本文主要是介绍mysql 相关的一些东东,来自dbanotes,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原贴:http://www.dbanotes.net/MT/mt-search.cgi?IncludeBlogs=1&search=mysql
Matching entries matching “mysql” from DBA notes
Fotolog.com 的技术信息拾零
尽管是世界上最大的图片服务网站, Fotolog.com 在国内的名气并不是很响亮, 每当提到图片服务, 很多人第一个会想起 Flickr. 但实际上 Fotolog 也的确是很猛的, Alexa 上的排名一直在 Flickr 前面, 目前注册用户超过 1100 万. 而前不久也卖了一个好价钱, 9000 万美金. 算下来的话, 1 个注册用户大约 9 美金. Yupoo 的刘平阳可以偷着算算自己的网站如果卖给老外是怎样一个价格了.
在前不久的 MySQL Con 2007 上, Fotolog 的 DBA Farhan Mashraqi 披露了一些技术信息.(PPT下载)
与其他大多数 Web 2.0 公司普遍用 Linux 不同的是, Fotolog 的操作系统用的是 Solaris . Solaris X86 也是免费的, 估计是维护人员更熟悉 Solaris 的操作系统而作出的选择吧.
数据库当然是使用 MySQL. 有32 台之多, 最开始的存储引擎是 MyISAM ,后来转向 InnoDB. 对于 DB HA , 使用 DRBD (介绍),在 Solaris 上用 MySQL ,有个优化技巧是关于 time(2) 系统调用的,通过调用比 gethrestime() 更快的 gethrtime(3C) 来提高性能。可以通过设置 LD_PRELOAD (32位的平台) 或 LD_PRELOAD_64 来做到。详细信息可以参考Sun 站点上的这篇 MySQL 优化文章,很有参考价值。
存储也是值得一说的,Fotolog 用的是 SAN,还是比较贵的 SAN: 3Par. 这个产品可能绝大多数 DBA 是比较陌生的,该产品原来主打金融市场,现在也有很多 Web 公司使用,一个比较典型的客户代表是 MySpace。3Par 的最大的特点就是 Thin Provisioning。Thin Provisioning 这个词有的人翻译为"自动精简配置",在维基百科的定义:
Thin provisioningis a mechanism that applies to large-scale centralized computer disk storage systems, SANs, and storage virtualization systems. Thin provisioning allows space to be easily allocated to servers, on a just-enough and just-in-time basis.
说白了就是对空间分配能够做到"按需分配"。有些扯远了。
--EOF--
从 MySQL 迁移到 Oracle (傻瓜篇)
如果用关键字 "MySQL 迁移 Oracle" 在网上搜索,基本上得到的内容都是关于从 Oracle 如何迁移到 MySQL 的,而从 MySQL 迁移到 Oracle 的信息则少之又少。
抛开那些手工一点点做的方法不谈,网络上也可以找到一些第三方工具来做这个事情,免费的? 我只找到了一个,那就是 Oracle SQL Developer 了。如果采用比较傻瓜化的方法,不妨考虑这个工具。在这个工具之前,Oracle 提供了单独的 Migration Workbench 工具。在 SQL Developer 1.2 版中,Oracle 干脆把这个功能集成进来。
数据流示意图:
Source Database(MySQL/DB2 etc.) --->SQL Developer (ETL)-->Target Database (Oracle)
MySQL JDBC 下载地址:
http://dev.mysql.com/downloads/connector/j/5.0.html
配置 MySQL JDBC:
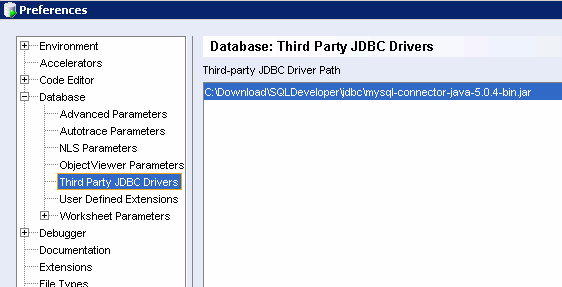
还需要注意一点就是需要调整一下迁移时候的参数:
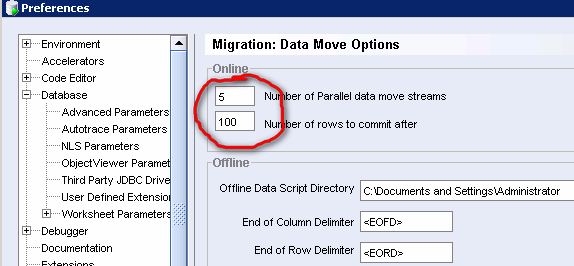
剩下的事情就简单了,配置到不同数据库以及准备存放 Metadata 数据库的信息。然后就可以迁移了。不赘述。
这个方法只是够傻瓜化,由于运行机制的限制,速度不是非常好。对于迁移过程中产生的变化数据,也无能为力。
--EOF--
YouTube 的架构扩展
在西雅图扩展性的技术研讨会上,YouTube 的 Cuong Do 做了关于 YouTube Scalability 的报告。视频内容在 Google Video 上有(地址),可惜国内用户看不到。
Kyle Cordes 对这个视频中的内容做了介绍。里面有不少技术性的内容。值得分享一下。(Kyle Cordes 的介绍是本文的主要来源)
简单的说 YouTube 的数据流量, "一天的YouTube流量相当于发送750亿封电子邮件.", 2006 年中就有消息说每日 PV 超过 1 亿,现在? 更夸张了,"每天有10亿次下载以及6,5000次上传", 真假姑且不论, 的确是超乎寻常的海量. 国内的互联网应用,但从数据量来看,怕是只有 51.com 有这个规模. 但技术上和 YouTube 就没法子比了.
