本文主要是介绍Binder驱动的初始化 syscall原理(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在说明Binder之前。我们来想想Binder作为一个进程间通信的通道之前。我们常用的进程间通信有几种。
Linux中,我们常见有一下几种进程间通信:
1.pipe 管道
2.FIFO named pipe 有名管道
3.signal 信号
4.消息队列
5.socket 套子节
6.SharedMemory 共享内存
用户空间(用户态)和内核空间(内核态)
一些操作系统允许所有用户与硬件做交互。但是,类unix操作系统在用户应用程序钱把计算机物理组织相关的底层细节都隐藏起来。当程序想试用硬件资源时候,必须向操作系统发出请求。内核会对这个请求做评估,允许使用,那么内核将会代表应用与硬件交互。 为了实现这个机制,现代操作系统依赖特殊硬件特性来禁止用户程序直接与底层打交道,或者直接访问任意的物理地址。硬件为cpu引入了至少两种执行模式:用户的非特权模式和内核的特权模式。也就是我们常说的用户态和内核态。
这是来自深入理解Linux一书中的定义。举个简单的例子,当我们需要运行文件操作的时候,使用open等操作方法,就会从用户程序就会从用户态进入到内核态,当open结束之后,用户程序进入回到用户态。
为什么Linux系统要这么设计。最大的原因就是为了让内核底层透明化,同时如果用户程序出现了问题,将不会影响内核。
换我们思考一下,如果是我们,怎么在两个隔离的进程任务块中联系彼此。很常见的一个思路,我们一般能想到的是,让一个进程把需要交互的信息存到一个文件里面,另一个进程从文件中读取数据。
管道pipe
这种思路,被广泛运用到Linux系统中。比如pipe实际上是创建了两个文件(文件描述符实际上是内核缓存区),一个专门用来读,一个专门用来写。而pipe是一个半双工的通道,换句话说就是在一个时间内只能在一个单方向的进程通信。这样就可能的减少因为多个进程来回竞争文件内容,导致传输过程中出错。
而此时pipe必定是先通过内核调用copy_from_user方法把初始化数据拷贝一份内核空间中,此时通过alloc_file通过kmalloc在调用slab在内核空间创建2个文件描述符。
大致上示意图如下:
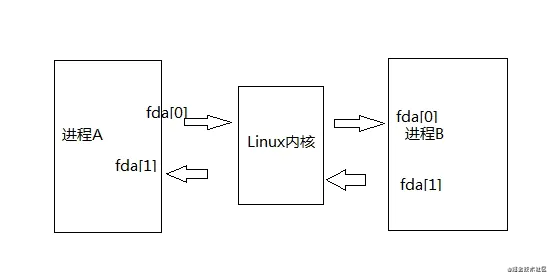
记住fd[0]是读通道,fd[1] 是写通道
FIFO named pipe
有名管道,这中管道在原来的基础上做了处理,依赖了Linux的文件系统。从名字上就能得出这种管道是先入先出的原则,能够让数据通信按照顺序来。然而有名管道更大的意义是让管道命名。原来的管道是无名管道,所以只能在自己控制下的子进程做沟通。而多了名字之后,就不需要想法子把地址交给第二个进程,而是通过名字去找文件,就能建立通道。
signal 信号
信号这个东西,我们其实早就有所耳闻。比如说我们常说的中断信号就是指的是信号的一种。而在linux内核中内置一些通知事件。每一次发出这个事件内核将会通知进程接收这些事件,并且做处理。
内核实现:
1.为了做到对应的信号能够发送到正确需要进程。内核需要记住当前进程被哪些信号阻塞。
2.当从内核态切换到用户态,检查进程是否产生信号。这种检测每个时钟都会触发一次,一般在几个毫秒内触发一次。
3.还要检测哪些信号被忽略。以下条件都满足时表示信号被忽略
-
进程没有被追踪,task_struct(用来描述进程的结构体)PT_PTRACED标示为0.
