本文主要是介绍Linux 上 学习使用 KingbaseES数据库 (postgresql 版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Linux 上 学习使用 KingbaseES数据库 (postgresql 版)
文章目录
- Linux 上 学习使用 KingbaseES数据库 (postgresql 版)
- 🌈前言
- 🐴环境
- 🌈一 KingbaseES数据库介绍
- 🐴1 角色
- 数据库管理员(system)
- 安全管理员(sso)
- 审计管理员(sao)
- 🌈常用命令
- 🐴1.启动数据库服务
- 使用kingbase命令启动数据库
- 使用sys_ctl
- systemctl
- 🐴2.关闭数据库服务
- 使用sys_ctl
- 使用systemctl 命令
- 🐴3. 创建和删除数据库
- 🐴4 模式对象管理
- 模式
- 表
- 视图
- 索引
- 🌈后记
🌈前言
随着数据库的国产化,我们公司的项目也采用了KingbaseES数据库,下面我总结一些使用命令,来帮大家快速上手 KingbaseES数据库 。
🐴环境
系统:
Linux zookeeper-01 4.19.90-23.8.v2101.ky10.x86_64 #1 SMP Mon May 17 17:08:34 CST 2021 x86_64 x86_64 x86_64 GNU/Linux
数据库版本
KingbaseES V8R6数据库
🌈一 KingbaseES数据库介绍
金仓数据库管理系统KingbaseES V8R6 是一个大型通用数据库管理系统(DBMS),该产品面向事务处理类应用,兼顾各类数据分析类应用,可用做管理信息系统、业务及生产系统、决策支持系统、多维数据分析、全文检索、地理信息系统、图片搜索等的承载数据库。
🐴1 角色
KingbaseES将数据库系统管理员分为数据库管理员、安全管理员、审计管理员三类。在“三权分立”机制下,数据库安装过程中,KingbaseES将默认创建数据库管理员(system)、安全管理员(sso)和审计管理员(sao)用户账号,并为其赋予权限,这三类用户相互制约又相互协作共同完成数据库的管理工作。
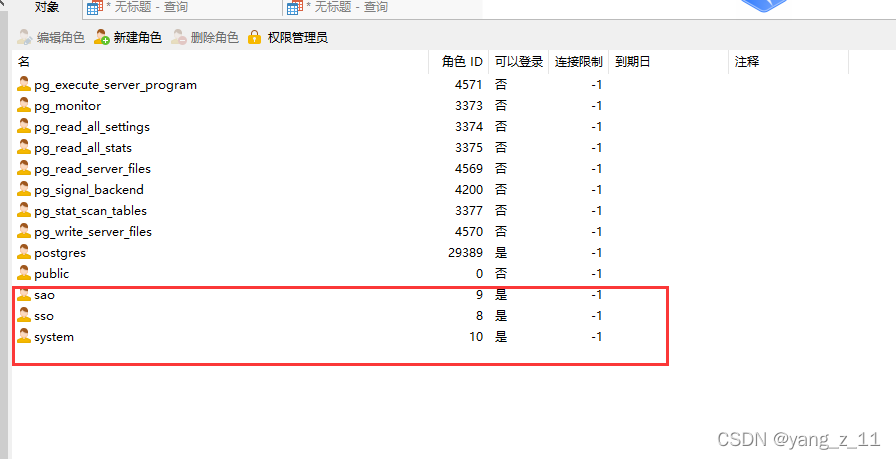
数据库管理员(system)
主要负责执行数据库日常管理的各种操作和自主存取控制。
数据库管理员职责包含以下任务:
负责评估数据库运行所需的软、硬件环境;
安装和升级KingbaseES数据库;
配置KingbaseES数据库参数;
创建主要的数据库存储结构(表空间)和对象(如表、视图、索引、角色、用户等);
监控和优化数据库性能;
数据导入导出以及数据库的备份和恢复;
……
本手册的后续内容将围绕上述数据库管理任务展开(其中的任务1和任务2,请参考相应的KingbaseES数据库安装/更新指南)。
安全管理员(sso)
主要负责制定安全策略,强化系统安全机制。
审计管理员(sao)
主要负责数据库的审计,监督前两类用户的操作。
🌈常用命令
🐴1.启动数据库服务
使用kingbase命令启动数据库
- 命令:
kingbase -D /u01/apps/Kingbase/data
-
上述命令必须以数据库用户登录后进行操作。
-
如果没有-D选项,服务器将尝试使用环境变量KINGBASE_DATA命名的目录。如果环境变量未被提供,则此启动服务器操作将失败。
- 常用选项
| 常用选项 | 介绍 |
|---|---|
| -B NBUFFERS | 共享缓冲区的数量 |
| -c NAME=VALUE | 设置运行时间参数 |
| -C NAME | 打印运行时参数的值 |
| -d 1-5 | 调试级别 |
| -D DATADIR | 数据库目录 |
| -e | 使用欧洲日期输入格式(DMY) |
| -F | 关闭fsync |
| -h HOSTNAME | 主机名或IP地址进行监听 |
| -i | 启用TCP/IP连接 |
| -k DIRECTORY | Unix域套接字位置 |
| -l | 启用SSL连接 |
| -N MAX-CONNECT | 允许的最大连接数 |
使用sys_ctl
- 命令:
sys_ctl start [-D datadir] [-l filename] [-W] [-t seconds] [-s] [-o options] [-p path] [-c]
- 常用选项
| 常用选项 | 介绍 |
|---|---|
| -D datadir | 指定数据库配置文件的文件系统位置 |
| -l filename | 追加服务器日志输出到filename。如果该文件不存在,将会被创建 |
| -W | 不等待操作完成。 |
| -t seconds | 确定等待一个操作完成需等待的最大秒数。默认为KCICTLTIMEOUT环境变量的值,如果该环境变量没有设置,则默认为60秒。 |
| -o options | 指定被直接传递给kingbase命令的选项。-o可以被指定多次,所有给定的选项都会被传递。 |
| -p path | 指定kingbase可执行程序的位置。 |
systemctl
systemctl start kingbase
[root@hrmw-zookeeper-01 ~]# systemctl start kingbase
[root@hrmw-zookeeper-01 ~]# systemctl status kingbase