Web 服务器
YouTube 出于开发速度的考虑,大部分代码都是 Python 开发的。Web 服务器有部分是 Apache, 用 FastCGI 模式。对于视频内容则用 Lighttpd 。据我所知,MySpace 也有部分服务器用 Lighttpd ,但量不大。YouTube 是 Lighttpd 最成功的案例。(国内用 Lighttpd 站点不多,豆瓣用的比较舒服。by Fenng)
视频
视频的缩略图(Thumbnails)给服务器带来了很大的挑战。每个视频平均有4个缩略图,而每个 Web 页面上更是有多个,每秒钟因为这个带来的磁盘 IO 请求太大。YouTube 技术人员启用了单独的服务器群组来承担这个压力,并且针对 Cache 和 OS 做了部分优化。另一方面,缩略图请求的压力导致 Lighttpd 性能下降。通过 Hack Lighttpd 增加更多的 worker 线程很大程度解决了问题。而最新的解决方案是起用了 Google 的 BigTable, 这下子从性能、容错、缓存上都有更好表现。看人家这收购的,好钢用在了刀刃上。
出于冗余的考虑,每个视频文件放在一组迷你 Cluster 上,所谓 "迷你 Cluster" 就是一组具有相同内容的服务器。最火的视频放在 CDN 上,这样自己的服务器只需要承担一些"漏网"的随即访问即可。YouTube 使用简单、廉价、通用的硬件,这一点和 Google 风格倒是一致。至于维护手段,也都是常见的工具,如 rsync, SSH 等,只不过人家更手熟罢了。
数据库
YouTube 用 MySQL 存储元数据--用户信息、视频信息什么的。数据库服务器曾经一度遇到 SWAP 颠簸的问题,解决办法是删掉了 SWAP 分区! 管用。
最初的 DB 只有 10 块硬盘,RAID 10 ,后来追加了一组 RAID 1。够省的。这一波 Web 2.0 公司很少有用 Oracle 的(我知道的只有 Bebo,参见这里). 在扩展性方面,路线也是和其他站点类似,复制,分散 IO。最终的解决之道是"分区",这个不是数据库层面的表分区,而是业务层面的分区(在用户名字或者 ID 上做文章,应用程序控制查找机制)
YouTube 也用 Memcached.
很想了解一下国内 Web 2.0 网站的数据信息,有谁可以提供一点 ?
--EOF--
DRBD 提升了 MySQL 的集群能力
前几天 MySQL 站点上有个为期 12 天以 Scale-Out 为主题的活动,列举了不少成功的案例,每个页面有下方的这个图很引人注意:
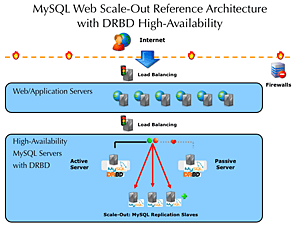
注意到主备服务器之间的 HA 是通过 DRBD(Distributed Replicated Block Device)做到的。DRBD 号称是 "网络 RAID",开源软件,由 LINBIT 公司开发,MySQL 与 LINBIT 达成了合作关系,大张旗鼓的搞了这个 "12 天 Scale-Out" 活动也是这个商业合作驱动的吧。DRBD 助力 MySQL, 号称可以得到四个 9 的可靠性,这不低于任何一款商业数据库软件了。
DRBD 的出现的确对 MySQL 集群的可用性有很大提高。而且,有独到的特点,非常适合面向互联网的应用。因为是在存储层的数据块同步,很容易的做到应用层的 IO 负载均衡(备机承担一定的读压力),不但支持数据库失败接管,还能做到 IP 失败接管,接管时间小于 30 秒,真是穷人的绝佳集群解决方案(相比 Oracle 下的一些方案,比如 eBay 采用的方案,性价比还是不错的)。国外已经有很多成功的实现案例,国内的 Web 2.0 站点不知道是否已经有人在用,在这里推荐一下。更为有趣的是,已经有人通过 DRBD 来实现 Oracle 的另类集群。
怪不得前一阵子已经有开源爱好者开始宣称类似 "RAID即将成为过去式" 的激进言论。
--EOF--
FeedLounge 使用 PostgreSQL 的经验
这是我唯一看到的 Web 2.0 公司使用 PostgreSQL 的,可惜还失败了。
FeedLounge 是一个提供在线 RSS Reader 的站点。已经在今年 6 月 1 日黯然宣布失败。这里不去讨论他们失败的各种原因,只说说从他们 Blog 上看来的关于他们选择数据库的经验。
FeedLounge 在数据库的使用上路线是这样的:
MySQL(MyISAM) --> MySQL(InnoDB) --> PostgreSQL
最初是 MyISAM 方式,迁移到 InnoDB ,数据库从大约 1G 膨胀超出了 10G,而且发现引发了新的性能问题,经过尝试发现不能解决后,迁移到 PostgreSQL,总存储从 InnoDB 方式的 34G 缩小到 9.6G,而且,恢复时间也只是原来的大约 1/5 (导出用 Mysqldump,载入用 psql ). 此外,关于内存利用方式上也有一些差异, MySQL : innodb_buffer_pool 6GB + O_DIRECT flush, PostgreSQL 设置上限 2G,只用了 1.2 G。遗憾的是,看不到切换前后性能数据更为详细的对比。
FeedLounge 当时每天要处理的事务量:每天超过 400 万次查询,超过 200 万次的更新/插入操作,高峰期每秒钟有 2000 个更新/插入操作(这应该是批处理阶段)。硬件如何呢? 数据库服务器的硬件:两路 Opteron CPU,8 GB 内存, 6 SATA 7200RPM 16MB 硬盘, RAID 5 ,控制器有 128M. 可以看出来了吧, 7200 转的硬盘 + RAID 5 根本不适合这样的应用。从这一点上说,数据库类型切换其实解决不了本质的问题。
另外看到的有趣参考信息:
FeedDigest 在当时每天有超过 400 万次的查询,超过 200 万次插入,机器硬件只用了双奔四 CPU(2.8GHz) ,1G内存
--EOF--
Google 助力 MySQL
MySQL 应该给 Google 发感谢信: Google 在 Google Code 上发布的 Google Mysql Tools 使得 MySQL 在性能、可管理性、稳定性上都增色不少。
在该项目的首页将这个工具集分为三部分:
* mypgrep.py - a tool, similar to pgrep, for managing mysql connections
* compact_innodb.py - compacts innodb datafiles
by dumping and reloading all tables
* patches - patches to add features to MySQL 4.0.26 and MySQL 5.0.37
这份介绍似乎已经不能完全概括 Google Mysql Tools 了。现在的重点似乎是补丁包部分。根据版本号分为 MySQL4 与 MySQL 5,MySQL 5 的 Patch 现在很少,而 MySQL 4 部分内容真的比较丰富,关键改进列表:
* SemiSyncReplication - block commit on a master until at least one slave acknowledges receipt of all replication events.