-
进程没有阻塞这种信号
-
进程忽略这种信号
4.处理信号
此时我们需要注意的是,在内核态我们是不会处理信号的,往往都会抛到用户空间,通过copy_to_user拷贝交给用户空间去处理。
消息队列
这个听起来有点像Android里面的消息队列。两者相比,设计上确实相似。消息队列的使用,先通过ftok生成一个key,再通过key用msgget创建一个消息队列(文件)。之后用msgsnd或者msgrcv发送或者接收东西。
此时在内核上实际上可以看出创建了一个文件。把对应的消息传进去消息队列中。此时读取方和写入方由于有ftok生成一个key,就能在内核空间找到对应的消息队,就能借助这个队列完成消息的传递。其中为了让数据能够来回在用户态和内核态来回切换,还是使用到了copy _from_user,copy_to_user.其数据结构是一个链表。
socket 套子节
这个我们所有人都十分的熟悉。我们做网络编程离不开它。实际上从原理上它也是一种特殊的文件,我们也是不断的监听socket的状态来回应。既然是文件操作,那么一定会经历一次用户态到内核态,内核态到用户态的转化。这种本地监听的运用,在zyogte孵化进程的时候经常用。
共享内存
共享内存的设计,是最接近binder的设计。其核心也是用过mmap内存映射技术。其设计上也和消息队列相似。也是通过ftok生成一个key,再通过这个key申请内存shmget之后,就能对这段地址做操作。
信号量
实际上信号量最主要的作用是对进程进行加锁,如果有进程访问这个正在使用的资源会进入睡眠状态。
Binder 的概述
介绍了Linux的几种基础IPC(进程间通信),我们发现一个很有趣的现象。大部分的IPC通信都通过文件作为中转站来回通讯。这样势必会造成用户态,内核态在来回切换,那么必定造成这种数据拷贝两次的情况。那么我们有没有办法处理优化这种通信方法呢?Binder就诞生了。
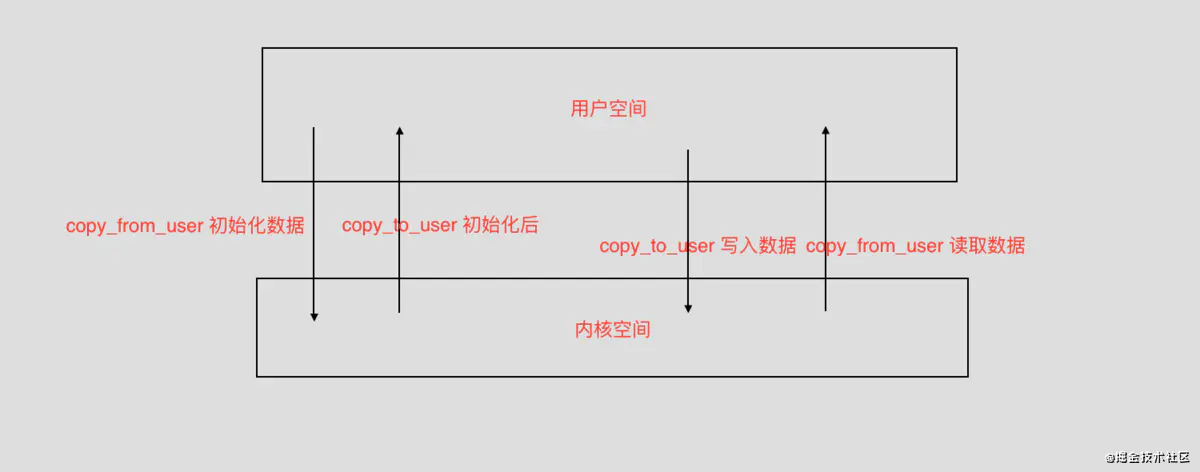
那么我们要设计Binder的话,又能怎么设计呢?首先为了让整个透明并且可靠化,我们能采用TCP/IP这一套思路来保证信息的可靠性。其次为了减少来回的在用户往内核中拷贝空间能够创造模仿共享内存的方式。
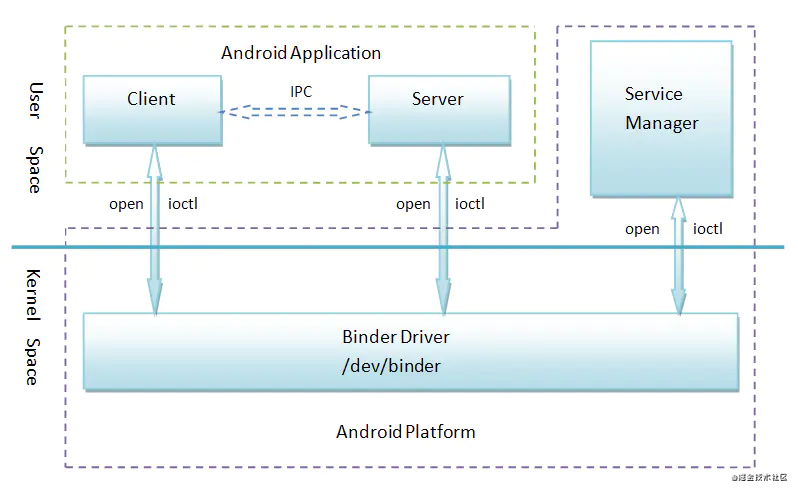
我们可以关注到Binder中四种角色:
Binder 驱动
ServiceManager
Binder Client
Binder Service
