本文主要是介绍反爬和反反爬,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
python编程快速上手(持续更新中…)
python爬虫从入门到精通
文章目录
- python编程快速上手(持续更新中…)
- python爬虫从入门到精通
- 概述
- 1.服务器发爬的原因
- 2 服务器常反什么样的爬虫
- 3 反爬虫领域常见的一些概念
- 4 反爬的三个方向
- 基于身份识别进行反爬
- 基于爬虫行为进行反爬
- 基于数据加密进行反爬
- 图形验证码处理
- 1.图片验证码
- 1.1 什么是图片验证码
- 1.2 验证码的作用
- 1.3 图片验证码在爬虫中的使用场景
- 1.4 图片验证码的处理方案
- 2.图片识别引擎
- 2.1 什么是tesseract
- 2.2 图片识别引擎环境的安装
- 2.3 图片识别引擎的使用
- 2.4 图片识别引擎的使用扩展
- 3 打码平台
- 1.为什么需要了解打码平台的使用
- 2 常见的打码平台
- 3 云打码的使用(已跑路)
- 3.1 云打码官方接口
概述
1.服务器发爬的原因
爬虫占总PV(PV是指页面的访问次数,每打开或刷新一次页面,就算做一个pv)比例较高,这样浪费钱(尤其是三月份爬虫)。
公司可免费查询的资源被批量抓走,丧失竞争力,这样少赚钱。
爬虫在国内还是个擦边球,就是有可能可以起诉成功,也可能完全无效。所以还是需要用技术手段来做最后的保障。
2 服务器常反什么样的爬虫
应届毕业生
应届毕业生的爬虫通常简单粗暴,根本不管服务器压力,加上人数不可预测,很容易把站点弄挂。
创业小公司