* MirroredBinlogs - maintain a copy of the master's binlog on a slave
* TransactionalReplication - make InnoDB and slave replication state consistent during crash recovery
* UserTableMonitoring - monitor and report database activity per account and table
* InnodbAsyncIo - support multiple background IO threads for InnoDB InnoDB 异步IO的支持相信对性能会有很明显的提升
* FastMasterPromotion - promote a slave to a master without restart
MySQL 在联机备份方面是弱势,倒是期待 Google 也能在这个方面做出改进(我非常好奇对于 Google Checkout 数据库是如何备份的).
在 Code 上的另外一个 关键项目 Google Perftools 中的 TCMalloc 对 MySQL 的性能也有很大的改进,相信国内很多出色的 Web 2.0 公司都已经用到这个东西了吧。TCMalloc : Thread-Caching Malloc 号称是目前最快的 Malloc ,对于解决 MySQL 遇到的 Malloc 扩展问题有很大的影响。
没有 Google 的支持,相信 Firefox 不会有现在这么大的影响力。有了 Google 的支持, MySQL 会发展多快 ?
--EOF--
网络侠客行大会后记
距离网络工程师侠客行大会成功举行已经有好几天了,总算有点空,也简单的写一下我的参会感受。
周五晚上加完班刚到家,接到刚下飞机的阿北的电话,问我下午技术研讨的场次是否可以调整,我也不知道公司同事对票是怎么控制的,赶紧在 IM 上找在线的同事联系了一下关于场次以及晚上酒吧活动的事情。之前比较忙,也顺便看了一下会场信息什么的。
周六正在洗脸,接到张磊的电话,我答应给他要一张票的。收拾停当,赶紧出门,要知道在杭州作出租车有的时候要靠运气,紧赶慢赶,总算正式开始之前赶到了人民大会堂。把票给了张磊后遇见了几位同事,会场里只有最后一两排还有座位了。
前面的嘉宾致辞都很短,不愧是技术性的会议。接下来的第一个主题演讲就是 PHP 之父 Rasmus Lerdorf 的《激情下的 PHP》,Lerdorf 是典型的 Nerd 形象,为了练练英语听力,我特地跑到最前排,坐在地上听完了演讲。Lerdorf 看来在美国也是到处走穴,演讲的经验很丰富,刚开始明显感觉他也有些紧张,到了后半段就非常放松了。可能这是我在最前面能感觉到的一点吧。在自由提问的时候有人问到下一个版本的 PHP 会有哪些特性,Lerdorf 不加思索的说 "Unicode",最后的一句话很有意思,大意是"如果要问我再下一个版本是怎样的,我也不知道".

上午的第二个主题演讲者是 Yahoo! 著名 Blogger Jeremy Zawodny, Jeremy 的 Blog 是业界比较知名的,他在 MySQL 方面的经验非常丰富(如果他做这个主题可能更受欢迎),"将 MySQL 成功的大规模部署在 Yahoo! 上", 他这次的演讲主题确是关于 Web Service 方面的。 Jeremy 在此行之前做了不少功课,包括对中国的了解,以及 How I write a Presentation,车东说他是个 Geek ,诚如所言。
中场休息的时候认识来自博文视点的周筠老师以及 CSDN 的龙如俊,还有霍泰稳
, 他现在在负责InfoQ 中文,还有其他几位编辑,以前在网上多有联系,这次总算见到这几位真人了。
周筠老师非常有亲和力,其他几位编辑也都非常热情,盛情邀请几位 DBA 一起吃午饭,吃饭的细节汪海已经有所描述(就是他来的比较晚 :)),需要补充的是,我临走还获赠了两本图书,一本是著名的《代码大全》,一本是 《Effective C++》第三版,的确是好书,不能独享,已经转赠给公司开发团队的图书室了。
这是 19 号周六上午的流水账,有空我再继续写。
--EOF--
学习 Flickr 的 基于 LAMP 的容量规划经验
好久没怎么正式更新 Blog 了,快荒芜了,长满了 Spam 的荒草。
最近其实发现了不少可以和大家一起学习的好内容。Flickr 的 John Allspaw 在 MySQL Conf 2007 作了一个题为 Capacity planning for LAMP (下载PDF文件) 的技术报告,说起容量规划,多少有点空对空的意思,不过这个 PPT 还是介绍了不少 Flickr 的网站运维经验。
Flickr 的数据量的确越来越惊人了,根据文档中透漏的数据:
Squid Cache 中共有 3500 万张图片;
在 Squid RAM 中有 200 万张图片;
4.7亿的图片,每张图片有4到5种尺寸;
每秒钟 38000 个到 memcached 的请求;
2 PB 裸存储容量(周日需要消耗1.5T 的空间)
三个主要步骤:
计划
基于实际业务,而不是抽象的理论。John Allspaw 认为基准测试(Benchmark) 作用并不大,这一点我也很赞同。在业务频繁变化的环境中,Benchmark 根本不能与实际业务情况匹配。部署
Flickr 使用 SystemImager/SystemConfigurator(自动化安装、软件分发), CVSup(网络中的文件分发、更新), Subcon(配置管理工具)提高部署效率。度量(图形化展现)
Flickr 使用了 Ganglia 来进行容量数据的展现。Ganglia 最初设计是用于高性能集群计算的监控上面,也是以 RRDTool 为基础来进行图形展示。Ganglia 最主要的优点还是管理的方便性: Client/Server 结构, 各自跑 Demon 进行数据交互(XML形式)。相比起来, Cacti + Collectd 需要进行很多手工配置,在面对大量需要监控的主机的时候的确不那么方便。
Web 2.0 站点的运维似乎大家都在摸索着走。期望这次阿里巴巴组织的侠客行大会上也有有朋友坐下来聊聊这个话题(Flickr 的架构师本来可以来的,因为时间的问题不能成行,挺遗憾的)。
--EOF--
Web 2.0 站点扩展性问题随感
最新一期《程序员》杂志上有篇《Web 2.0 构建要素》的文章,里面描述了一些 Web 2.0 的扩展性问题,这可能也是 Web 2.0 站点从小到大必须承受的苦恼。该文简单介绍了有些站点通过 Amazon S3 服务来解决存储扩展带来的压力。有些站点则必须自己动手构建最适合自身业务的技术方案。
很多比较成功的站点,有的时候会透露出一些关于站点扩展性的技术信息,像我收集的 Flickr 的开发者的 Web 应用优化技巧、Technorati 的后台数据库架构、Craigslist 的数据库架构等,往往是蜻蜓点水,看过之后让人心痒难当,可是更细节的东西又很难获取。尽管这些站点基本都是构建在 OpenSource 软件上,但这一点上看,似乎不够 Open ,唯一一个做的比较好的倒是要算 LiveJournal ,他们通过 Danga 站点贡献了几个经典的软件与一些很有参考价值的文档(如这篇对LiveJournal扩展性的介绍),是为很多后起 Web 2.0 站点必备的参考信息。
在国内,很多 Web 2.0 站点也同样面临着这样的问题,象豆瓣,阿北还需要身兼 DBA, 而抓虾,虽然数据库已经有上亿级别的记录量,就上次我在北京和谌振宇聊天,感觉抓虾在扩展性上也是还有很多细节需要完善,在杭州,Yupoo 也因为日益增长的数据量而不得不着手考虑如何更为成功的实现分布式存储解决方案......
