本文主要是介绍Mit 6.830:SimpleDB 总结篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- lab1 表结构
- 结构
- 持久化与缓存
- 查询的流程
- lab2 复杂查询、新增、删除
- 比较
- 单向比较
- 双向元组比较
- 操作符
- 条件过滤
- 连接
- 新增
- 删除
- 持久化和缓冲池
- 查询的流程
- lab3 直方图
- 整体架构
- 基数(cardinality)和选择性(selectivity)
- 概念
- 作用:
- 优化器
- 基于规则的优化器 RBO
- 基于代价的优化器 CBO
- 实现内容
- 直方图
- 内容
- 作用:计算选择率
- 直方图与表的关系
- 构建关系
- 连接优化
- lab4 事务和锁
- 两段锁协议
- 事务锁逻辑
- 加锁阶段
- 解锁阶段
- 事务和脏页
- 事务回滚
- lab5 B+树
- 结构
- 查询
- 插入
- 分裂叶子节点
- 分裂内部节点
- 代码实现文章
- 参考文章
本文只做总结,简略的理解方向,具体实现请看之前的文章
lab1 表结构
结构
SimpleDB是基于行式储存的数据库,所以说,记录都是按行储存的。
行是比较复杂的,因为要储存的东西比较多
- 行的结构:有多少列,列属于什么属性,列的名称
TupleDesc结构:在后面会经常用到,用于表示当前表有什么属性,所以适用于表、页、行,因为属于表级属性,子集应当相同
- 行的内容:就是列对应的内容,应该储存的数据
Filed数组:对应属性储存对应值,一般来说,只有String和Int两种属性,因为对于简单的实验来说,不需要那么多复杂的结构,所需要的是去了解原理
- 路径:该行从属于哪个页面,行序号
RecordId结构:路径结构,表面该行属于PageId某个页面的tupleno行,这PageId所对应的DbPage属于DbFile某个表- 理清脉络就是整一条路径:以表为根(通过
表ID查询表),表分为多个页,通过页ID找到该页下的多个行,根据行ID找到对应的数据
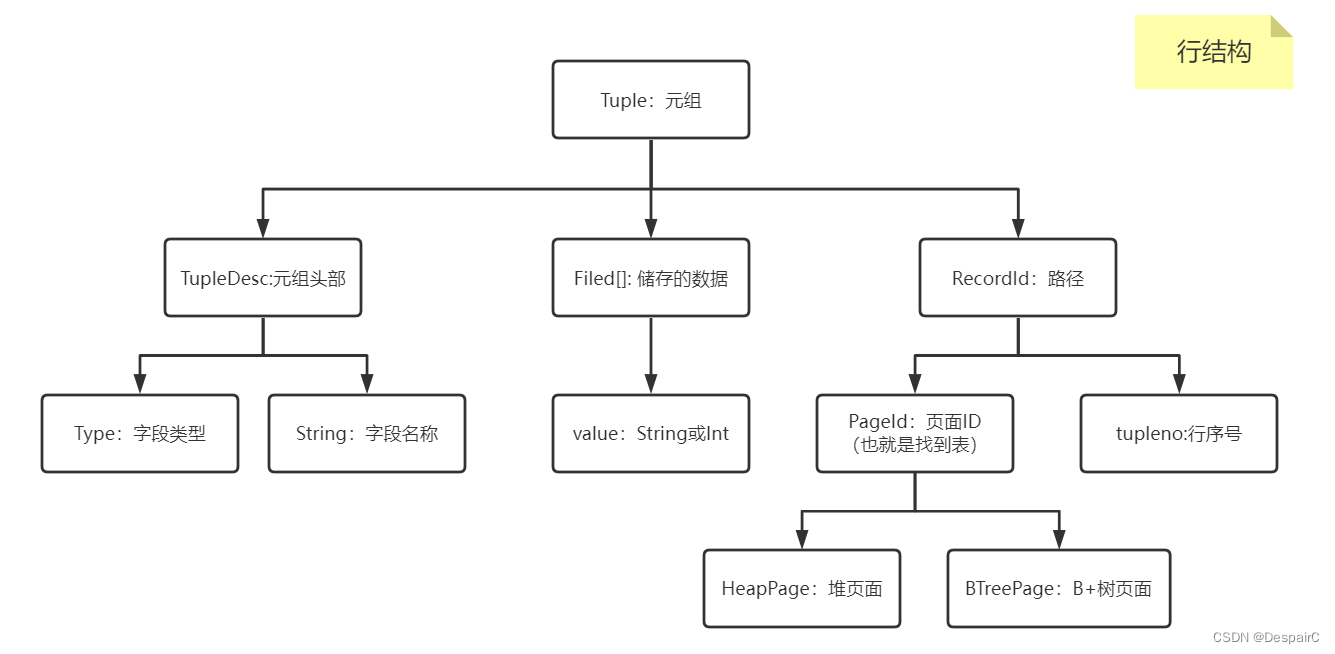
从低向上写,下面的就是页、表结构,其中页结构属于内存中的内容,所以归类于上面,而表结构实际上是IO流读取,没有真实储存数据的实体,所以归到下面的持久化层
- 这里的页结构会做相应的数据储存,每个页对应若干行的数据
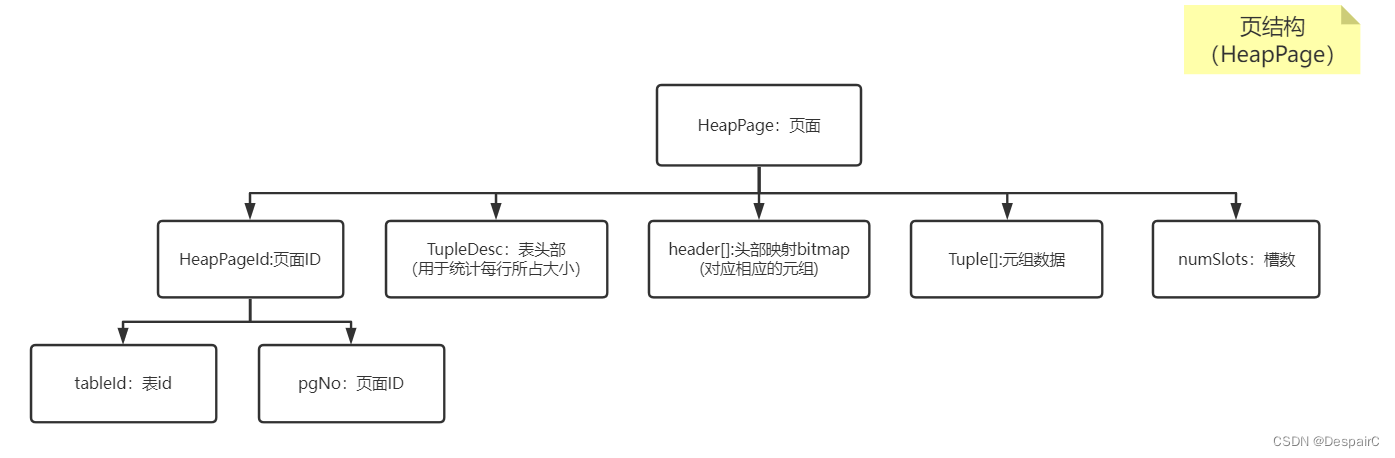
除了页面自身的属性ID,从属外,就是该结构如何去储存数据
引入一个结构 header[],是一个byte数组,对应的是位图,每行数据的第一格不做数据储存,作为标识
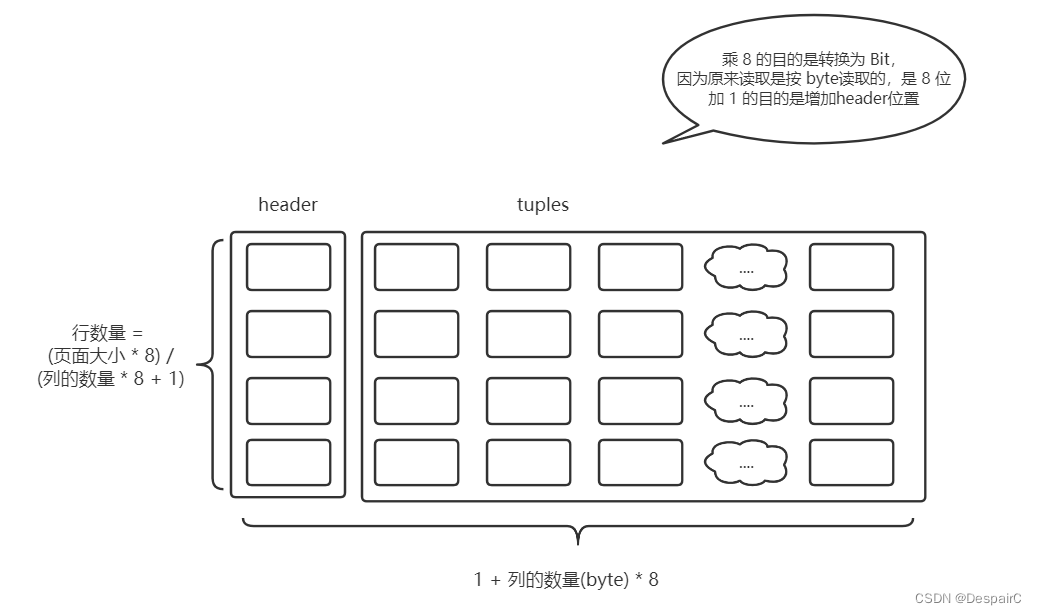
