本文主要是介绍顶会热词统计系统的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
成品展示
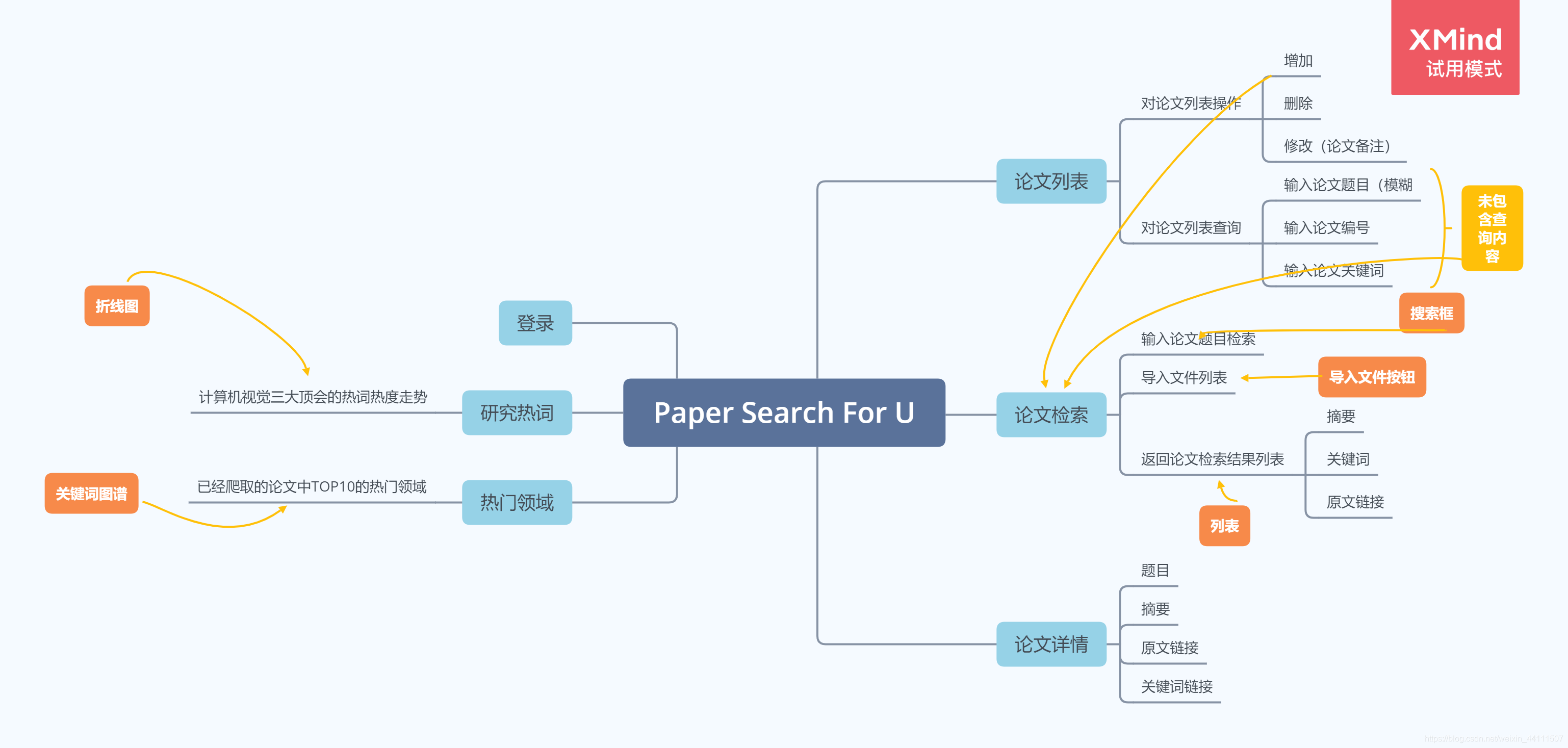
- 可对论文列表进行查询
- 可对论文列表进行删除;
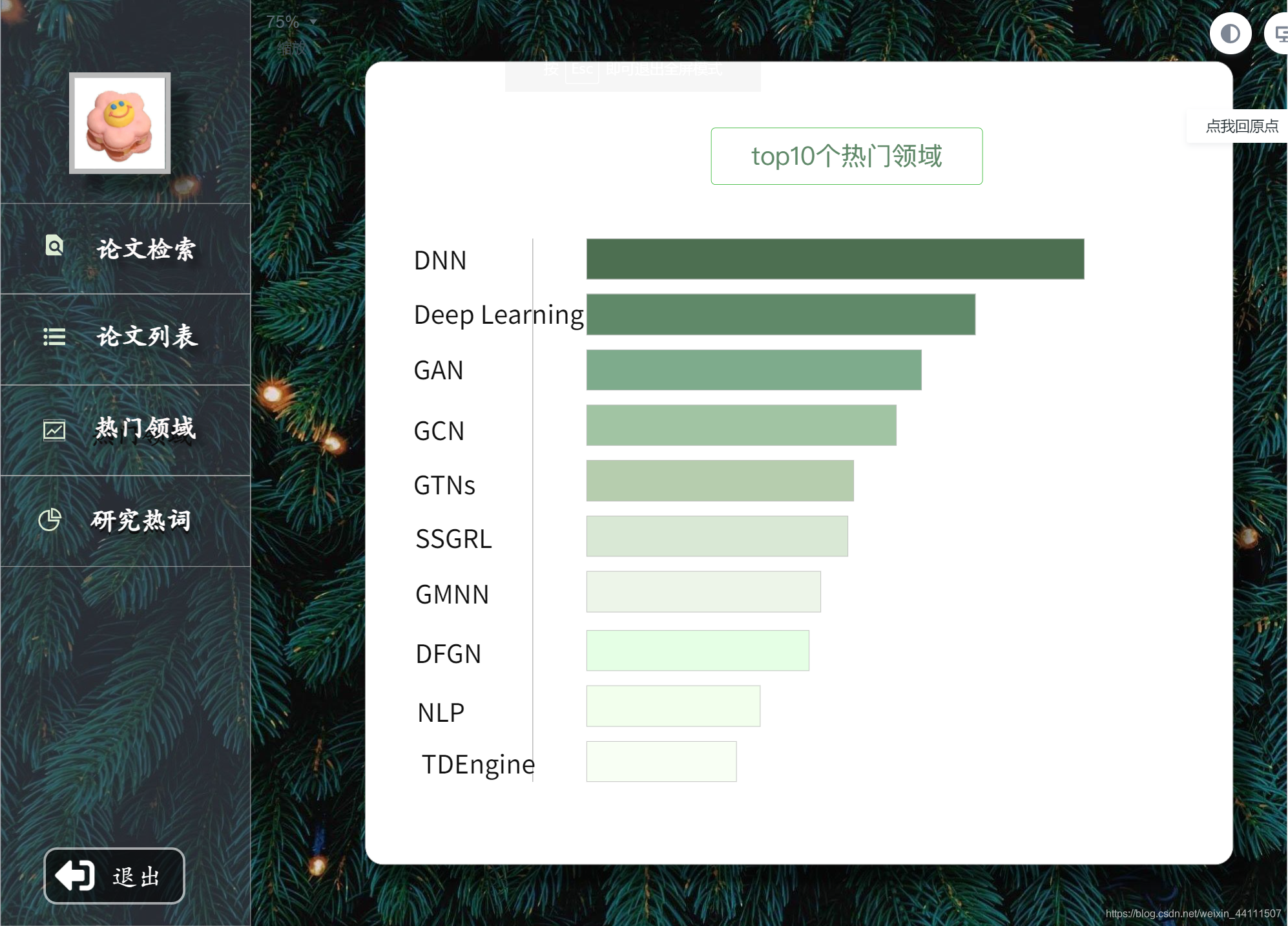
- 分析论文信息,提取top10个热门领域,形成关键词图谱,点击某个关键词可展现相关的论文
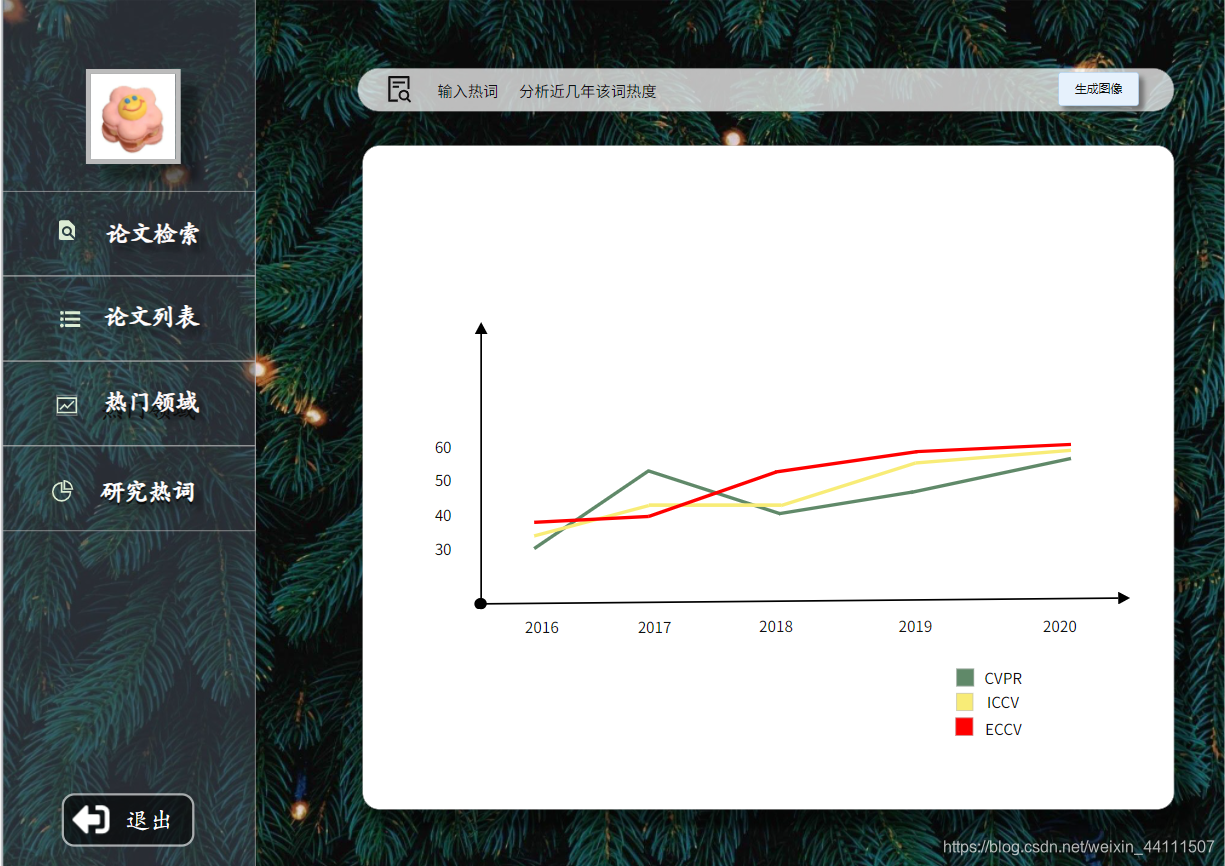
- 对多年间,ECCV顶会的热词呈现热度走势对比

描述设计实现
使用MVC开发流程实现项目架构,利用Servlet+JSP+Jdbc的功能开发流程。
代码说明
数据库设计
CREATE TABLE `paperslist` (`id` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`abstracts` varchar(8191) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`conference` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`keyword` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`time` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`link` varchar(8191) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
代码设计
从json文件夹取出数据
public void readECCVFileContent(String path) throws FileNotFoundException {String key = "";items item = new items();JSONReader reader=new JSONReader(new FileReader(path));//开始解析最外层的对象reader.startObject();//遍历最外层的对象while (reader.hasNext()){String longkeyword = "";key = reader.readString(); //读取键的值if(key.equals("摘要")){String abstracts = reader.readObject().toString();item.setAbstracts(abstracts);}else if(key.equals("会议和年份")){String conference = reader.readObject().toString();item.setConference(conference);}else if(key.equals("关键词")){reader.startArray();//开始解析数组while (reader.hasNext()){String keyword = reader.readString();longkeyword += keyword;longkeyword += ",";}item.setKeyword(longkeyword);reader.endArray();}else