现在的创业公司越来越多,也不知道是被谁忽悠的然后大家创业了发现不知道干什么好,觉得大数据比较热,就开始做大数据。分析程序全写差不多了,发现自己手头没有数据。怎么办?写爬虫爬啊。于是就有了不计其数的小爬虫,出于公司生死存亡的考虑,不断爬取数据。
不小心写错了没人去停止的失控小爬虫
有些网站已经做了相应的反爬,但是爬虫依然孜孜不倦地爬取。什么意思呢?就是说,他们根本爬不到任何数据,除了httpcode是200以外,一切都是不对的,可是爬虫依然不停止这个很可能就是一些托管在某些服务器上的小爬虫,已经无人认领了,依然在辛勤地工作着。
成型的商业对手
这个是最大的对手,他们有技术,有钱,要什么有什么,如果和你死磕,你就只能硬着头皮和他死磕。
抽风的搜索引擎
大家不要以为搜索引擎都是好人,他们也有抽风的时候,而且一抽风就会导致服务器性能下降,请求量跟网络攻击没什么区别。
3 反爬虫领域常见的一些概念
因为反爬虫暂时是个较新的领域,因此有些定义要自己下:
爬虫:使用任何技术手段,批量获取网站信息的一种方式。关键在于批量。
反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。关键也在于批量。
误伤:在反爬虫的过程中,错误的将普通用户识别为爬虫。误伤率高的反爬虫策略,效果再好也不能用。
拦截:成功地阻止爬虫访问。这里会有拦截率的概念。通常来说,拦截率越高的反爬虫策略,误伤的可能性就越高。因此需要做个权衡。
资源:机器成本与人力成本的总和。
这里要切记,人力成本也是资源,而且比机器更重要。因为,根据摩尔定律,机器越来越便宜。而根据IT行业的发展趋势,程序员工资越来越贵。因此,通常服务器反爬就是让爬虫工程师加班才是王道,机器成本并不是特别值钱。
4 反爬的三个方向
基于身份识别进行反爬
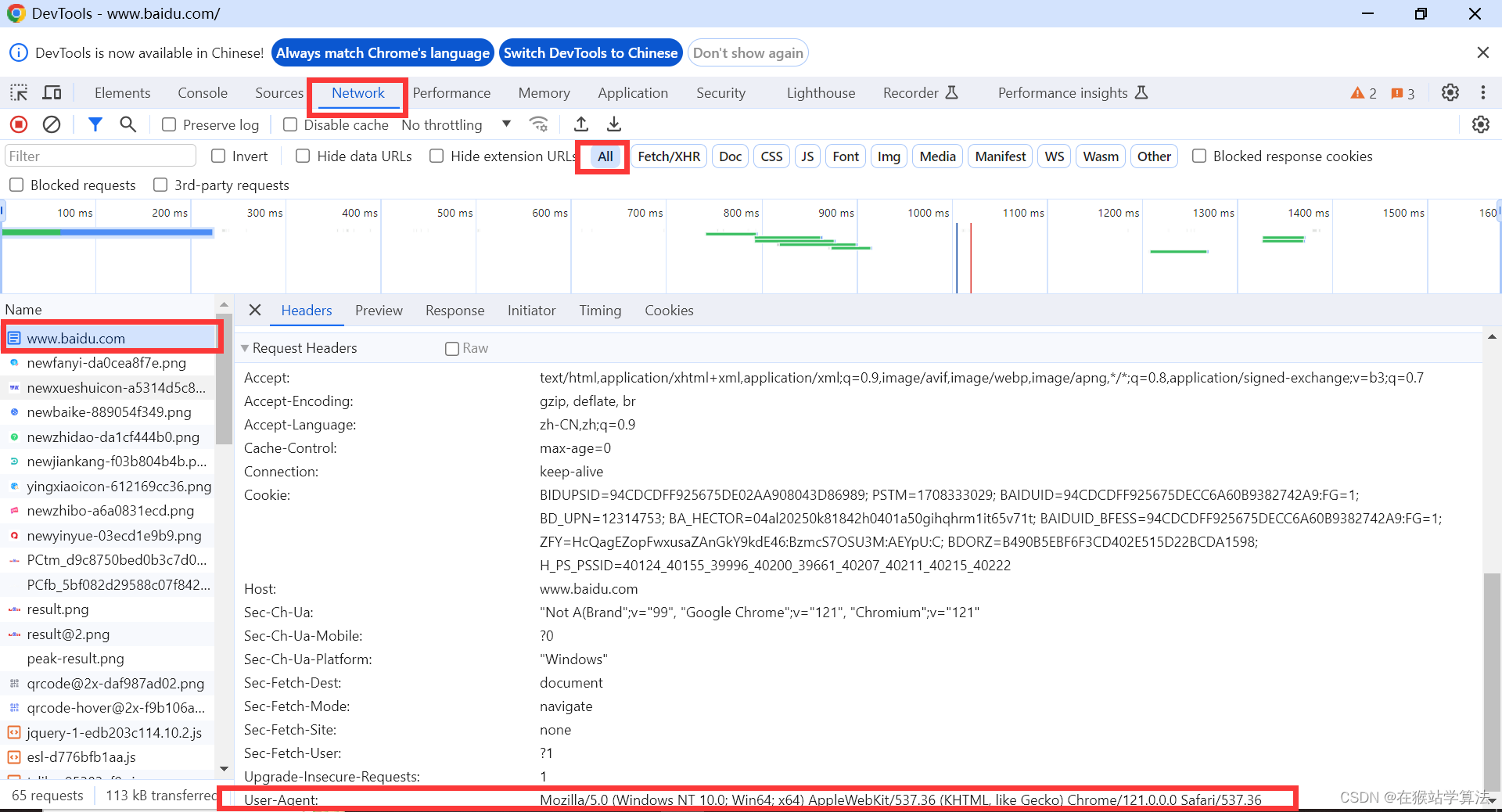
1.通过header字段身份反爬