由图可以看出,引入了一个header标识,当header中某个比特位由0变为1的时候,则说明当前位已经被使用了
要注意的是java中没有比特位一说,所以使用了最小的 byte 当数组,如byte[0]其实就包括了8个比特位,0000 0000,当某个位被使用的时候就需要去将相应的比特位置1,比如第三位 0010 0000,就说明行已被使用
图中的header是以比特位的形式展现,并不是java中的byte,所以并不相同,在java中的公式应该改变为
- 行数量 / 8,因为要由 bit 转换成 byte
具体的实现可以参考之前的文章
持久化与缓存
又需要引入持久化层,以便于快速找到表相对应的文件
- 这里的持久化层是记录表ID和表对应实例的映射,也就可以通过表ID快速查询到实例
- 一般来说,为了减少IO,都会去先走缓冲池,查看是否已经在内存中,如果没有,则进行读取,顺便缓冲到内存中。
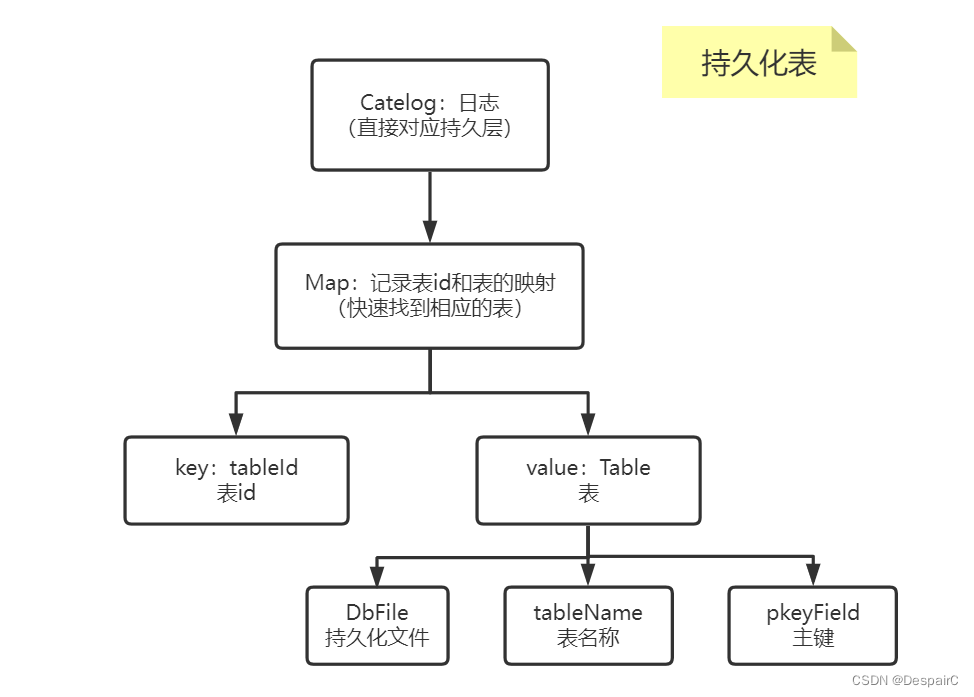
持久化结构有两种,lab1主要介绍的是 HeapFile,所以不会涉及到BTreeFile的内容
- 在本实验中一个表对应一个文件,表的唯一ID通过文件的绝对路径获取
- 和上面结构相照应,储存文件储存的位置,比如 E:/file/something.txt
- 根据储存的位置,就可以使用IO流进行读取,按页读取到内存中
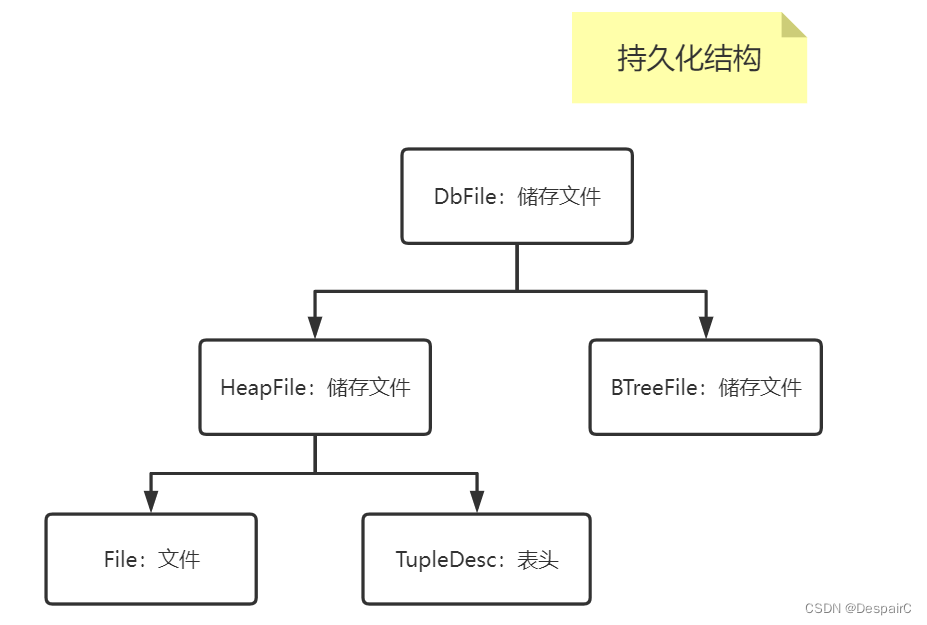
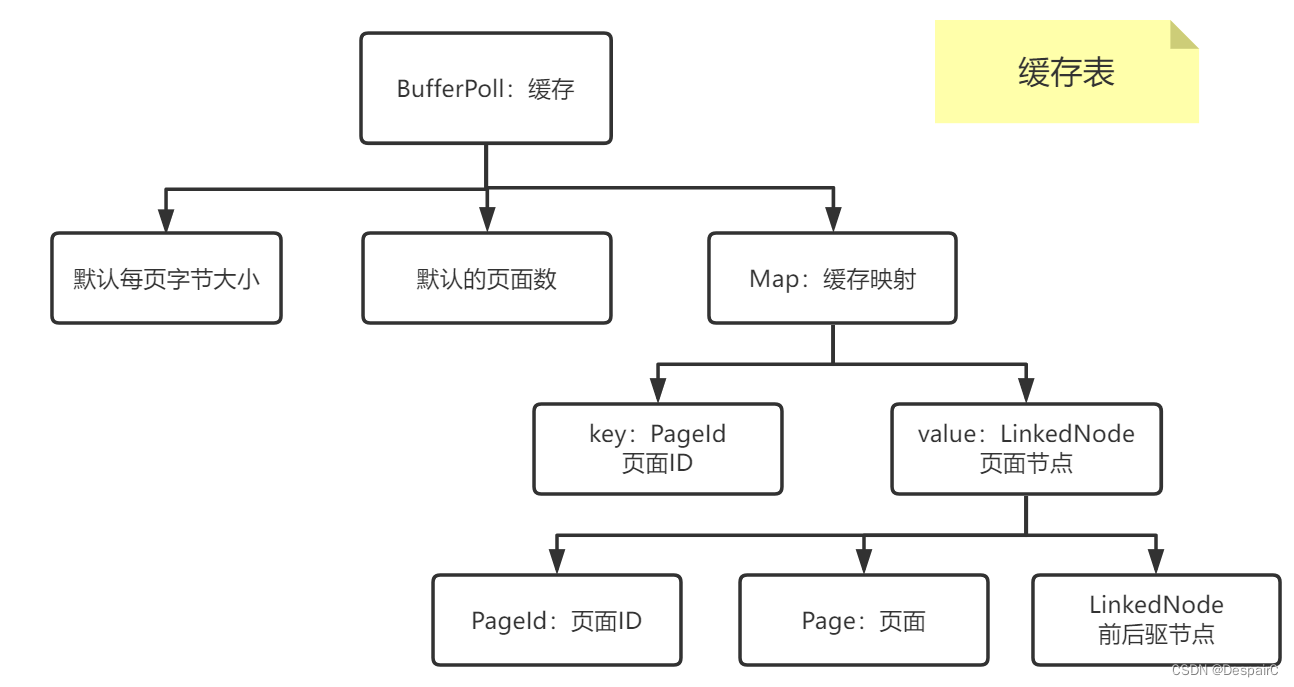
除了持久化之外,每次都需要将持久化的文件读到内存当中,作为快速读取的缓冲区
- 保存页面ID和页面实例的映射,缓存当前页面的数据,以便于减少IO消耗,加快热点数据的读取
- 由于内存空间是有限的,所以说缓存是有限制大小的,既然如此就会导致缓存会满的情况,这里采用的是LRU缓存淘汰策略,解决页面满载的情况
查询的流程
查询这里还要介绍一个查询的结构SeqScan,用于检索表,检索上面结构的内容
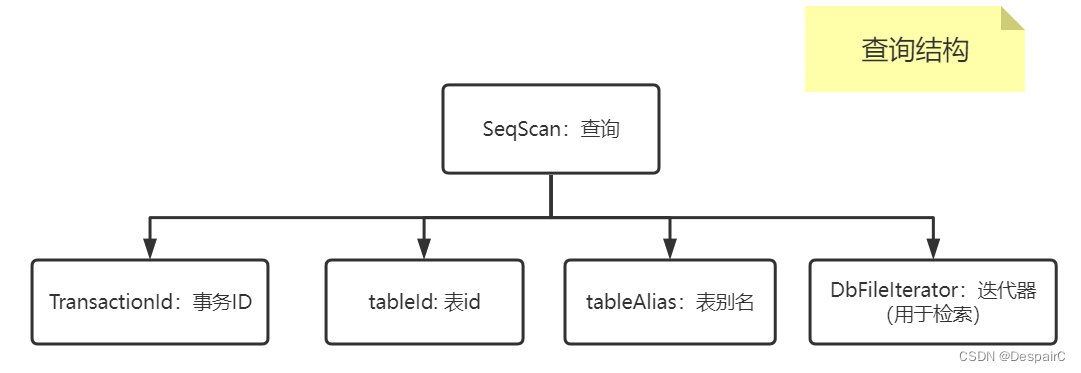
查询流程:其实这里就是lab1最后的测试过程
- 持久化层,将文件名,表结构挂到
HeapFile的名下,但此时还没有开始读,只是说明了这个表在哪个位置,初始化了位置,提供了读的迭代器(当开始读的时候就需要进行IO)// tupleDesc 是表的结构 = 字段属性 + 字段名称(具体结构看代码或者上面的简略图可以看出来) HeapFile heapFile = new HeapFile(new File("some_date_file.dat"), tupleDesc); - 读取该实例后,将表对应的ID放到日志中,这里的日志就是相对于整个