这些似乎表明,Web 2.0 站点扩展性问题越来越突出,已经成为制约 Web 2.0 发展的一个障碍,"多、快、好、省"的构建新型互联网应用,不知道正在让多少人犯愁。
在传统互联网领域,很多技术解决方案往往是软硬件厂商提出来,类似自上而下的推动,而 Web 2.0 站点变化太快,到现在为止,似乎只有 MySQL 一家公司是比较大的赢家,可是因为面对的客户情况各异,解决方案似乎无从说起(比较简略的实现案例倒是能找到几个),再者,这些站点基本上是把 MySQL 这样的产品当作基本工具,和其他软硬件相互结合,然后在这个上面灵活构建出很多具有创新性的应用。这是一种自下而上的变化。
另一方便,Web 2.0 架构方面的人才还是稀缺,这个架构不是指某一方面(比如Java)的架构,而是整个产品环境的架构,象 Flickr 技术大牛 Cal Henderson 这样的人几乎是可遇不可求。操作系统、网络、数据库、开发语言每样都能那起来并且能够涉及足够灵活的技术方案,这要求,也的确高了一些。或许有人说,一个人不行,那么多几个人分别负责某几个环节不就成了? 这又带来另外一个问题:人力成本。
上一篇 Blog 我提到五月份的"侠客行"大会,我倒是希望能有一群网络技术人才能够就 "Web 站点可扩展性" 这个话题作一番探讨,每个站点如果都说说自己的心得,那么汇集在一起参考价值会对整个 Web 2.0 环境起到很大的促进作用。
最后,还拿 MySQL 说事儿,去年网志年会上,就有人感叹,国内 MySQL 好手太少了,考虑到物以稀为贵,有的 Oracle DBA 已经开始学习 MySQL 啦.
--EOF--
Second Life 的数据拾零
Matrix 似乎提前来到我们身边。从 06 年开始,陆续看到多次关于 Second Life(SL) 的报道。因为自己的笔记本跑不起来 SL 的客户端,所以一直没有能体会这个虚拟世界的魅力。今天花了一点时间,读了几篇相关的文档。
RealNetworks 前 CTO Philip Rosedale 通过 Linden 实验室创建了 Second Life,2002 年这个项目开始 Alpha 版测试,当时叫做 LindenWorld。
2007 年 2 月 24 日号称已经达到 400 万用户(用户在游戏中被称为 "Residents",居民)。 2001 年 2 月 1 日,并发用户达到 3 万。并发用户每月的增长是 20%。这个 20%现在看起来有些保守了,随着媒体的关注,增长的会有明显的变化。系统的设计目标是 10 万并发用户,系统的复杂度不小,但 Linden 实验室对SL 的可扩展能力信心满满。
目前在旧金山与达拉斯共有 2000 多台(现在恐怕3000也不止了吧) Intel/AMD 服务器来支撑整个虚拟世界(refer here)。64 位的 AMD 服务器居多。操作系统选用的 Debian Linux, 数据库是 MySQL。通过 Tim O'relly 的这篇 Web 2.0 and Databases Part 1: Second Life ,可以了解到一点关于 SL 数据库建设的信息。在 Second Life 中每个地理区域都是运行在服务器软件单一实例上的,叫做"模拟器"或者简称是 "sim",每个 Sim 负责 16 英亩的虚拟土地。当用户在相邻的 Sim 间移动,实际上是从一个处理器(或是服务器)移动到另一个。根据这篇访谈,用户当前所在 Sim 的信息,以及用户本身的账户信息是存储在一个中心数据库上的。
SL 的客户端软件的下载使用了 Amazon 的 S3 服务。
一点感想:MySQL 真是这波 Web 2.0 大潮中最大赢家之一啊
--EOF--
LAMP 与 LAOP
Oracle 这只大鲨鱼胃口越来越好了。LAMP (Linux, Apache, MySQL, PHP) 一直以来被视为一个非常完美的组合形式,现在 Oracle 或许有了想把 LAMP 中的 "M" 替换为 "O" -Oracle 的想法。LAOP, LAOP? 现在这还是我的猜测,起因是看到了这篇 Drupal + Oracle: Inside the OraDrup Project。
现在 OraDrup 项目还只是刚刚起步,Oracle XE 的确拉近了使用者与 Oracle 之间的距离,这个易于部署的版本一改 Oracle 过去"重"的形象,多少有点"轻量级"的意思,在中小应用上开始抢 MySQL 的地盘。LAOP 中的 O 有点牵强,却也是可以为之。
LAOP 中的 "P" (PHP)呢? Oracle 对 PHP 也是下了不少力气的。与 Zend 的倾力合作时间也不短了,Oracle 在 PHP 这一块的技术社区也逐渐做了起来。
至于 Linux 和 Apache ,对 Oracle 来说也是必争之地,苦心经营了多年。尤其是 Linux 服务器这一块,甚至不惜与多年的合作伙伴 Red Hat 交恶。
Oracle 会花多大力气来争夺这最关键的一环还真不好说,也或许只是一些 Oracle 技术爱好者的一厢情愿(或许更多是我的猜测:))。
再过一段时间没准 LAOP 这个缩写就流行起来喽,谁知道呢。
--EOF--
Bebo.com 采用 Oracle 数据库的一些数据
最近一期的 Oracle 杂志(电子版地址)中介绍了一家新兴的社会网络交友站点 Bebo.com 采用 Oracle 的一些信息。这是第一次看到 Web 2.0 公司采用 Oracle 数据库而不是 MySQL 。