从这里我们明白,在内核空间中,存在这一个Binder的驱动,而这个驱动正是作为整个IPC通信的中转站。也就是类似TCP通信中的路由地位,我不在乎你究竟要是干啥,我只需要找到你,并且把消息交给你就好。
此时service manager充当的是Binder驱动的守护进程,类似于TCP通信中的DNS地位。我们会把相关的Binder注册到里面,最后会通过service manager这个服务去查找binder的远程端。而实际上这个service manager在Andrioid Binder体系中,承当了Android系统中第一个注册进入Binder的服务。
Binder Client binder的客户端,相当于C/S架构中的客户端的概念。
Binder Service binder的服务端,相当于C/S架构中中服务端的概念。
Binder驱动,本身充当一个一个类似路由表,路由分发器。每当一个client想去寻找service的时候,都会经过binder驱动,binder并不关心传输的内容是什么,只需要帮助你分发到服务。
在这里我重新申明一次,所谓的服务端和客户端的概念只是为了更加好理解,实际上在Binder驱动看来并没有所谓的服务和客户端概念,仅仅只有远程端(或者代理端)和本地端的概念。因此Binder在整个IPC进程通信中,谁发出了请求此时就是作为本地端也就是客户端,而远程响应这个请求的则是代理端/远程端,也就是上面说的服务端。
大致知道这些角色之后,也就能清楚上方这个图的意义了。很简单,在Android系统启动的时候,会去启动一个Service Manager的进程。而这个进程会初始化好内核的Binder驱动。此时DNS和路由都准备好了。只要等到服务端注册进来,客户端取链接交互即可。
下面是根据binder的设计的示意图。
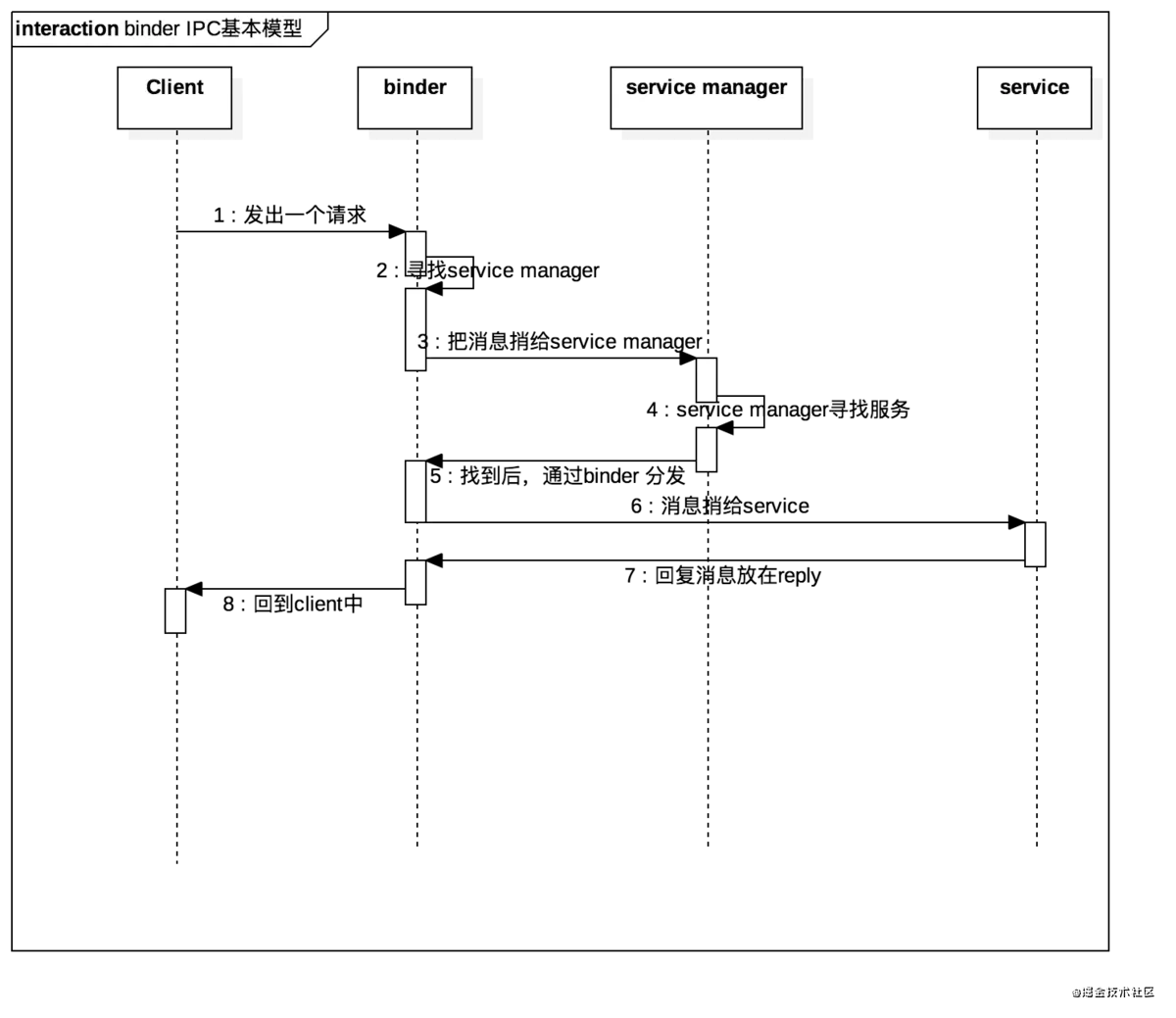
为什么我说Binder和TCP十分相似。首先在我们开发中从来不会注意到binder的存在,更加不会注意到Android开发中我们居然会有信息做了跨进程通信。这也侧面说明了binder的设计优秀以及binder已经对上层来说几乎透明化。
那么让我们略去service manager 和binder 驱动看看service和client之间的关系。
这篇关于Binder驱动的初始化 syscall原理(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