数据库而言,每个表id对应的Table实例,Table里面就包括刚刚读取的HeapFile文件这里的 表ID 我采用的实现方式是取文件绝对路径的 hash码,理论上不可能会重复,属于独一无二的id
Database.getCatalog().addTable(heapFile, "test"); - 此时就是创建数据库完成了,然后就可以通过查询去执行sql查询某些内容
// 忽略这个事务id,对这里目前没有影响,只是给到一个事务id,在事务和锁章节有使用到共享锁和排它锁 SeqScan scan = new SeqScan(transactionId, heapFile.getId()); - 获得
SeqScan的迭代器scan.open();while (scan.hasNext()){Tuple tuple = scan.next();// 打印出每一行System.out.println(tuple);}scan.close();- 得到了查询的实例,实际上就是
SeqScan帮你做好了查询调用上述文件的过程。下面的过程实际上都是SeqScan的内部调用好的
- open方法:获取要查询的表内容,通过
表ID去找到相对应的表迭代器
iterator = Database.getCatalog().getDatabaseFile(tableid).iterator(tid);可以看到如果要去查询表内容,就需要通过第二部构建的日志,根据表id找到相应 HeapFile实例内容,得到迭代器使用,其实就是每一行的数据
- 当启动迭代器后,此时启动的是
HeapFile实例下的迭代器,进行IO流的读取- 按页码
HeapPageId读取HeapPage - 实际上并不是直接调用 HeapFile 本身的方法,而是通过调用 BufferPoll ,查看缓存池中是否有缓冲当前页,如果没有,才会回来继续读取(可以看下上面缓冲池的结构)
- 按页码
- 得到了查询的实例,实际上就是
lab2 复杂查询、新增、删除
比较
单向比较
由标题明白,就是固定一个常量值,比如 a > 5,只有一个变量的比较称为单向比较
- 在
Predicate中,单向比较的内容为某个字段的内容Field,在初始化实例的时候给予。然后只需要与相对应的表中的字段进行比较即可
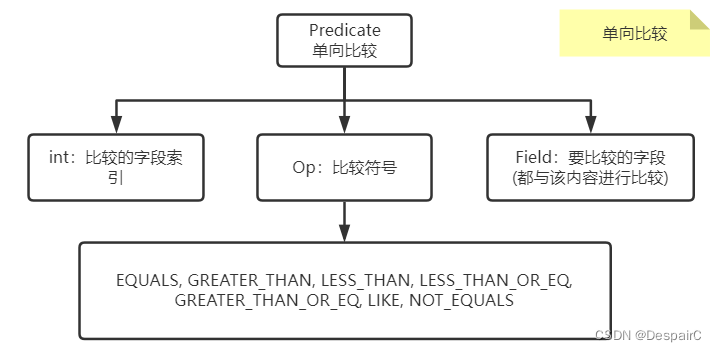
单单只有索引是无法比较的,并且是某一行的某一字段的索引,所以需要将比较的tuple传进方法中,进行比较后返回true or false
public boolean filter(Tuple t) {// some code goes here// 获取字段,传入比较符号,和当前 Field比较return t.getField(field).compare(op, operand);}