Bebo 当前大约有 2700 万用户,每月大约有 40 亿 PV,而每月的增长率大约有 25%--非常惊人。所以有消息说 Google 发布的一份报告中,Bebo 被搜索的频度超过 MySpace。
Bebo 最开始使用的是 Oracle 标准版,运行在一个 2 CPU 服务器上, 操作系统是 SuSE 企业版。标准版是有一些局限性的,所以后来升级到了 Oracle 的企业版。Bebo 创始人 Michael Birch 介绍说,每天用户上传的图片量大约是 120 万张,需要保存为 5 种格式,这些(应该是图片的元数据等信息吧)都是通过数据库来处理的。并且已经构建了 Standby 数据库。
Oracle 把 Bebo 的经验作为 Oracle 在中小企业上的成功案例来介绍的。Bebo 最初为什么选用 Oracle ? "不能承受宕机损失, 不能允许丢失数据?" 如果是出于这样的考虑,那么成本高一点也是必需要承受的。
在 .com 的那一波浪潮中,Oracle 是大赢家之一,在 Web 2.0 这一次,MySQL 斩获不小。
--EOF--
MySQL 在逐渐背离开源么?
MySQL 在开源大旗的护翼下一路走到了今天,但是越来越多的迹象表明,MySQL 或许正在背离开源阵营。
从 ZDnet 这篇 Blog 看到的信息,MySQL 数据库社区版的新版已经不可以直接在MySQL 下载区获取。MySQL 社区版和企业版都是从同样的代码编译,区别是社区版包括了一些最新的特性以及实验性的增强功能,而企业版则更关注于稳定性。这个变化无疑会激怒 MySQL 社区的众多拥护者。
对于 MySQL 来说,有更多的用户去下载社区版未必是什么好事情,作为一家以盈利为目的的公司,MySQL 公司更希望用户能够购买他们的企业版。当然,价格不是那么便宜。天下或许有免费的午餐,但是免费午餐不可能永远都有。
在此前,MySQL 刚刚修改了数据库新版本的 GPL 版权说明,避免了在 PSF 发布 GPL v3 的时候当前版权信息自动升级到 V3。MySQL 或许只是不赞同 GPL v3,也不好说什么时候干脆连 GPL 也不要了。
从一颗小苗也快长成大树了,MySQL 的变化也符合业界的某些规律,开源爱好者们不过是一种工具而已。
--EOF--
Craigslist 的数据库架构
(插播一则新闻:竞拍这本《Don’t Make Me Think》,我出价 RMB 85,留言的不算--不会有恶意竞拍的吧? 要 Ping 过去才可以,失败一次,再来)
Craigslist 绝对是互联网的一个传奇公司。根据以前的一则报道:
每月超过 1000 万人使用该站服务,月浏览量超过 30 亿次,(Craigslist每月新增的帖子近 10 亿条??)网站的网页数量在以每年近百倍的速度增长。Craigslist 至今却只有 18 名员工(现在可能会多一些了)。
Tim O'reilly 采访了 Craigslist 的 Eric Scheide ,于是通过这篇 Database War Stories #5: craigslist 我们能了解一下 Craigslist 的数据库架构以及数据量信息。
数据库软件使用 MySQL 。为充分发挥 MySQL 的能力,数据库都使用 64 位 Linux 服务器, 14 块 本地磁盘(72*14=1T ?), 16G 内存。
不同的服务使用不同方式的数据库集群。
论坛
1 主(master) 1 从(slave)。Slave 大多用于备份. myIsam 表. 索引达到 17G。最大的表接近 4200 万行。分类信息
1 主 12 从。 Slave 各有个的用途. 当前数据包括索引有 114 G , 最大表有 5600 万行(该表数据会定期归档)。 使用 myIsam。分类信息量有多大? "Craigslist每月新增的帖子近 10 亿条",这句话似乎似乎有些夸张,Eric Scheide 说昨日就超过 330000 条数据,如果这样估计的话,每个月的新帖子信息大约在 1 亿多一些。归档数据库
1 主 1 从. 放置所有超过 3 个月的帖子。与分类信息库结构相似但是更大, 数据有 238G, 最大表有 9600 万行。大量使用 Merge 表,便于管理。搜索数据库
4 个 集群用了 16 台服务器。活动的帖子根据 地区/种类划分,并使用 myIsam 全文索引,每个只包含一个子集数据。该索引方案目前还能撑住,未来几年恐怕就不成了。Authdb
1 主 1 从,很小。目前 Craigslist 在 Alexa 上的排名是 30,上面的数据只是反映采访当时(April 28, 2006)的情况,毕竟,Craigslist 数据量还在每年 200% 的速度增长。
Craigslist 采用的数据解决方案从软硬件上来看还是低成本的。优秀的 MySQL 数据库管理员对于 Web 2.0 项目是一个关键因素。
--EOF--
安装 Joomla! 遇到的关于 MySQL 密码验证的问题
这两天我在尝试选择一个 CMS 系统,看过了网上的不少文章,在 CMS Matrix 站点上做了 N 次的对比表之后,决定采用 Joomla!。安装的时候,着实费了一点时间。
Joomla! 的官方安装文档倒是图文并茂的,但是还有些简略。第二步的时候,需要输入数据库的信息,主机名字,用户名,密码,还有数据库名字,可是总无情的弹出一个窗口告诉我 "Password and username incorrect..."。在终端命令行下,通过这些信息是可以登陆的。
RHEL 3 自带的 MySQL 版本比较低(3.23.58),启动比较麻烦,干脆跑到 MySQL 官方站点下载了一个 5.0 的稳定版本来用。
难道是版本太高带来的问题么 ?