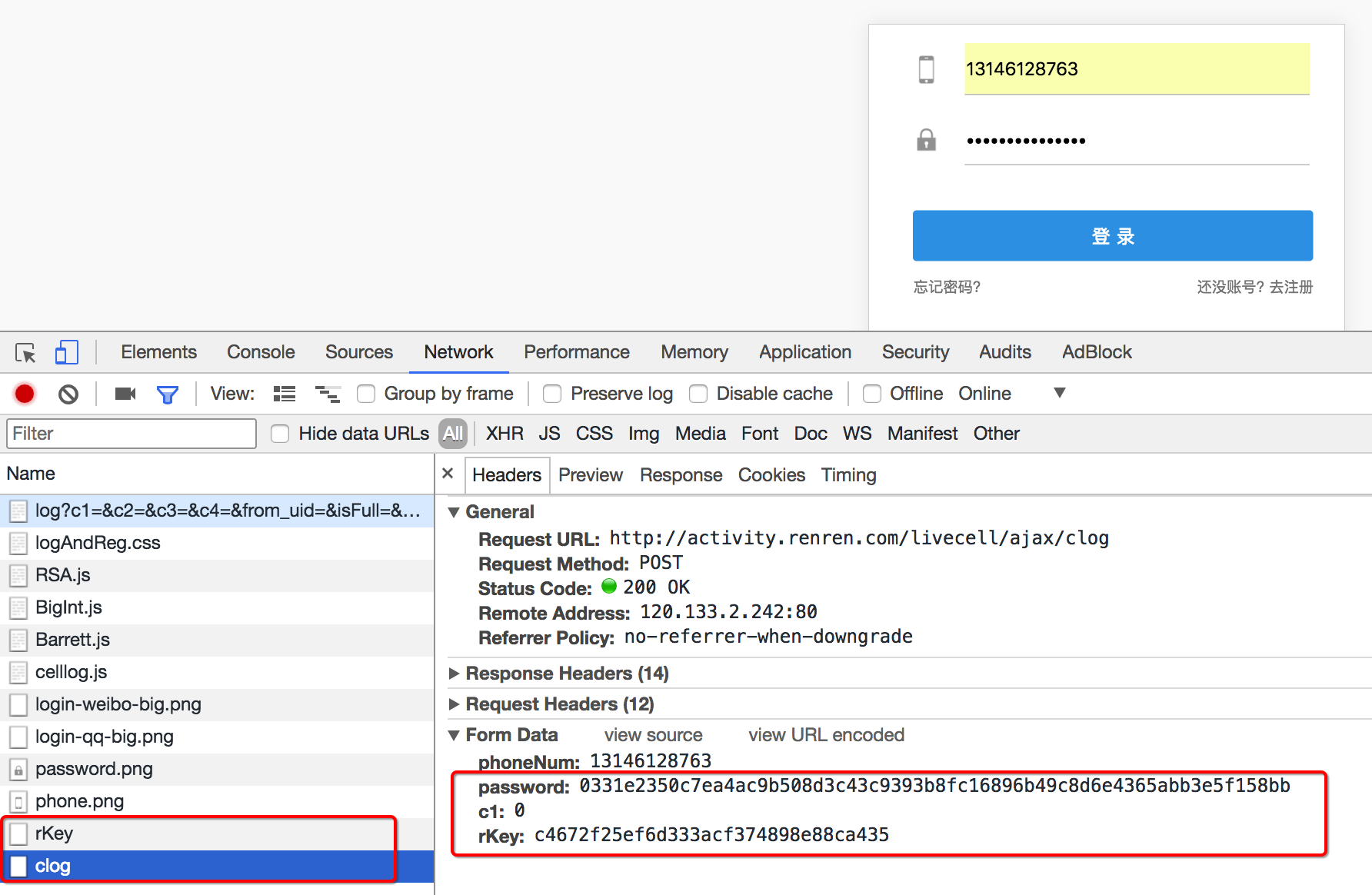
2.通过请求参数反爬

基于爬虫行为进行反爬
1.基于请求频率和总请求数量

2.根据爬取行为进行反爬,通常爬虫步骤上分析


基于数据加密进行反爬

图形验证码处理
1.图片验证码
1.1 什么是图片验证码
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序。
1.2 验证码的作用
防止恶意破解密码、刷票、论坛灌水、刷页。有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登录尝试,实际上使用验证码是现在很多网站通行的方式(比如招商银行的网上个人银行,百度社区),我们利用比较简易的方式实现了这个功能。虽然登录麻烦一点,但是对网友的密码安全来说这个功能还是很有必要,也很重要。
1.3 图片验证码在爬虫中的使用场景
注册
登录
频繁发送请求时,服务器弹出验证码进行验证
1.4 图片验证码的处理方案
手动输入(input)
这种方法仅限于登录一次就可持续使用的情况
图像识别引擎解析
使用光学识别引擎处理图片中的数据,目前常用于图片数据提取,较少用于验证码处理
打码平台
爬虫常用的验证码解决方案
2.图片识别引擎
OCR(Optical Character Recognition)是指使用扫描仪或数码相机对文本资料进行扫描成图像文件,然后对图像文件进行分析处理,自动识别获取文字信息及版面信息的软件。
2.1 什么是tesseract
Tesseract,一款由HP实验室开发由Google维护的开源OCR引擎,特点是开源,免费,支持多语言,多平台。
项目地址:https://github.com/tesseract-ocr/tesseract
2.2 图片识别引擎环境的安装
1 引擎的安装
mac环境下直接执行命令
brew install --with-training-tools tesseract
windows环境下的安装
可以通过exe安装包安装,下载地址可以从GitHub项目中的wiki找到。安装完成后记得将Tesseract 执行文件的目录加入到PATH中,方便后续调用。
1.下载安装64位的安装包
http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,
2.配置环境变量

3.其他语言的识别包https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
简体字识别包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata
繁体字识别包:https://github.com/tesseract-ocr/tessdata/raw/4.0/chi_tra.traineddata
linux环境下的安装
sudo apt-get install tesseract-ocr
2 Python库的安装
PIL用于打开图片文件
pip install pillow