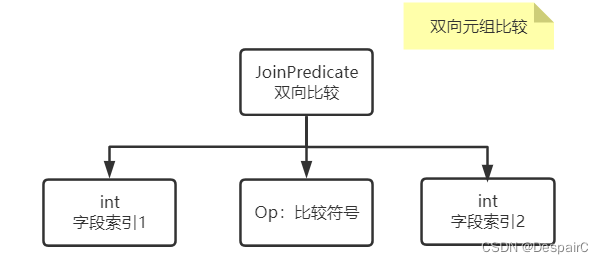
双向元组比较
和单向类似的原理,只是不再需要初始化的时候给定一个固定值,如 a > b,两者都可以是变量变化
- 比较的方法和上面也一样,传两个
Tuple进来进行比较
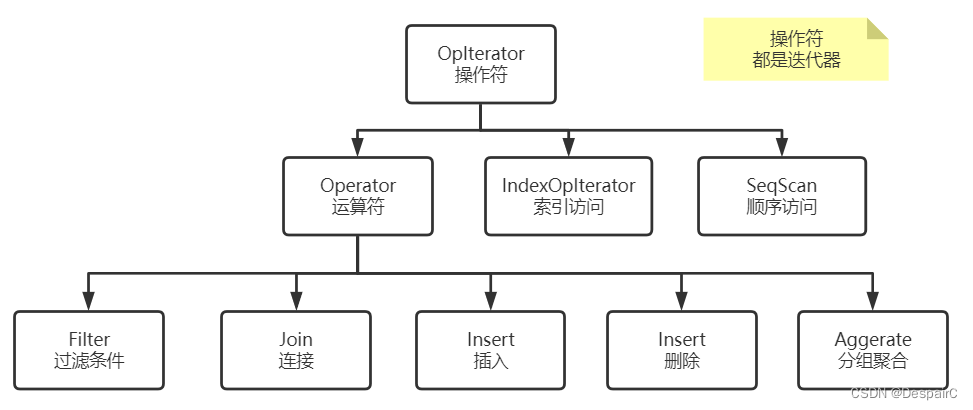
操作符
这一系列类实现的就是一个迭代器,在遍历的同时,设置不同的条件,达到不同的过滤,修改,删除等效果
- 可以看到lab1中的
SeqScan也属于该抽象类下的实现类,迭代遍历表
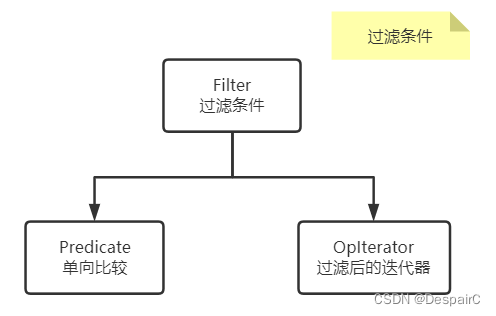
条件过滤
很简单的一个结构,就是进行遍历然后根据条件过滤,与SQL中的where条件相同
- 所实现的效果就是 where a < 5,那么大于5的所有值都会被去除
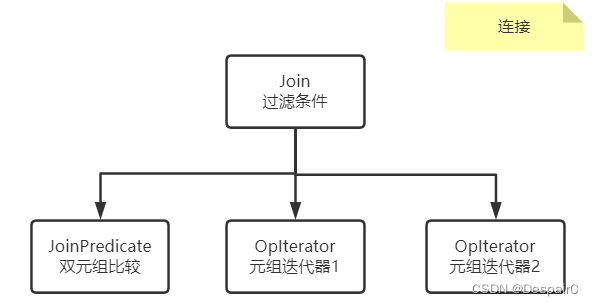
连接
名字和SQL中都一样,就是实现左联右连,自然连接的功能
- 遍历第一个元组,以每个元素为基础和第二个元组进行比较,符合的留下
- 构建新的TupleDesc 表结构,笛卡尔积后的结果加上条件限制符号
新增
插入功能实现原理就是在表的尾部,插入迭代器中的所有元组
同时构建新的TupleDesc返回插入完成后的结果(这个就类似于提醒你插入完成了多少条)和下图类似

如果要显示出来的话,就需要一个TupleDesc结构,列名是rows,列属性是int
删除
删除和插入同理,同样是删除迭代器中有的元组
持久化和缓冲池
由于引入了新增的操作,所以之前的HeapPage引入脏页的概念,当页面脏了之后,需要进行页面刷盘到磁盘中,同时要更新缓冲池BufferPoll中的页面
只是需要简单增加一个标记位 markDirty,并且修改缓冲池逻辑,就不贴图了
查询的流程
模拟的SQL语句
SELECT *
FROM some_data_file1,some_data_file2
WHERE some_data_file1.field1 = some_data_file2.field1AND some_data_file1.id > 1
具体的过程可以看 lab2实验
流程:
- 将表加载到数据库 lab1有说到
- 创建两个查询 SeqScan 得到两个表的迭代器
SeqScan ss1 = new SeqScan(tid, table1.getId(), "t1");SeqScan ss2 = new SeqScan(tid, table2.getId(), "t2"); - 对表1进行条件过滤
// 过滤 table1 的值,过滤条件是 > 1 Filter sf1 = new Filter(new Predicate(0,Predicate.Op.GREATER_THAN, new IntField(1)), ss1); - 以表1为基础,进行表的连接