尝试搜索了一下,原来是老问题:
A.2.3. Client does not support authentication protocol MySQL 4.1 and up uses an authentication protocol based on a password hashing algorithm that is incompatible with that used by older clients. If you upgrade the server to 4.1, attempts to connect to it with an older client may fail with the following message:
按照该帖子提示的用 OLD_PASSWORD() 重新设置了一下指定用户的密码,安装可以继续下去了。
登录到后台,测试了几篇帖子,发现 Joomla! 对中文的支持超出我的期待。
--EOF--
Movable Type 3.32 发布了, 升级么?
Movable Type 发布了 3.32 新版本: We've Updated; So Should You!, But, How We? 现在 MT 对 个人免费版本的支持真是越来越差了,谁让你不掏钱呢.
查看 Change Log(昨天这个 Log 还是看不到的) ,修复的 Bug 列表好长一串,还好,没有太严重的安全问题就成。
今天又看到 MT 的官方 Blog 在推荐 FastSearch 插件,不过这个功能是基于 MySQL 的 fulltext indexing 实现的,不知道对中文支持如何,可不要象 Feeds.app lite 插件那样乱码一片。
我个人最希望 MT 添加的一个功能是草稿自动保存, 很多次写了半天的东西因为浏览器不稳定,一下子就没有了,沮丧的心情难以形容。
--EOF--
GTD 工具 Tracks 在 Dreamhost 上安装备忘
在生活帮看到 一个开源的GTD系统-Tracks的介绍。去 Tracks 的网站上看了看,感觉是一个不错的 GTD 工具。决定在 Dreamhost 主机上尝试一下。
0.规划
准备起用一个单独的域名 GTD.dbanotes.net。相关文件安装在用户目录下的 gtd.dbanotes.net 目录。
1.准备环境
Tracks 使用 Ruby On Rails 开发的,所幸的是 Dreamhost 现在已经内建支持 Ruby On Rails 了。对于这一项几乎不需要任何额外的操作。
再确定数据库信息。创建一个单独的 MySQL 用户,然后记录该 DB 的主机名字等信息。
2.安装配置
在 Tracks 网站下载安装文件,当前的稳定版本是 1.041。解压所有文件到 gtd.dbanotes.net 目录下,安装指导也在,非常详尽,需要仔细阅读。然后参考文档作如下操作
cp config/database.yml.tmpl config/database.yml cp config/environment.rb.tmpl config/environment.rb
把目录 log.tmpl 重命名为 log。编辑文件 tracks/config/database.yml 把 'production' 与 'development' 这两个段需要的信息填入。'test' 段则不要修改。
编辑 config/environment.rb ,找到 change-me 修改为其他的。这个字段是用来加密密码的"盐",默认不改其实问题也不是很大。
在 gtd.dbanotes.net 目录下运行命令:
rake migrate
如果这个操作没有错误,Tracks 就可以跑起来了。
如果有必要,修改 安装目录下或者 public 目录下的 .htaccess 文件进行 URL 重写。
为了安全起见,把除了 public 目录之外的目录文件属性设为 700 。
参考我的 GTD.
3.后记
Tracks 这个东西内建了 WEBrick 这个 Web 服务器,所以如果你的机器支持 Ruby ,完全可以跑在本地 Windows 或者 Linux 或 Mac OS X 等各种操作系统上。这样使用体验会更好一些(我在 Dreamhost 上搭建的速度有些慢)。
Updated: 查看Tracks 截图效果 。如果需要测试用户请发送电子邮件给我: dbanotes@gmail.com .
-EOF-
两位 DBA 的站点被黑
今天收到消息, eygle.com 被黑了。anysql.net 的内容也放在 eygle 的服务器上,一起遭殃。入侵者删除了所有数据。eygle 与 anysql 都是国内 Oracle DBA 圈子知名人士,想不到。
说起这个事情, eygle 很是黯然:
被黑客攻击了,数据全被删除,eygle.com 宣布无限期关闭。
刚才去看,已经恢复了部分内容。不过据说是没有最近的备份,只能恢复到三月份的状态。损失可谓惨重。
不知道是不是"专注观察天上的星星,而没有注意脚下的坑",个人站点的备份也是需要时刻注意做的啊。
eygle 的站点我记得很久以前就曾经有过安全问题,留言版可以进行脚本攻击。后来改进了许多。不知道这次是不是被跨站脚本攻击(XSS),被取得 MySQL 登陆用户,进而提升到 root 。重新开放后,他的留言板还在使用,要当心。
Updated: 2006/08/04 据说又被攻击了, 这次是 DDos.
了解一下 Technorati 的后台数据库架构
Technorati (现在被阻尼了, 可能你访问不了)的 Dorion Carroll在 2006 MySQL 用户会议上介绍了一些关于 Technorati 后台数据库架构的情况.
基本情况
目前处理着大约 10Tb 核心数据, 分布在大约 20 台机器上.通过复制, 多增加了 100Tb 数据, 分布在 200 台机器上. 每天增长的数据 1TB. 通过 SOA 的运用, 物理与逻辑的访问相隔离, 似乎消除了数据库的瓶颈. 值得一提的是, 该扩展过程始终是利用普通的硬件与开源软件来完成的. 毕竟 , Web 2.0 站点都不是烧钱的主. 从数据量来看,这绝对是一个相对比较大的 Web 2.0 应用.
Tag 是 Technorati 最为重要的数据元素. 爆炸性的 Tag 增长给 Technorati 带来了不小的挑战.
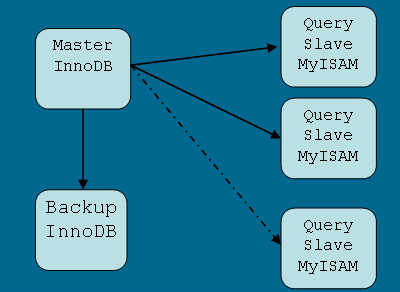
2005 年 1 月的时候, 只有两台数据库服务器, 一主一从. 到了 06 年一月份, 已经是一主一从, 6 台 MyISAM 从数据库用来对付查询, 3 台 MyISAM 用作异步计算.
