本文主要是介绍【MIT6.S081/6.828】Lab util: Unix utilities,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. sleep
- 1.1 实验要求
- 1.2 代码实现
- 1.3 测试
- 2. pingpong
- 2.1 实验要求
- 2.2 分析
- 2.3 代码实现
- 2.4 测试
- 3. primes
- 3.1 实验要求
- 3.2 代码实现
- 3.3 测试
- 4. find
- 4.1 实验要求
- 4.2 ls代码分析
- 4.3 代码实现
- 4.4 测试
- 5. xargs
- 5.1 实验要求
- 5.2 代码实现
- 5.3 测试
哈喽,大家好,我是仲一。本篇文章是从零实现操作系统的第一个实验,主要是让我们熟悉 xv6 及其系统调用。做实验以前,建议先阅读下xv6 书籍的第一章。另外,在官网的实验手册中,给出了一些提示,会一步一步引导你完成实验。
1. sleep
1.1 实验要求
实现 UNIX 程序 的sleep,使进程睡眠若干个滴答周期(滴答是 xv6 内核定义的时间概念,即来自定时器芯片的两次中断之间的时间。)。代码在 user/sleep.c 中实现。
提示:
- 查看
user/中的其他一些程序,了解如何获取传递给程序的命令行参数。如果用户忘记传递参数, sleep 应该打印一条错误消息。 - 命令行参数作为字符串传递;可以使用
atoi将其转换为整数(参考 user/ulib.c)。 - 使用系统调用
sleep(参考 user/usys.S 和 kernel/sysproc.c)。 - 确保
main调用exit()以退出程序。 - 将程序添加到Makefile 中的
UPROGS并通过键入make fs.img编译用户程序。
预期:
$ make qemu
...
init: starting sh
$ sleep 10
(nothing happens for a little while)
$
1.2 代码实现
直接调用系统的sleep函数即可。
int main(int argc, char *argv[]){if(argc != 2){fprintf(2, "usage: sleep time\n");exit(1);} else {int time = atoi(argv[1]);sleep(time);exit(0);}
}
1.3 测试

2. pingpong
2.1 实验要求
使用 UNIX 系统调用在两个进程之间通过一对管道“pingpong”一个字节,每个管道一个。父级通过向parent_fd[1]写入一个字节发送,子级通过从parent_fd[0]读取来接收它。从父级收到一个字节后,子级通过写入child_fd[1]以自己的字节进行响应,然后父级读取该字节。代码在文件user/pingpong.c 中实现。
提示:
- 使用
pipe创建管道。 - 使用
fork创建一个孩子。 - 使用
read从管道读取,并使用write写入管道。
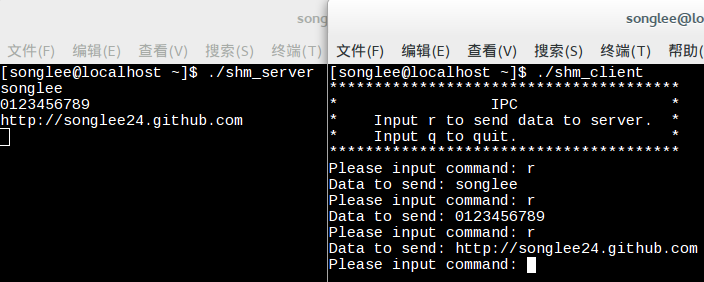
效果:
$ make qemu
...