// 确定要双方要连接的字段 JoinPredicate p = new JoinPredicate(1, Predicate.Op.EQUALS, 1); Join j = new Join(p, sf1, ss2); - 连接完成后得到的
Join,使用Join的迭代器遍历连接后的结果
lab3 直方图
整体架构
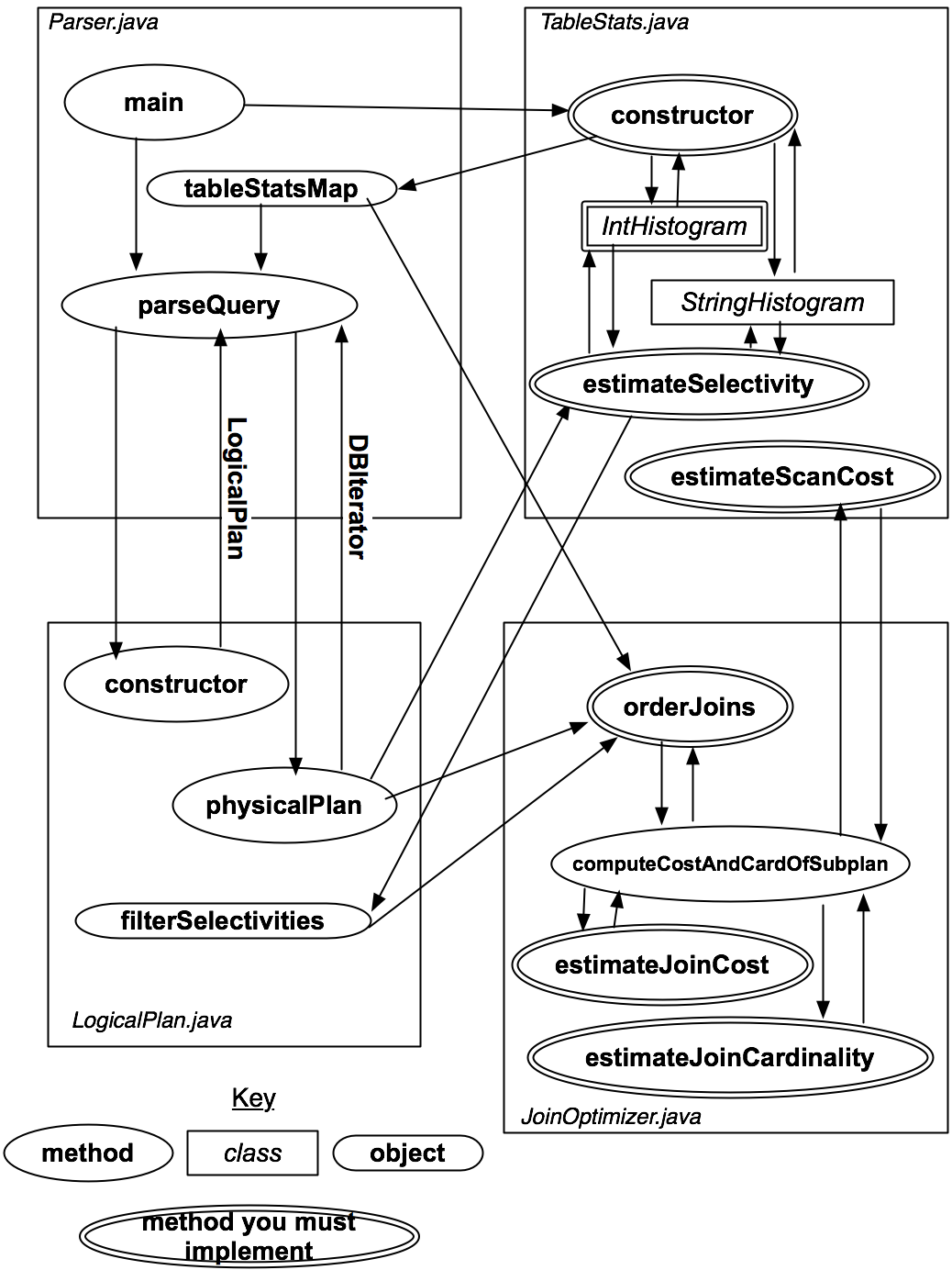
简单看一下过程
- main 方法调用构建 TableStates,也就是各个表对应列的直方图
- 执行查询条件,构建调用 LogicalPlan
- LogicalPlan 就是编排方法的一个类
- 首先去调用 TableStates 拿到要查询表直方图,根据直方图获取相对应的选择率
- 将获取到的选择率放入Map中,构建调用 orderJoins
- orderJoins 根据选择率计算出基数,根据IO 和 扫描次数(基数)作为代价运算公式参数
- 选取最佳的连接运算基数,得到最佳的查询方案
基数(cardinality)和选择性(selectivity)
概念
-
基数:某一列,不同唯一键的数量
比如:有一个一万行的表,它的sex列只有男和女这两个值,那么,这列的基数便是2了。所以主键列的基数等于表的行数
基数越高,说明这个列重复数据越少;相反基数越低,说明列的重复值越多。-- 基数 select count(distinct column_name) from table_name -
选择性 = 基数 / 行数
上面所说的 sex 列,选择性是 2 / 10000 = 0.0002-- 选择性 select count(distinct column_name) / count(column_name) from table_name
作用:
- 基数和选择性有时候也是被当作是否建立索引的判断之一,对一个列来说,基数和选择性越高的列便越适合建立 Btree 索引。
- CBO 用选择率来估算对应结果集合的基数
- 判断这个列适不适合建索引。 选择性约好的列越适合建索引。 当某个列选择性大于20%的时候,这个列就适合建索引。
优化器
基于规则的优化器 RBO
Rule-Based Optimization ,按照硬编码在数据库中的一些系列规则来决定SQL的执行计划
比如 MySQL 中的条件优化(省略括号,常量替换),子查询优化,外连接消除,索引优于全表等规则
虽然是一套规则,但是MySQL并不是完全基于RBO的,是RBO和CBO混合使用的,会混合使用选择最优的方案
基于代价的优化器 CBO