if(key.equals("发布时间")){String time = reader.readObject().toString();item.setTime(time);}else if(key.equals("论文名称")){String title = reader.readObject().toString();System.out.println("论文:" + title);item.setTitle(title);}else if(key.equals("原文链接")){String link = reader.readObject().toString();item.setLink(link);}}try {Connection conn = DBHelper.getConnection();saveDataToDb(conn,item);} catch (Exception e) {// 省略}reader.endObject();}
解释思路:
其实刚开始拿到json数据还是有点头痛,怎么把数据取出来还是有点困难,于是上网搜索,觉得使用JSONReader来读数据在一层一层遍历解析。第一次拆Json数据,花费了很多时间调试。
获取所有论文信息
public ArrayList<items> getAllItems() {Connection conn = null;PreparedStatement stmt = null;ResultSet rs = null;// 论文集合ArrayList<items> list = new ArrayList<items>(); try {conn = DBHelper.getConnection();String sql = "select * from paperslist;";stmt = conn.prepareStatement(sql);rs = stmt.executeQuery();while (rs.next()) {items item = new items();item.setId(rs.getString("id"));item.setAbstracts(rs.getString("abstracts"));item.setConference(rs.getString("conference"));item.setKeyword(rs.getString("keyword"));item.setTime(rs.getString("time"));item.setTitle(rs.getString("title"));item.setLink(rs.getString("link"));// 把一个论文加入集合list.add(item);}return list; } catch (Exception ex) {//省略} finally {// 省略}}
解释思路:
items是设计的关于论文的类,位于entity包里,那么从数据库取出数据就是执行sql语句,同样在相同类下也有根据论文标题,论文id搜索返回论文信息的方法,就是执行的sql语句不同。
获取top10热词