pytesseract模块用于从图片中解析数据
pip install pytesseract
简单使用cmd
进入图片路径
tesseract test.jpg result

2.3 图片识别引擎的使用
通过pytesseract模块的 image_to_string 方法就能将打开的图片文件中的数据提取成字符串数据,具体方法如下
#coding:utf-8
from PIL import Image
import pytesseract# cmd
# tesseract test.jpg result# im = Image.open('test.jp
im = Image.open('test.jpg')result = pytesseract.image_to_string(im)
print(result)**异常:**Python tesseract is not installed or it’s not in your path
修改:tesseract_cmd路径
**注意:**反斜杠

2.4 图片识别引擎的使用扩展
tesseract简单使用与训练
其他ocr平台
微软Azure 图像识别:https://azure.microsoft.com/zh-cn/services/cognitive-services/computer-vision/
有道智云文字识别:http://aidemo.youdao.com/ocrdemo
阿里云图文识别:https://www.aliyun.com/product/cdi/
腾讯OCR文字识别:https://cloud.tencent.com/product/ocr
3 打码平台
1.为什么需要了解打码平台的使用
现在很多网站都会使用验证码来进行反爬,所以为了能够更好的获取数据,需要了解如何使用打码平台爬虫中的验证码
2 常见的打码平台
云打码:http://www.yundama.com/
能够解决通用的验证码识别
极验验证码智能识别辅助:http://jiyandoc.c2567.com/
能够解决复杂验证码的识别
3 云打码的使用(已跑路)
下面以云打码为例,了解打码平台如何使用
3.1 云打码官方接口
下面代码是云打码平台提供,做了个简单修改,实现了两个方法:
indetify:传入图片的响应二进制数即可
indetify_by_filepath:传入图片的路径即可识别
其中需要自己配置的地方是:
username = ‘whoarewe’ # 用户名
password = ‘***’ # 密码
appid = 4283 # appid
appkey = ‘02074c64f0d0bb9efb2df455537b01c3’ # appkey
codetype = 1004 # 验证码类型
云打码官方提供的api如下:
获取动态验证码(知乎)
https://www.zhihu.com/captcha.gif?r=%d&type=login
这篇关于反爬和反反爬的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!