Cost-Based Optimization,该优化器通过根据优化规则对关系表达式进行转换,生成多个执行计划,然后CBO会通过统计信息(Statistics)和代价模型(Cost Model)计算各种可能执行计划的代价,即 Cost,从中选用 Cost 最低的执行方案,作为实际运行方案
在本实验中,所要实现的就是CBO的流程
- 利用表的统计数据(直方图),来估计不同查询计划的 cost
(cost 与 join、 selection 的基数、filter 的选择率和 join 的谓词有关) - 使用数据来对 join 和 select 进行排序,并选择最佳的实现方式
实现内容
使用表的统计数据(直方图)去估计不同查询计划的代价。通常,查询计划的代价与中间进行连接和选择产生的记录数的基数,以及过滤和连接的选择性有关
直方图
内容
根据初始化好的直方图
直方图的含义就是对表的某一个字段构建的图形
所以说x轴上是不同的值,y轴上是值出现的次数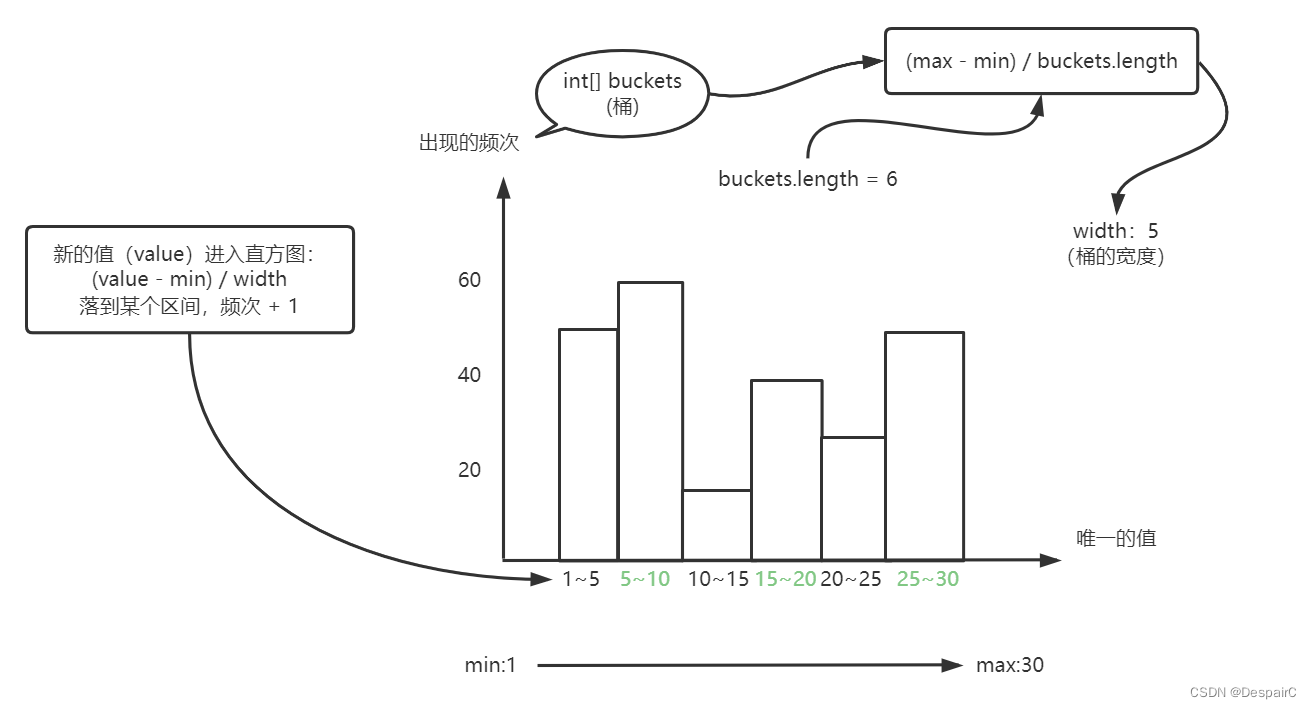
所以在代码层面需要储存的就是 buckets,min, max, width,总记录数tupleCount(这个在图中没体现,就是记录的行数)
public class IntHistogram{// 直方图桶private int[] buckets;// 边界最小值private int min;// 边界最大值private int max;// 宽度private double width;// 行数private int tuplesCount = 0;......}
作用:计算选择率
在储存了直方图之后,就可得出在某一个区间内,所出现的出现的频次,就可以根据此去计算选择率。
计算过程如下:
等值运算:理解为为桶数量中该值的选择率(比如 8 的记录数即为 5~10的记录数 / 5),假设传进来的 value = const,第一步是去寻找包含该值的对应桶(value / width),找到桶之后,计算选择率:选择率 = 对应桶的记录数(buckets[value / width]) / 桶的宽度 width / 记录总数
举例:寻找 8 的记录数,沿用上图做例子,value = 8,找到对应的桶 8 / 5 = 1(这里不要四舍五入),选择率 = 对应桶的值 buckets[1] / width 5 / 总记录数 tuplesCount
非等值运算:同理,value > const的选择率 = (value > const的记录数) / 记录总数,计算 const 所在的桶部分面积 + 后面桶的面积,这里面积可以理解为记录数,所以 value > const的记录数 = (b_right - const) * (h_b / w_b) + 后面的桶面积 要注意开区间和闭区间的区别(具体可看下图)
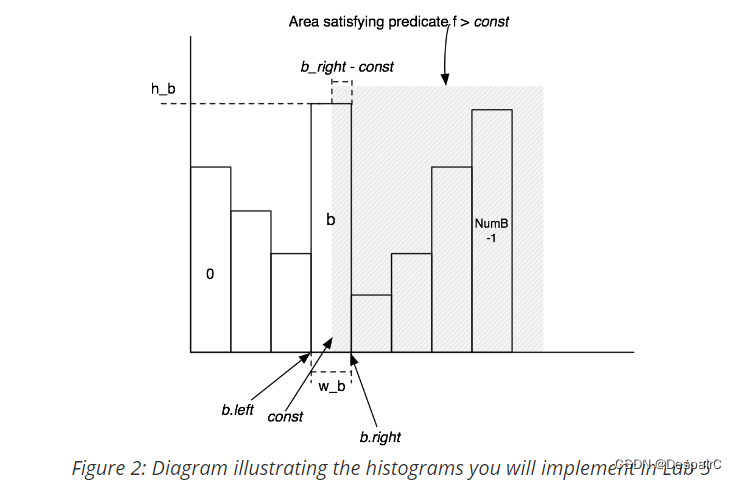