public List<Map.Entry<String, Integer>> getHotkw (String str){int num = 0;TreeMap<String, Integer> map = new TreeMap<>();String lowerStr = str.toLowerCase();String[] word = lowerStr.split(",");int len = word.length;String tw = null;for (int i = 0; i < len; i++) {tw = word[i];if (!map.containsKey(tw)) {map.put(tw, 1);} else {num = map.get(tw);map.put(tw, num + 1);}}List<Map.Entry<String, Integer>> hotWords = WordCountMethod.highFreqWord(map);return hotWords;}
解释思路:
上次作业写了wordcount程序,这一次刚好获取的时候可以复用,就想到搬了上一次WordCountMethod.highFreqWord(map)的函数,前期是获取所有论文关键词拼成字符串,再拆成一个个键值对存储在Map中,最后按需获取top的热词。
获取排名前几的热词近几年的数据
public int[] keyYearNum(int kw) {//获取所有关键词String allKw = getKeywordsFromDB();//获取排好序的关键词数据String[] topkw = words(getHotkw(allKw));Connection conn = null;PreparedStatement stmt = null;ResultSet rs = null;int year = 2016;//存储三年该热词出现次数int[] num = new int[3];try {conn = DBHelper.getConnection();for(int i = 0;i < 3;i++) {String sql = "select * from paperslist where conference like ? and keyword like ?;"; stmt = conn.prepareStatement(sql);//模糊查询匹配语句String y = "%" + year + "%";String kw1 = "%"+ topkw[kw] + "%";stmt.setString(1, y);stmt.setString(2, kw1);rs = stmt.executeQuery();while (rs.next()) {num[i]++;}year += 2;}return num;} catch (Exception ex) {//省略} finally {//省略}}
解释思路:
题目要求是多年间顶会的热词呈现热度走势,那么需要热词也要热词数据,其实上一个功能已经取出热词以及排名,那只要取出前几名的热词分别再多年的数据,正好数据中有提供论文发布年份,那就可以用sql条件查询语句,设置关键词和年份两个条件查询符合的论文返回论文数。
servlet处理前端传来请求转发数据
public void doPost(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {response.setContentType("text/html;charset=utf-8");PrintWriter out = response.getWriter();if(request.getParameter("action")!