run the tests for that instance. In practice this meant that by the time a test instance was needed, Saucelabs would already have timed out waiting for commands from Jest and closed the test instance.
Vrbo上的大多数Selenium套件都是使用WebDriver.io (WDIO)构建的。 但是,我们的搜索页面应用程序是独特的,因为它使用Jest作为测试运行程序,而不是内置的WebDriver.io测试运行程序。 这具有为我们提供Jest的监视功能和更丰富的断言库的优点,但是增加了需要“调整” Jest的并行测试执行以与Saucelabs完美配合的额外成本 。 由于测试设置的性质,我们发现Jest在Saucelabs中设置测试实例的时间远远早于Jest实际为该实例运行测试的时间。 实际上,这意味着到需要一个测试实例时,Saucelabs已经超时等待来自Jest的命令并关闭该测试实例。
Fortunately for us, this was easy enough to fix by bumping our idleTimeout in our Sauce config.
对我们来说幸运的是,通过在Sauce配置中增加idleTimeout可以轻松解决此问题。
4.比赛条件 (4. Race conditions)
Several of our search filter related tests had become flakey after we switched the search page from server side rendering all of its content to client side rendering of main content in early 2019. Our tests had originally been written under the assumption that once the page loads, a search had already been performed server side and it would be safe to apply filters. However with client side rendering we were performing the main search API call after the initial pageload. This meant that it was now possible for Selenium to start applying filters before the client side search was complete, introducing a race condition in which the initial client side search would blow away any applied filters depending upon how fast or slow Selenium executed.
在我们于2019年初将搜索页从服务器端呈现其所有内容转换为客户端端对主要内容进行呈现之后,我们与搜索过滤器相关的几个测试都变得很容易。我们最初的假设是,一旦页面加载,服务器端已经执行了搜索,因此可以安全地应用过滤器。 但是,使用客户端渲染时,我们是在初始页面加载之后执行主搜索API调用。 这意味着Selenium现在有可能在客户端搜索完成之前开始应用过滤器,从而引入了竞争条件,在这种情况下,最初的客户端搜索将耗尽所有应用的过滤器,具体取决于Selenium执行的快慢。
Once we understood where the race condition lay, it is straight forward to sprinkle a few waitForExists into our tests to make the test execution wait for the page to be ready to receive commands.
一旦我们了解了竞争条件的位置,就可以直接在我们的测试中添加一些waitForExists,以使测试执行等待页面准备好接收命令。
5.缺少测试重试 (5. Lack of test retries)
Fixing the above 4 issues allowed us to take our pass rate from ~50% all the way up to ~85%, giving us a huge increase in reliability of our tests. At this point the rest of the failures we were seeing corresponded to a big “other” category of issues that did not fit into a single root cause. For example
解决上述4个问题后,我们可以将通过率从〜50%一直提高到〜85%,从而使我们的测试可靠性大大提高。 在这一点上,我们所看到的其余故障对应于大的“其他”类别的问题,而这些问题都不是一个根本原因。 例如
Occasionally we’d still see HTTP 500 errors from an upstream service, i.e. even the stage environment was not 100% reliable, nor could we reasonably expect it to be 100% reliable.
有时我们仍然会从上游服务中看到HTTP 500错误,即,即使舞台环境也不是100%可靠的,我们也不能合理地期望它是100%可靠的。
One out of every 200 or so pageloads, we’d occasionally see our admission control feature kick in. To fix this we would’ve had to provision more instances in our staging environment or slow down our test execution to avoid overloading the instance. Neither of these was desirable.