init: starting sh
$ pingpong
4: received ping
3: received pong
$
2.2 分析
要解决这个问题,首先要理解管道是什么。下面看下,xv6 book中对管道的定义。
管道是一个小的内核缓冲区,它以文件描述符对的形式提供给进程,一个用于写操作,一个用于读操作。从管道的一端写的数据可以从管道的另一端读取。管道提供了一种进程间交互的方式。
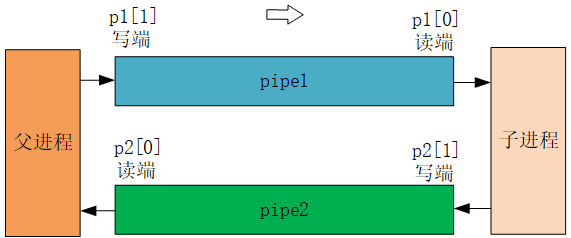
以下这段代码运行了程序 wc,并把它的标准输出绑定到了一个管道的读端口。
int p[2];
char *argv[2];
argv[0] = "wc";
argv[1] = 0;
pipe(p); //创建一个新的管道并且将读写描述符记录在数组 p 中
if(fork() == 0) {
//unix里面,一切皆文件,所以stdin stdout都可以看成是文件close(0); //关闭stdin, 对应文件描述符0,这样0就空出来了dup(p[0]); // 把p[0]拷贝到0,因为0已经关闭了(或者说0号位置空缺),这样wc就从管道的p[0]读取数据,而不是stdinclose(p[0]);close(p[1]);exec("/bin/wc", argv);
} else {write(p[1], "hello world\n", 12);close(p[0]);close(p[1]);
}
这段程序调用 pipe,创建一个新的管道并且将读写描述符记录在数组 p 中。在 fork 之后,父进程和子进程都有了指向管道的文件描述符。子进程将管道的读端口拷贝在描述符0上,关闭 p 中的描述符,然后执行 wc。当 wc 从标准输入读取时,它实际上是从管道读取的。父进程向管道的写端口写入然后关闭它的两个文件描述符。
2.3 代码实现
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"int main(int argc, char *argv[]){int parent_fd[2], child_fd[2];pipe(parent_fd);pipe(child_fd);char buf[1];if(fork() == 0){close(parent_fd[1]);// 关闭管道parent_fd[1] 因为我们要读取parent_fd[0],管道是单工的,读写端口不能被同时开启。close(child_fd[0]);// 为什么要关掉child_fd[0] 我的理解是,如果要写入到child_fd[1],避免一写入就被读取,那么我们就要关闭child_fd[0],读写不能被同时开启。if(read(parent_fd[0],buf,1))//读取父进程发过来的消息,而父进程是通过write(parent_fd[1])来写入到parent_fd缓冲区的,然后在读端口被子进程读到fprintf(1,"%d: received ping\n",getpid());//子进程写入write(child_fd[1],"B",1);close(child_fd[1]);} else {close(parent_fd[0]);close(child_fd[1]);//父进程写入write(parent_fd[1],"A",1);//父进程接收if(read(child_fd[0],buf,1))fprintf(1,"%d: received pong\n",getpid());close(parent_fd[1]);}exit(0);
}
2.4 测试

3. primes
3.1 实验要求
primes的功能是输出2~35之间的素数。这道题比较有意思,具体如下图。
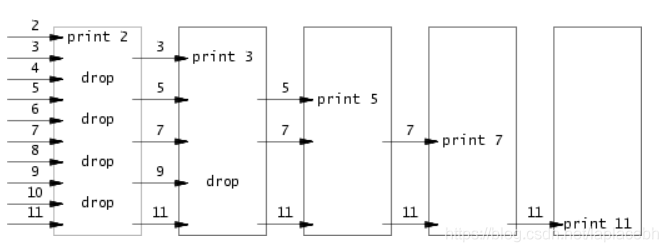
每个框代表一个进程,进程之间管道通信,对于每个进程,输出收到的第一个数记为p,这个数必定为素数,之后收到的每个数如果是第一个数p的倍数,丢弃,反之发送给下一个进程。就是每个进程输出一个素数。
提示:
- 及时关闭进程不需要的文件描述符,否则将会耗尽系统内存。
- 一旦第一个进程达到 35,您应该安排管道终止,包括所有子进程(提示:当管道的写端关闭时,读取将返回文件结束)。
- 将 32 位
int写入管道是最简单的,而不是使用格式化的 ASCII I/O。
预期:
$ make qemu
...