=null){this.action = request.getParameter("action");//如果是添加论文进收藏夹if(action.equals("add")){if(addToCollection(request,response)){request.getRequestDispatcher("/success.jsp").forward(request, response);}else{request.getRequestDispatcher("/failure.jsp").forward(request, response);}}//如果是显示收藏夹if(action.equals("show")){request.getRequestDispatcher("/collection.jsp").forward(request, response);}//如果是执行删除收藏夹的论文if(action.equals("delete")){if(deleteFromCollection(request,response)){request.getRequestDispatcher("/collection.jsp").forward(request, response);}else{request.getRequestDispatcher("/collection.jsp").forward(request, response);}}}}
解释思路:
位于collectionServlet中,用于处理前端收藏,删除,展示收藏夹的请求,传输数据,再重定向到相应jsp页面。
添加论文进收藏夹
private boolean addToCollection(HttpServletRequest request, HttpServletResponse response){String id = request.getParameter("id");String number = request.getParameter("num");items item = idao.getItemsById(Integer.parseInt(id));//是否是第一次给收藏夹添加论文,需要给session中创建一个新的收藏夹对象if(request.getSession().getAttribute("collection")==null){collection collection = new collection();request.getSession().setAttribute("collection",collection);}collection collection = (collection)request.getSession().getAttribute("collection");if(collection.addPaperInCollection(item, Integer.parseInt(number))){return true;}else{return false;}}
//添加论文进收藏夹
public boolean addPaperInCollection(items item ,int number){if(paperlist.containsKey(item)){paperlist.put(item, paperlist.get(item)+number);}else{paperlist.put(item, number); }return true;}
解释思路:
获取前端传来的论文id和num,判断是否第一次给收藏夹添加论文,如果是,就新建一个收藏夹对象,如果不是就收藏文章。方法写在collection类中。