每200个左右页面加载中就有一个,我们偶尔会看到我们的准入控制功能启动。要解决此问题,我们必须在暂存环境中配置更多实例,或者放慢测试执行速度,以免使实例过载。 这些都不是可取的。
The potential root causes of these rare failures are too many and too infrequent to warrant fixing individually. If we counted up all of the possible types of test failures due to flake and ordered them by frequency of occurrence, we’d get a graph with a long tail
这些罕见故障的潜在根本原因太多且太少,无法单独修复。 如果我们计算出由于剥落引起的所有可能的测试失败类型,并按照出现的频率对它们进行排序,我们将得到一条长尾图
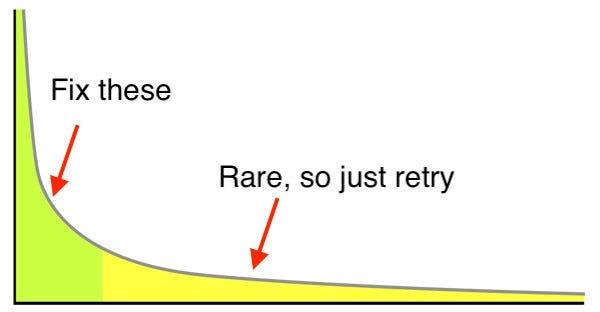
Our previous 4 steps fixed issues that lay in the green area of the curve, but now that we’re looking at infrequent failures in the yellow area, it was time to introduce test retry logic into our tests.
我们之前的4个步骤解决了曲线绿色区域中的问题,但是现在我们正在查看黄色区域中的罕见故障,现在是时候将测试重试逻辑引入我们的测试中了。
This test retry logic consisted of 2 forms of retries:
该测试重试逻辑由两种形式的重试组成:
Check for an error page
检查错误页面
After initial page load, check if there was a 500 error page, if there was, retry loading the page just once. We baked this retry logic into our existing waitForSearchResults function which tests use to wait for the client side search call to return before interacting with the page.
初始页面加载后,检查是否有500错误页面,如果存在,请重试一次。 我们将此重试逻辑烘焙到我们现有的waitForSearchResults函数中,该函数用于在与页面进行交互之前等待客户端搜索调用返回。
Global retry in CI/CD pipeline
CI / CD管道中的全球重试
The 2nd form of retry consisted of a global retry in our Jenkins CI/CD pipeline which would retry the whole Selenium suite once if the suite failed.
重试的第二种形式是在我们的Jenkins CI / CD管道中进行全局重试,如果套件失败,它将重试整个Selenium套件一次。

结果呢? (And the Result?)
After making all the above changes, we were able to increase our test success rate to 92%. You can see the stark change below when we rolled out the updates on January 31st.
完成上述所有更改后,我们可以将测试成功率提高到92%。 当我们在1月31日推出更新时,您可以在下面看到明显的变化。

In addition with the Jenkins global retry, this effectively raised the PR pass rate for e2e tests to 100%! Meaning that no PR was failing due to test instability! Now everyday we can open the Saucelabs dashboard and revel in the sea of green
除了Jenkins全球重试,这还有效地将e2e测试的PR通过率提高到100%! 这意味着没有PR因测试不稳定而失败! 现在,每天我们都可以打开Saucelabs仪表板,陶醉在绿色的海洋中
外卖 (Takeaways)
Through the entire investigation one thing stood out. Every test failure could be explained by either a problem with the test itself, the test environment, or the app itself. In none of the test failures did we find any instability in either Saucelabs or Selenium itself. This is an important observation since many times developers can be quick to discard Selenium as buggy or outdated in favor of other tools such as Puppeteer or Cypress.io, but in our case every single problem was the fault of our tests, app, or environment, not the tool itself. This shows the importance of fully understanding your tools and the problem you are trying to solve with them before discarding them and reaching for a different tool. We are not saying that Selenium and Sauce are issue-free, just that they are nowhere near as bug and flake riddled as some might lead you to believe.
在整个调查中,一件事情引人注目。 每个测试失败都可以用测试本身,测试环境或应用程序本身的问题来解释。 在所有测试失败中,我们都没有发现Saucelabs或Selenium本身有任何不稳定性。 这是一个重要的观察结果,因为很多时候开发人员可以Swift地将Selenium丢弃为越野车或过时的设备,而转而使用其他工具(例如Puppeteer或Cypress.io),但对于我们而言,每个问题都是我们的测试,应用或环境的错误,而不是工具本身。 这表明了充分了解您的工具的重要性,以及在丢弃它们并寻求其他工具之前要尝试使用它们解决的问题。 我们并不是说Selenium和Sauce是没有问题的,只是它们远不如某些可能使您相信的bug和薄片般混乱。
Learn more about technology at Expedia Group
在Expedia Group上了解有关技术的更多信息
翻译自: https://medium.com/expedia-group-tech/selenium-isnt-flakey-4d9c16b2452
相关文章:
这篇关于Selenium非亚麻的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