由上面两个公式,就可以得到等值或非等值的选择率,从而决定优化的方向
直方图与表的关系
对表中的每个字段建立一个直方图,利用Map映射,key为字段, value为直方图
再对多个表建立映射,key为表别名,value为表的多个直方图
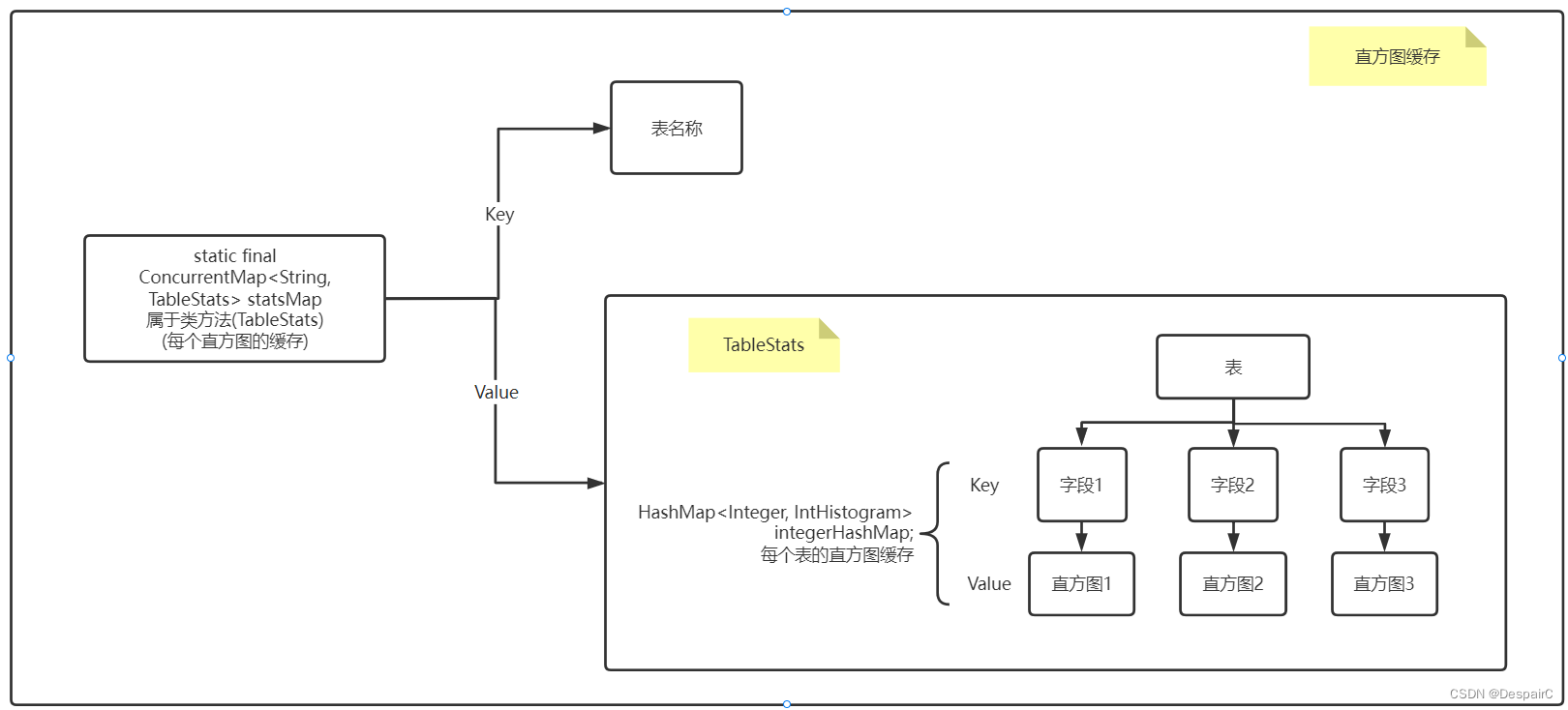
构建关系
- 遍历每个表
- 遍历每一行(行式储存,所以是按行遍历)
- 遍历每一字段,根据字段类型选择构建(String、Int)
- 将对应值添加到直方图
连接优化
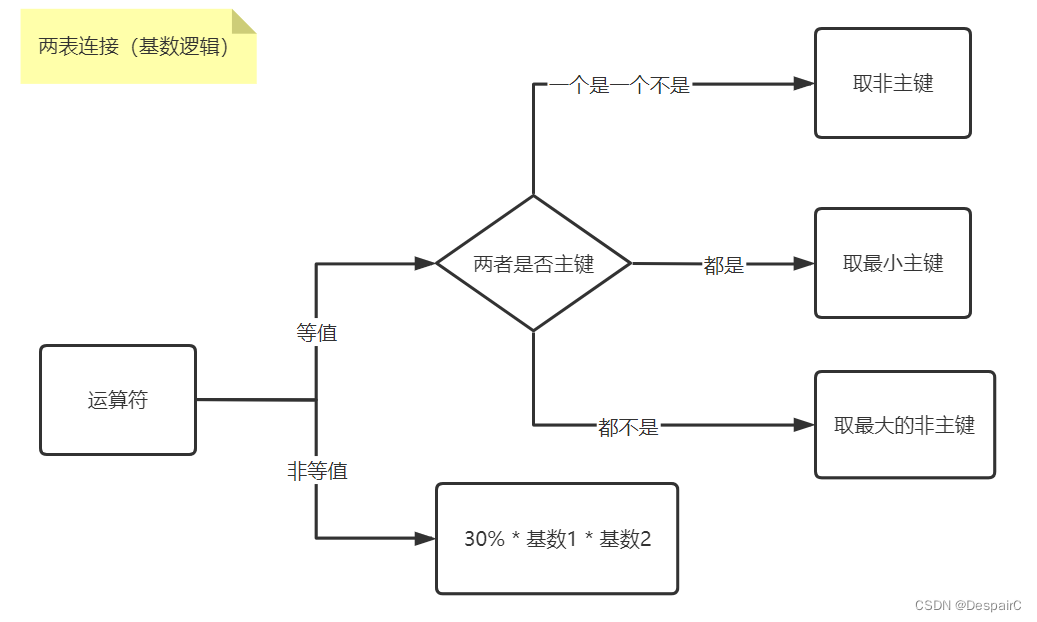
上述的选择率和这一层的关系就是,基数 = 选择率 * 行数
估算连表花费的成本(card:基数, cost IO成本)
- 公式 = IO 成本(表1 检索成本 + 每一行都需要检索 表2) + CPU成本(总共的扫描次数)
- cost = cost1 + card1 * cost2 + card1 * card2
根据两表的连接基数判断选择哪个为初始
- card1 和 card2 选哪个为连接的表1?
lab4 事务和锁
两段锁协议
并发控制:在共享系统中,多个用户对同一共享资源进行访问
调度:事务执行的次序
串行调度:多个事务依次顺序执行,排队执行,只有当上一个事务处理完了之后,下一个事务才能够处理
并行调度:利用分时的方法同时处理多个事务,比如A线程执行了一半,时间片使用完,轮转到下一线程B;因此可能会产生不一致的状态,会产生数据库常见的错误:丢失修改、不可重复读、脏读和幻读等问题
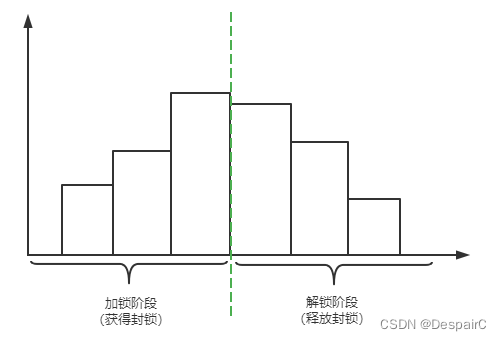
两段锁协议:是指所有事务必须分为两个阶段对数据项进行加锁和解锁。
- 第一个阶段:获取封锁的阶段,称为拓展阶段
- 事务可以申请获得任何数据项上任何类型的锁,但是不能释放任何锁
- 当获取不到锁的时候,就需要等待循环尝试
- 第二个阶段:释放封锁得阶段,称为收缩阶段
- 事务可以释放数据项上任何类型的锁,但是不能再申请锁
举个例子说明:
事务A 遵循两端锁协议,其封锁序列是:
这里的1~5属于获取封锁阶段,6~9属于释放封锁阶段
1 Lock A
2 Read A
3 A := A + 10
4 Write A
5 Lock B
6 UnLock A
7 Read B
8 UnLock B
9 Commit
若所有并发事务都遵守两端锁协议,则对这些事务的任何并发策略都是可串行化的
- 意思就是多个事务并发执行结果是不变的,幂等的:任意多次执行所产生的影响均与一次执行的影响相同
事务锁逻辑
加锁阶段
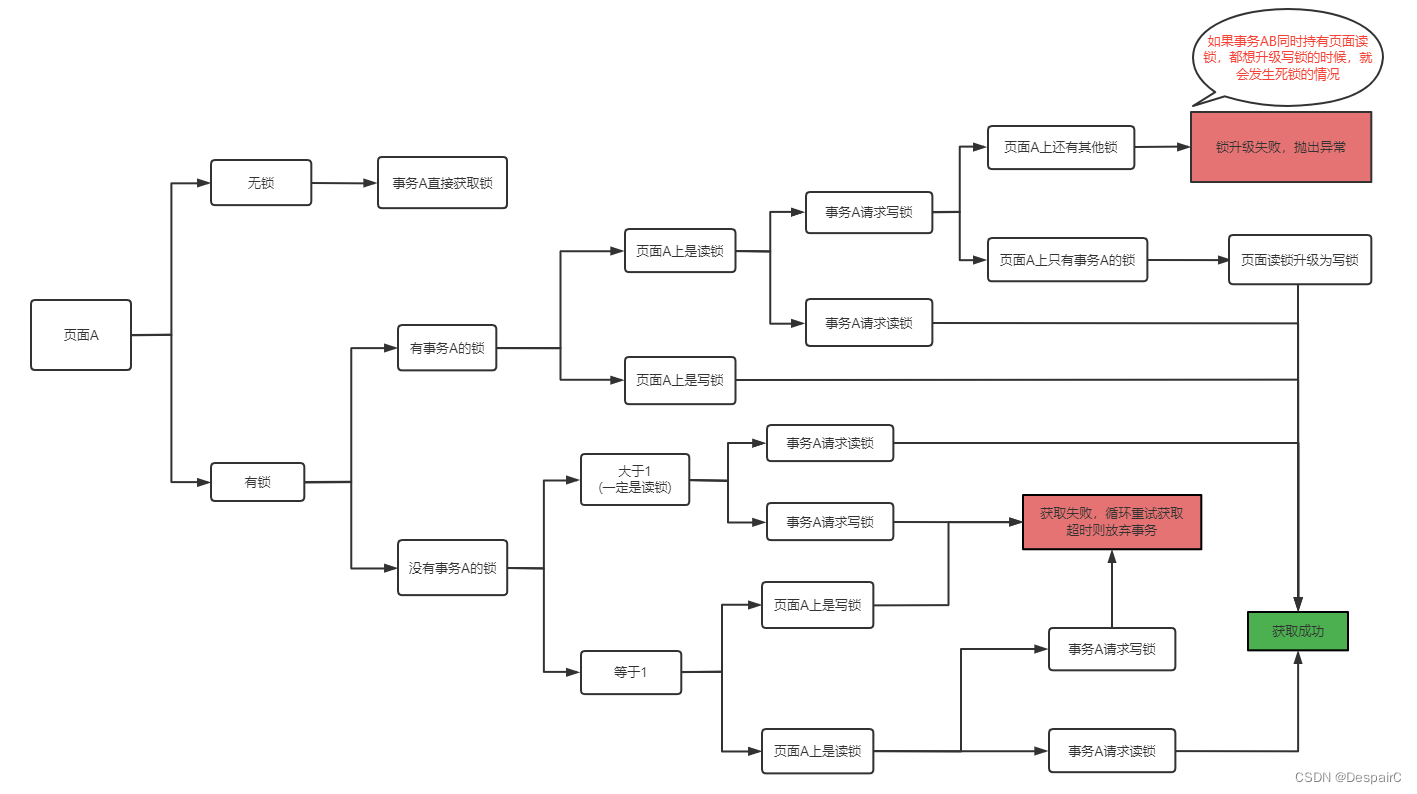
图中加锁逻辑已经足够清晰,这里再解释下某些原理
在已请求读锁的情况下,再去请求写锁,为何要进行锁升级?