从收藏夹删除论文
private boolean deleteFromCollection(HttpServletRequest request, HttpServletResponse response){String id = request.getParameter("id");collection coll = (collection)request.getSession().getAttribute("collection");items item = idao.getItemsById(Integer.parseInt(id));if(coll.removePaperFromCollection(item)){return true;}else{return false;}}
//从收藏夹移除论文
public boolean removePaperFromCollection(items item){paperlist.remove(item);return true;}
前端jsp实现论文信息显示
<table id="table" ><tr><td><!-- 论文循环开始 --><% ItemsDao itemsDao = new ItemsDao(); ArrayList<items> list = new ArrayList<items>();//如果有获取到key说明是搜索后跳转的页面,就根据收到的key进行模糊搜索返回论文集合if(request.getParameter("key")!=null){list = itemsDao.getItemsByTitle(request.getParameter("key"));}//没有获得key,返回所有论文信息else{list = itemsDao.getAllItems();}if(list!=null&&list.size()>0){for(int i=0;i<list.size();i++){items item = list.get(i);%> <div><dl><dt clsaa="dt_title"><a href="details.jsp?id=<%=item.getId()%>"><%=item.getTitle() %></a></dt><dd class="dd_abstract">abstract: <%=item.getAbstracts() %></dd> <dd class="dd_conference">来源会议: <%=item.getConference() %></dd> </dl></div><!-- 论文循环结束 --><%}} %></td></tr></table>
论文模糊搜索
<form action=""><input type="text" name="key" value="" placeholder="输入论文题目查找 支持模糊查询"><a href="main.jsp?keyword=document.getElementById("key").value"><input type="submit" value="搜索"></a>
</form>
解释思路:
获取输入框的value,作为跳转回首页携带的数据,加载首页时判断是否有携带数据,有则执行函数搜索返回相应论文。
这篇关于顶会热词统计系统的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