● kingbase8d.service - LSB: Start and stop the kingbase serverLoaded: loaded (/etc/rc.d/init.d/kingbase8d; generated)Active: active (exited) since Sat 2022-03-19 23:52:31 CST; 24s agoDocs: man:systemd-sysv-generator(8)Process: 276908 ExecStart=/etc/rc.d/init.d/kingbase8d start (code=exited, status=0/SUCCESS)3月 19 23:52:30 hrmw-zookeeper-01 systemd[1]: Starting LSB: Start and stop the kingbase server...
3月 19 23:52:30 hrmw-zookeeper-01 kingbase8d[276908]: Starting KingbaseES V8:
3月 19 23:52:31 hrmw-zookeeper-01 kingbase8d[276908]: waiting for server to start.... done
3月 19 23:52:31 hrmw-zookeeper-01 kingbase8d[276908]: server started
3月 19 23:52:31 hrmw-zookeeper-01 kingbase8d[276908]: KingbaseES V8 started successfully
3月 19 23:52:31 hrmw-zookeeper-01 systemd[1]: Started LSB: Start and stop the kingbase server.
[root@hrmw-zookeeper-01 ~]#
🐴2.关闭数据库服务
使用sys_ctl
sys_ctl的stop模式关闭运行在指定数据目录中的服务器。
sys_ctl stop [-D datadir] [-m s[mart] | f[ast] | i[mmediate] ] [-W] [-t seconds] [-s]
使用sys_ctl关闭运行在/u01/apps/Kingbase/data中的服务器:
sys_ctl stop -D /u01/apps/Kingbase/data
使用systemctl 命令
systemctl stop kingbase
🐴3. 创建和删除数据库
1 创建数据库
CREATE DATABASE "cs";
CREATE DATABASE "cs"
WITHOWNER = "system"ENCODING = 'UTF8'
;
- 删除数据库
DROP DATABASE name;
DROP DATABASE cs;
🐴4 模式对象管理
模式
- 创建模式
CREATE SCHEMA SchemaName ;
如果希望创建属于UserName的模式SchemaName,可以使用下面的语句:
CREATE SCHEMA SchemaName AUTHORIZATION UserName;
- 删除模式
DROP SCHEMA SchemaName ;
从数据库中删除模式。
DROP SCHEMA [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
参数:
| 常用选项 | 介绍 |
|---|---|
| IF EXISTS | 如果该模式不存在,将不会抛出一个错误,而是发出一个提示。 |
| name | 模式的名称。 |
| CASCADE | 自动删除包含在该模式中的对象(表、函数等),然后删除所有依赖于那些对象的对象。 |
| RESTRICT | 如果该模式含有任何对象,则拒绝删除,是默认值。 |
删除一个空模式(模式中的所有数据库对象已经删除)
DROP SCHEMA SchemaName;
如果模式中还有数据库对象,则使用CASCADE子句,删除模式及其中的所有数据库对象:
DROP SCHEMA SchemaName CASCADE;
- 查看模式
ksql程序的dn命令行选项也可以用来列出已有的模式。
test=# \dn 架构模式列表名称 | 拥有者
------------------+--------public | systemsysaudit | systemsysmac | systemxlog_record_read | system
(4 行记录)
表
- 创建表
创建表my_first_table
CREATE TABLE my_first_table(
first_column TEXT,
second_column INTEGER
);
- 向一个表增加一个类型为varchar的列
ALTER TABLE my_first_table ADD COLUMN address varchar(30);
- 从表中删除一列
ALTER TABLE my_first_table DROP COLUMN address RESTRICT;
- 在一个操作中更改两个现有列的类型:
ALTER TABLE my_first_table
ALTER COLUMN first_column TYPE varchar(80),
ALTER COLUMN second_column TYPE varchar(100);
- 重命名表:
ALTER TABLE my_first_table RENAME TO my_table;
也可以使用INSERT、DELETE、UPDATE语句对表中数据进行增、删、改操作。
- 把表films的列kind 中的单词Drama改成Dramatic