init: starting sh
$ primes
prime 2
prime 3
prime 5
prime 7
prime 11
prime 13
prime 17
prime 19
prime 23
prime 29
prime 31
$
3.2 代码实现
每个进程收到的第一个数p一定是素数,后续的数如果能被p整除则之间丢弃,如果不能则输出到下一个进程。
#include "kernel/types.h"
#include "user/user.h"void process(int p[])
{close(p[1]);int prime;if (read(p[0], &prime, 4) > 0) {fprintf(1, "prime %d\n", prime);int p2[2];pipe(p2);if (fork() > 0) {close(p2[0]);int i;while(read(p[0], &i, 4) > 0) {if (i % prime != 0) {write(p2[1], &i, 4);}}close(p2[1]);wait(0);} else {close(p[0]);process(p2);}}
}int
main(int argc, char* argv[])
{int p[2];pipe(p);int pid = fork();if (pid > 0) { // parentclose(p[0]);fprintf(1, "prime 2\n");for (int i = 3; i <= 35; ++i) {if (i % 2 != 0) {write(p[1], &i, 4);}}close(p[1]);wait(0);} else {process(p);}exit(0);
}
3.3 测试

4. find
4.1 实验要求
编写一个简单版本的 UNIX 查找程序:在目录树中查找名称与字符串匹配的所有文件。代码在文件user/find.c中实现。
提示:
- 查看 user/ls.c 以了解如何读取目录。
- 使用递归允许查找下降到子目录。
- 不要递归到“。” 和 ”…”。
预期:
$ make qemu
...
init: starting sh
$ mkdir a
$ echo > a/b
$ find . b
./a/b
$
4.2 ls代码分析
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"char*
fmtname(char *path)
{static char buf[DIRSIZ+1];char *p;// Find first character after last slash.for(p=path+strlen(path); p >= path && *p != '/'; p--);p++;// Return blank-padded name.if(strlen(p) >= DIRSIZ)return p;memmove(buf, p, strlen(p));memset(buf+strlen(p), ' ', DIRSIZ-strlen(p));return buf;
}void
ls(char *path)
{char buf[512], *p;int fd;struct dirent de; //这个指的是目录项这一结构体(在kernel/fs.h中定义),其实目录也是一种文件,里面就是存放了一系列的目录项struct stat st; //这个指的是文件的统计信息(在kernel/stat.h中定义),包含文件类型(目录或文件)/inode/文件引用nlink/文件大小/存放fs的disk devif((fd = open(path, 0)) < 0){ //打开文件,第二个参数指示的是打开方式,0代表的是O_RDONLY只读的形式。返回值是file descriptor >=0,<0说明open失败fprintf(2, "ls: cannot open %s\n", path);return;}if(fstat(fd, &st) < 0){ //fstat的含义同open类似fprintf(2, "ls: cannot stat %s\n", path);close(fd);return;}switch(st.type){ //switch 中主要是两个逻辑,一个是文件如何处理,一个是目录怎么处理case T_FILE: //如果是文件,直接打印信息printf("%s %d %d %l\n", fmtname(path), st.type, st.ino, st.size);//st.type中三个值分别是({1:目录,2:文件,3:console}) fmtname返回值就是文件名称break;case T_DIR:if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){ //检查缓存有没有溢出printf("ls: path too long\n");break;}strcpy(buf, path); p = buf+strlen(buf);*p++ = '/'; //拼接字符串,以路径名访问这个目录里面的内容while(read(fd, &de, sizeof(de)) == sizeof(de)){ //访问目录内容。每次read只是read一个de的大小(也就是一个目录项),只有read到最后一个目录项的下一次read才会返回0,也就不满足while循环条件退出循环,if(de.inum == 0) //此文件夹无文件,continue操作后进行下一次read continue;memmove(p, de.name, DIRSIZ); //memmove为内存之间的迁移,在ls.c里面的意思就是将de.name的内容移动到p指向的指针中p[DIRSIZ] = 0;if(stat(buf, &st) < 0){printf("ls: cannot stat %s\n", buf);continue;}printf("%s %d %d %d\n", fmtname(buf), st.type, st.ino, st.size);}break;}close(fd);
}int
main(int argc, char *argv[])
{int i;if(argc < 2){ls("."); //默认展示当前工作目录的所有文件exit(0);}for(i=1; i<argc; i++)ls(argv[i]); //ls 和我们熟知的linux的ls是不太相同的,xv6的ls是可以接受多个目录作为参数的exit(0);
}//kernel/fs.h
struct dirent {ushort inum;char name[DIRSIZ];
};//kernel/stat.h
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Devicestruct stat {int dev; // File system's disk deviceuint ino; // Inode numbershort type; // Type of fileshort nlink; // Number of links to fileuint64 size; // Size of file in bytes