一些核心的处理方法:
1) 根据实体(tags/posttags))进行分区
衡量数据访问方法,读和写的平衡.然后通过不同的维度进行分区.( Technorati 数据更新不会很多, 否则会成为数据库灾难)
2) 合理利用 InnoDB 与 MyISAM
InnoDB 用于数据完整性/写性能要求比较高的应用. MyISAM 适合进行 OLAP 运算. 物尽其用.
3) MySQL 复制
复制数据到从主数据库到辅数据库上,平衡分布查询与异步计算, 另外一个功能是提供冗余. 如图:
后记
拜读了一个藏袍的两篇大做(mixi.jp:使用开源软件搭建的可扩展SNS网站 / FeedBurner:基于MySQL和JAVA的可扩展Web应用) 心痒难当, 顺藤摸瓜, 发现也有文档提及 Technorati , 赶紧照样学习一下. 几篇文档读罢, MySQL 的 可扩展性让我刮目相看.
或许,应该把注意力留一点给 MySQL 了 .
--End.
重要图书: MySQL Stored Procedure Programming
看到有 Blog 说 Oracle PL/SQL 经典图书 Oracle PL/SQL Programming 的作者 Steven Feuerstein 出了本新书, 这应该不算什么太新鲜的事情,新鲜的是: 这本图书是关于 MySQL 存储过程的! 新书的名字是 MySQL Stored Procedure Programming , 出版商是 O'Reilly.
更值得注意的是, 第一作者是 Guy Harrison , 这位老兄是 Quest 软件的架构师(而 Quest 近年来也对 MySQL 的数据库工具推出了不少产品), 也是 Oracle SQL High-Performance Tuning 一书的作者。Oracle SQL High-Performance Tuning 在很长的一段时间内都曾经被一些 Oracle 优化专家推崇, 现在虽然有些过时, 但想起来没能被国内出版社及时引进, 仍然有些遗憾。
从 O'reilly 的宣传来看, 现在 Guy Harrison 的名头反而不如 Steven Feuerstein 响亮了(所以个别地方把 Steven 放到前面?), 也让人感慨.
"软件工业奥斯卡"和咱们其实关系不大
最近 CSDN 关于开源软件的一个新闻(旧闻?!)是 SYS-CON 的"读者选择奖". 国内很多喜欢拿来主义的 IT 新闻站点都纷纷报道,甚至真把这个奖提升到"软件工业奥斯卡"的高度来对待--看来中国人真是想奥斯卡想疯了.(所谓软件奥斯卡,不过是 SYS-CON 自吹自擂而已)
就我个人来说,一般对关于开源软件奖项只关心两个:一个是最佳图书,一个是最佳 Linux 数据库.可看选出来的结果,最佳图书是:The Linux Home Networking eBooks (Linux Home Networking) . 我 Google 了一下这本书,第一页居然没有发现相关信息.最佳 Linux 数据库居然是 Sybase Adaptive Server Enterprise (ASE) (Sybase).
这个"读者选择奖" 有 1.7 万多读者参与投票. 读者当然是 SYS-CON 的读者.我不知道有多少个中文开源用户参与了投票.就中文用户来说, 最佳 Linux 上的数据库无疑是 MySQL . 据我所知,国内在 Linux 上用 Sybase ASE 的用户恐怕掰着手指头都数得过来.看来"软件奥斯卡"和电影奥斯卡一样,喜欢搞冷门.
没有了MySQL,能用Linux做的事情多着呢
最近 Oracle 频繁收购开源厂商, 也有消息说 Oracle 也曾经试图收购 MySQL 未果, 一连串的事情引起了开源界的恐慌,估计也让不少开源爱好者都很闹心,今天居然在 CSDN 头条上看到了没有了MySQL,我们使Linux还能干什么这样的观点:
我宁可看到微软收购 Redhat、Mandrake等,也不愿看到 MySQL 被收购,因为在这之后将可能是 PostgreSQL 的覆灭,到了那时,我们还有什么理由继续使用 Linux 呢?
没错,这居然是 CSDN 的头条新闻. 这不知道这位开源爱好者怎么会作出这个有些可笑的结论.有必要讨论一下了。
被收购并不意味着会修改软件许可证方式.假定现在 MySQL 现在已经被某个大厂收购, 那么并不意味着这家收购方会冒天下大不韪,收购方可能会继续采用当前的许可模式,这样对那些期待免费使用的最终用户来说没甚么影响; 开源运动的实际推动者还是那些千千万万的软件爱好者,这一点不是以某个公司的意志能转移的。
修改软件许可方式不一定不是免费的. 我不知道那些 MySQL 的爱好者与使用者是重点关心软件价格的免费还是代码的开放, 据我的观察, 国内的 MySQL 最终用户中,直接因为某项功能而 Hack MySQL 源代码的少之又少,更多的都是直接拿来应用. 如果我的这一判断出入不大,那么 MySQL 被收购后不再开源,用户未必就一下子跑光了。
MySQL 不是唯一的开源数据库. 放眼望去,PostgreSQL、Ingres、FireBird等等优秀的开源数据库产品还有很多; 除了流行程度, 软件功能和 MySQL 相差都不大; 即使收购方扼杀了 MySQL; 广大开源用户还是有的"吃"。
MySQL 本身的血统并不那么高贵. MySQL 本来就是由商业公司在背后运作, 甚至本身的技术也多少依赖于开源软件界。如果说他被更大的商业公司收购的话,只能说他的商业运作成功,修成正果而已。咱何必奢求?
更多厂商的推出免费数据库. Oracle 推出了免费的 Express Edition DB, IBM 紧跟对手推出免费的 DB2 Express-C, Sybase、EnterpriseDB 等厂商也都有免费或开源的 DB 产品推出, 即使没有了 MySQL,我们的选择只会更多. "死了张屠户,也不用吃混毛猪".