UPDATE films SET kind = 'Dramatic' WHERE kind = 'Drama';
- 删除表films中Musical
DELETE FROM films WHERE kind <> 'Musical';
- 向films中插入一行
INSERT INTO films VALUES ('UA502', 'Bananas', 105, '1971-07-13', 'Comedy', '82 minutes');
- 删除表my_first_table:
DROP TABLE my_first_table;
如果要删除的表被其他表引用,即其他表的外键引用了表的任何主键或唯一键,则需要在DROP TABLE语句中包含CASCADE选项,如:
DROP TABLE my_first_table CASCADE;
- DELETE
使用DELETE语句删除表中的行。下面的语句将删除my_first_table表中的所有行:
DELETE FROM my_first_table;
但当表有很多行时,使用DELETE清空表会消耗过多的系统资源。
- TRUNCATE
使用TRUNCATE语句能删除表中的所有行。下面的语句清空my_first_table 表。
TRUNCATE TABLE my_first_table;
视图
- 查询视图
ksql程序的dv命令行选项可以用来列出现有视图。
test=# \dv关联列表架构模式 | 名称 | 类型 | 拥有者
----------+---------------------+------+--------public | sys_stat_statements | 视图 | system
(1 行记录)
select * from public.sys_stat_statements;
test=# select * from public.sys_stat_statements;userid | dbid | queryid | query | parses | total_parse_time | min_parse_time | max_parse_time | mean_parse_time | stddev_parse_time | plans | total_plan_time | min_plan_time | max_plan_time | mean_plan_time | stddev_plan_time | calls | tot
al_exec_time | min_exec_time | max_exec_time | mean_exec_time | stddev_exec_time | rows | shared_blks_hit | shared_blks_read | shared_blks_dirtied | shared_blks_written | local_blks_hit | local_blks_read | local_blks_dirtied | local_blks_wr
itten | temp_blks_read | temp_blks_written | blk_read_time | blk_write_time
--------+------+---------+-------+--------+------------------+----------------+----------------+-----------------+-------------------+-------+-----------------+---------------+---------------+----------------+------------------+-------+----
-------------+---------------+---------------+----------------+------------------+------+-----------------+------------------+---------------------+---------------------+----------------+-----------------+--------------------+--------------
------+----------------+-------------------+---------------+----------------
(0 行记录)
- 创建视图
在films表中创建一个由所有Comedy组成的视图:
CREATE VIEW comedies AS
SELECT * FROM films
WHERE kind = 'Comedy';
- 删除视图
DROP VIEW删除一个现有的视图。
DROP VIEW [ IF EXISTS ] name [, …] [ CASCADE | RESTRICT ]
索引
KingbaseES提供B-树、HASH索引和GIN索引,每种索引分别适用不同的查询类型。
- CREATE INDEX
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON [ ONLY ] table_name [ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ INCLUDE ( column_name [, ...] ) ]
[ WITH ( storage_parameter = value [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]