};
4.3 代码实现
直接参考ls源码修改就好,注意控制buf结束符’\0’的位置。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"char*
fmtname(char *path) //格式化名字,把名字变成前面没有左斜杠/,仅仅保存文件名
{static char buf[DIRSIZ+1];char *p;// Find first character after last slash.for(p=path+strlen(path); p >= path && *p != '/'; p--);p++;// Return blank-padded name.memmove(buf, p, strlen(p) + 1);return buf;
}void
find(char *path, char* findName)
{char buf[512], *p;int fd;struct dirent de;struct stat st;if((fd = open(path, 0)) < 0){fprintf(2, "find: cannot open %s\n", path);return;}if(fstat(fd, &st) < 0){fprintf(2, "find: cannot stat %s\n", path);close(fd);return;}switch(st.type){case T_FILE:// 如果是文件类型,那么比较,文件名是否匹配,匹配则输出if(strcmp(fmtname(path), findName) == 0)printf("%s\n", path);break;case T_DIR://如果是目录则递归去查找if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){printf("find: path too long\n");break;}strcpy(buf, path);p = buf+strlen(buf);*p++ = '/';//buf是一个绝对路径,p是一个文件名,并通过加"/"前缀拼接在buf的后面while(read(fd, &de, sizeof(de)) == sizeof(de)){if(de.inum == 0) {continue;}memmove(p, de.name, DIRSIZ);//memmove, 把de.name信息复制p,其中de.name是char name[255],代表文件名p[strlen(de.name)] = 0; // 设置文件名结束符if(strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0) {continue;}find(buf, findName);}break;}close(fd);
}int
main(int argc, char *argv[])
{if(argc < 3){printf("error argc num");exit(0);}find(argv[1], argv[2]);exit(0);
}
4.4 测试

5. xargs
5.1 实验要求
编写一个简单版本的 UNIX xargs 程序:从标准输入中读取行并为每一行运行一个命令,将该行作为命令的参数提供。代码在文件user/xargs.c中实现。
提示:
- 使用
fork和exec系统调用在每一行输入上调用命令。在 parent 中使用wait等待 child 完成运行命令。 - 从 stdin 读取一个字符,直到换行符 (’\n’)。
- kernel/param.h 声明了 MAXARG,声明一个 argv 时会用到。
预期:
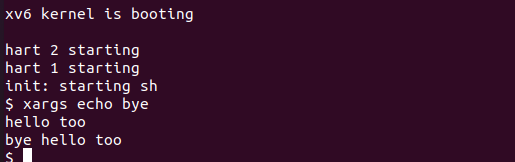
$ xargs echo byehello toobye hello tooctrl-d$
5.2 代码实现
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/param.h"#define MAXN 1024int main(int argc, char *argv[])
{if (argc < 2){fprintf(2, "usage: xargs command\n");exit(1);}char *_argv[MAXARG]; // 存放子进程exec的参数for (int i = 1; i < argc; i++) // 略去xargs,第一个参数必须是该命令本身_argv[i - 1] = argv[i];char buf[MAXN]; // 存放从标准输入转化而来的参数char c = 0;int stat = 1; // 从标准输入read返回的状态while (stat) // 标准输入中还有数据{int buf_cnt = 0; // buf尾指针int arg_begin = 0; // 当前这个参数在buf中开始的位置int argv_cnt = argc - 1;while (1) // 读取一行{stat = read(0, &c, 1); //从标准输入中读取if (stat == 0) // 标准输入中没有数据,exitexit(0);if (c == ' ' || c == '\n'){buf[buf_cnt++] = 0; //最后一个参数必需为0,否则会执行失败_argv[argv_cnt++] = &buf[arg_begin];arg_begin = buf_cnt; if (c == '\n')break;} else{buf[buf_cnt++] = c;}}_argv[argv_cnt] = 0; //结束标志if (fork() == 0){exec(_argv[0], _argv);}else{wait(0);}}exit(0);
}
5.3 测试
https://blog.csdn.net/laplacebh/article/details/117518581
https://blog.csdn.net/newbaby2012/article/details/118880546
https://blog.csdn.net/zhayujie5200/article/details/106600925/
https://blog.csdn.net/u013577996/article/details/108680888
https://www.zhihu.com/people/wei-rainclear/posts
这篇关于【MIT6.S081/6.828】Lab util: Unix utilities的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!