- 答案是的,写锁的级别是比读锁高的,如果不进行锁升级的话,会导致其他事务依旧能够进来读取数据,所以说锁的升级是必要的。
- 但当有多个读锁的时候,不能够对其进行锁升级,因为不仅要驱散原有的读锁,而且假设有另一个读锁也要进行升级,加入循环尝试锁升级的话,事务A不释放读锁,事务B不释放读锁,那么两者都不能够进行锁升级。此时的解决方案有:
- 抛出异常,本文的处理方式
- 循环尝试获取写锁,当且仅当其他读锁消失,进行锁升级
除了逻辑图中的内容,还需要注意,循环尝试的频率和耗时,在限定一段时间后,如果仍然不能够获取到锁,就要尝试放弃这个事务。所以超时机制是必要的
解锁阶段
解锁的时机,遵循两段锁协议,当所有的加锁都完成了,就可以开始进入解锁阶段
这里统一为当事务准备提交的时候,释放该事务的所有锁
事务和脏页
当事务还没有完成提交的时候,不能够进行脏页的刷新,也就是脏页不能够刷新到文件当中
此时的脏页在缓存
事务回滚
MySQL中有 定期刷盘、提交事务后就刷盘等的机制
这里我采用的是提交事务后刷盘的机制
提交成功:
- 当事务完成了,对缓存中的页面进行遍历
- 如果该页面属于该事务
- 进行刷盘到文件
但如果提交失败。进行页面回滚,道理一样
- 对缓存中的页面进行遍历
- 如果页面属于该事务,重新读取页面
- 更新缓存
lab5 B+树
结构
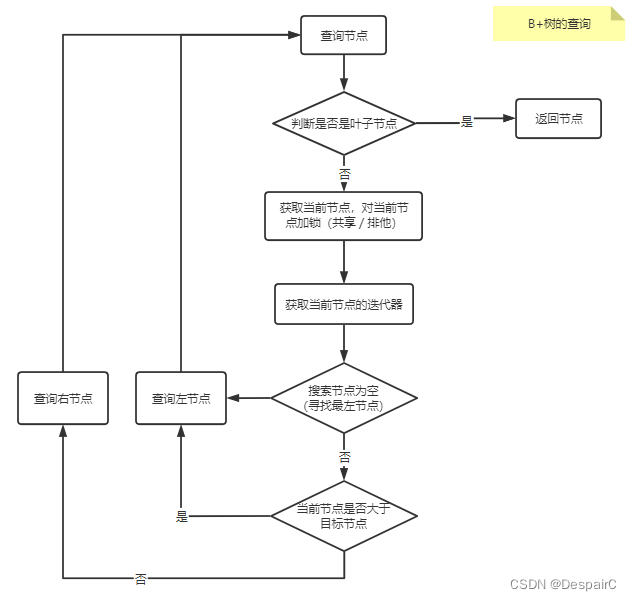
查询
插入
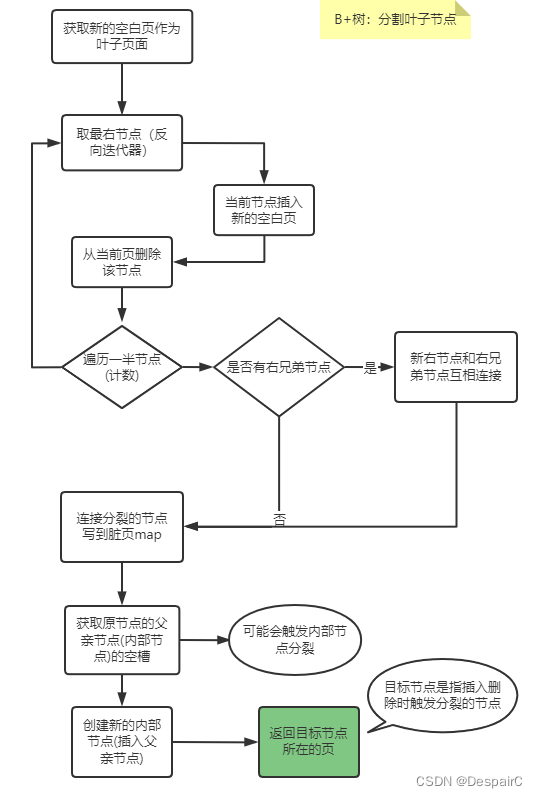
分裂叶子节点
分裂内部节点
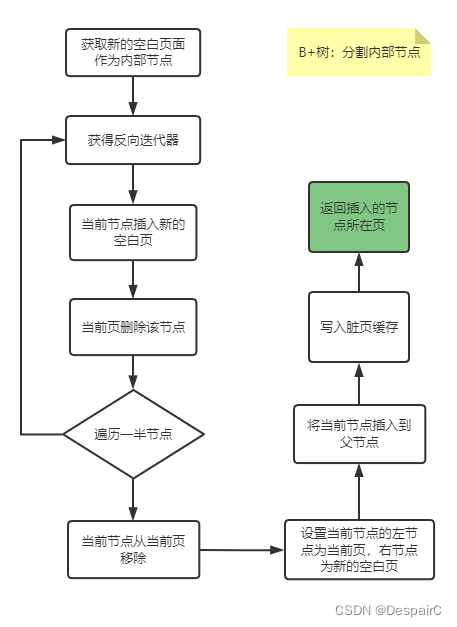
代码实现文章
Mit 6.830:SimpleDB Lab1
Mit 6.830:SimpleDB Lab2
Mit 6.830:SimpleDB Lab3
Mit 6.830:SimpleDB Lab4
Mit 6.830:SimpleDB Lab5
参考文章
Mit6.830-SimpleDB-Lab3-查询优化-学习笔记
基数、选择性、直方图
基数与选择性
两段锁协议
Mit6.830-SimpleDB-Lab4-事务-学习笔记
这篇关于Mit 6.830:SimpleDB 总结篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