参数:
| 常用选项 | 介绍 |
|---|---|
| IF EXISTS | 如果该索引不存在不要抛出错误。这种情况下将发出一个提示。 |
| column_number | 引用该索引列的顺序(从左往右)位置的顺序号。 |
| name | 要更改的一个现有索引的名称(可能被模式限定)。 |
| new_name | 该索引的新名称。 |
| tablespace_name | 该索引将被移动到的表空间。 |
| extension_name | 该索引所依赖的扩展的名称。 |
| storage_parameter | 一个索引方法相关的存储参数的名称。 |
| value | 一个索引方法相关的存储参数的新值。根据该参数,这可能是一个数字或者一个词。 |
- ALTER INDEX
ALTER INDEX [ IF EXISTS ] name RENAME TO new_name
ALTER INDEX [ IF EXISTS ] name SET TABLESPACE tablespace_name
ALTER INDEX name ATTACH PARTITION index_name
ALTER INDEX name DEPENDS ON EXTENSION extension_name
ALTER INDEX [ IF EXISTS ] name SET ( storage_parameter = value [, ... ] )
ALTER INDEX [ IF EXISTS ] name RESET ( storage_parameter [, ... ] )
ALTER INDEX [ IF EXISTS ] name ALTER [ COLUMN ] column_number
SET STATISTICS integer
ALTER INDEX ALL IN TABLESPACE name [ OWNED BY role_name [, ... ] ]
SET TABLESPACE new_tablespace [ NOWAIT ]
参数同上
重命名一个现有索引:
ALTER INDEX distributors RENAME TO suppliers;
- REINDEX
当一个表经过大量的增删改操作后,表的数据在物理文件中可能存在大量碎片,从而影响访问速度。此外,当删除表的大量数据后,若不再对表执行插入操作,索引所处的段可能占用了大量并不使用的簇,从而浪费了存储空间。
因此,可以使用重建索引来对索引的数据进行重组,使数据更加紧凑,并释放不需要的空间,从而提高访问效率和空间效率。
REINDEX [ ( VERBOSE ) ] { INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } [CONCURRENTLY ] name
参数:
| 常用选项 | 介绍 |
|---|---|
| INDEX | 重新创建指定的索引。 |
| TABLE | 重新创建指定表的所有索引。如果该表有一个二级 “TOAST”表,它也会被重索引。 |
| SCHEMA | 重建指定方案的所有索引。如果这个方案中的一个表有次级的“TOAST”表,它也会被重建索引。共享系统目录上的索引也会被处理。这种形式的REINDEX不能在事务块内执行。 |
| DATABASE | 新创建当前数据库内的所有索引。共享的系统目录上的索引也会被 处理。这种形式的REINDEX不能在一个 事务块内执行。 |
| SYSTEM | 重新创建当前数据库中在系统目录上的所有索引。共享系统目录上的 索引也被包括在内。用户表上的索引则不会被处理。这种形式的 REINDEX不能在一个事务块内执行。 |
| name | 要被重索引的特定索引、表或者数据库的名字。索引和表名可以被 模式限定。当前,REINDEX DATABASE和 REINDEX SYSTEM只能重索引当前数据库,因此 它们的参数必须匹配当前数据库的名称。 |
| CONCURRENTLY | 当使用此选项时,KingbaseES将重新构建索引,而不采取任何锁来防止表上的并发插入、更新或删除;而标准的索引重新构建将锁定表上的写操作(而不是读操作),直到完成为止。 在使用这个选项时需要注意几个注意事项参见 同时重建索引 . |
| VERBOSE | 在每个索引被重建时打印进度报告。 |
重建单个索引:
REINDEX INDEX my_index;
重建表my_table上的所有索引:
REINDEX TABLE my_table;
- DROP INDEX
删除索引
DROP INDEX [ CONCURRENTLY ] [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
参数:
| 常用选项 | 介绍 |
|---|---|
| CASCADE | 自动删除依赖于该索引的对象,然后删除所有依赖于那些对象的对象。 |
| RESTRICT | 如果有任何对象依赖于该索引,则拒绝删除它,是默认值。 |
删除索引title_idx:
DROP INDEX title_idx;
🌈后记
如果本文章有何错误,请您评论中指出,或联系我,我会改正,如果您觉得这篇文章有用,请帮忙一键三连,让更多的人看见,谢谢
作者 yang_z_1 csdn博客地址: https://blog.csdn.net/yang_z_1?type=blog
这篇关于Linux 上 学习使用 KingbaseES数据库 (postgresql 版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