如果这些理由还没有解除你的顾虑, 现在我们看看数据库之外的东西。
如何比较两个 Schema 的异同
有的时候, DBA 需要迅速找出来同一个 Oracle 数据库上或者不同数据库的两个 Schema 的差异.这种情况应该比较常见,比如测试数据库发布到产品数据库的时候,需要 DBA 做频繁的检查。
应对的办法之一是通过 Toad 这样的 GUI 工具来查找.具体操作应该是很简单的。Oracle 自带的 OEM 工具也有这样的功能( Oracle 变化管理工具包,不过不是免费的)。对于不喜欢图形工具的 DBA 来说, 用手工的方式更容易接受一些。如果已经建立了 Database Link ,可以通过类似如下的 SQL 简单的发现一些差异:
select * from user_tables@a minus select * from user_tables@b;
可以考虑先从 用户的 objects 入手,然后表->字段->索引 等等.
在 AskTom 上有一个关于 Schema 比较的讨论,以及一些参予讨论的人提交的 SQL 脚本。
今天测试了一个 Perl 脚本 Schemadiff, 这个工具分两个部分组成,一个执行 Perl 脚本加上一个配置文件。配置文件比较简单。看看就可以清楚。比较结果能够输出为 ASCII 文本与 HTML 两种格式。文本的结果比较类似 Unix 命令 diff 的输出.相对来说,比较直观的了.需要说明的是,使用这个脚本需要安装 DDL::Oracle 包。间接拒绝了对 Perl 不熟悉的朋友.
小评 Oracle 继续收购 Jboss、Zend、Sleepycat
最近又有一条 Oracle 的新闻吸引了不少人注意, 那就是 Oracle 准备收购开源厂商(Oracle's Open-Source Shopping Spree).目标锁定Jboss、Zend、Sleepycat 这三家.
从目前的一些消息看, 收购 Zend 似乎是已成定局. 对 Oracle 来说, PHP 的开源动力是一块肥肉, PHP 也俨然成为 Java/.net 之外的第三股开发力量. Oracle 过去也在 PHP 上投入了不少资源, 早在 2004 年 8 月就在 Application Server 中提供对 PHP 的支持(参见:Oracle 联手 Zend 推 PHP), 与 Zend 的合作看来感觉不错,所以财大气粗的 Oracle 还不如直接把 Zend 纳入麾下更加痛快。
收购 Jboss, 动机还是比较明显: 抢夺 BEA 与 IBM 的中间件产品。我一直比较奇怪, Oracle 为什么不收购 BEA ? BEA 的产品与客户都是 Oracle 比较垂涎的, 不过如果拿下 Jboss, BEA 与 IBM 的中间件产品市场相信会受到一定打击。间接的达到了目的。Oracle 这一步棋和收购 InnoDB 来断掉 MySQL 的后路有异曲同工之妙 .
推出 Wiki 服务
经过一段时间的测试后,本站推出测试版的 Wiki 服务: wiki.dbanotes.net. 内容将针对 Oracle 常用文档的维护. 也欢迎感兴趣的朋友们加入! TWiki 入手稍难一点,要有点耐心才好 :)
这段时间先后测试了 MediaWiki ,Trac, TWiki. 分别说说一点感受:
- MediaWiki: 不太喜欢 MediaWiki 的页面风格,虽然通过 CSS 可以重新定值; 基于 PHP , 我对 PHP 不太熟悉. 需要 MySQL 数据库,日后的迁移什么的都会有问题; 优点:在现在的 DreamHost 主机上安装比较容易;
- Trac 的安装复杂, 出了问题找不到相关文档,可定制化不那么灵活, 基于 Python, 修改代码不容易; 没插件;
- TWiki: 虽然速度稍稍慢了一点,新的 4.01 对性能作了一定的改进; 文档齐全, 基于 Perl( MT 也是基于 Perl),用户数多, 出了问题也便于求助. 不需要数据库,有插件;
更多参考:
TWiki DakarRelease安装备忘
Wiki发布系统的选型
经过衡量,决定采用 TWiki. 虽然现在的内容还不是很多, 不过这是一个好的开始. Wiki 的世界, 我来了!
本周言论 之 等我们的产品成熟起来时我才用
搜狐把博客做起来时我才用,一般我是等我们的产品成熟起来时才用。
--张朝阳 [来源]
评价一个东西好不好,最好仔细的用过,明白了,才好评论。如果看了一眼,甚至只是看了一眼别人的评论就去发表反对意见,很不合适。
--霍炬(virushuo)针对网友对爱搞搞Blog 工具的众说纷纭
我最开始做这个东西(Discuz!)就是为了找工作,首先这个软件本身会有很多人用,用了以后我就出名,出名以后我可以找一份好的工作,我不想念研究生或者在求学方面做进一步的尝试
--Discuz! CEO 戴志康 接受新浪采访所说.
用 Sitemap Generator 创建 Google Sitemap
今天偶然注意到 Google 对我的站内搜索数量锐减,从前一段时间的将近 1 万 变成现在的不到 1 千了.稍加分析了一下,原来在每篇文章的页面最上方也加了站点的描述内容,最初的目的完全是为了美观,没想到搜索引擎把这些页面都当作相似页面成处理了.雅虎和百度的站内搜索结果也是类似的.
不由得想起另一个问题: Google 的爬虫到底能不能遍历我的站内所有页面 ? 似乎不太可能.回想起 Google 的 Sitemap 也发布很久了, 并且不提供联机创建 Sitemap 的功能, 已经能够说明对很多比较复杂的站点 Google 仍有不足之处. Google 推这个工具的功能恐怕也是为了用户能从客户端把信息推到搜索引擎这一端(Google 用意).
此前我的站点 Sitemap 采用的是 MT 模板的方式 ,参考 Google Sitemaps using Movable Type , 这样我的旧站的内容就忽略掉了. 我现在使用的 Dreamhost 的服务,是支持 Python 的 ,并且可以 Shell 登陆, 准备用 Google 推荐的 sitemap-generator 来"帮助Google一下". 具体的操作在 Google 的帮助页面有很详细的说明. 需要注意的是,该工具要通过代理才可以下载,不知道其他人是不是也和我一样.
MySQL 5.1 新增的分区(Partitioning)功能
旧的技术新闻:MySQL 在 5.1.3 发布的时候新增了分区(Partitioning)功能。 在 MySQL 5.1 的手册中已经可以看到相关的技术描述。
MySQL 目前支持水平分区,也就是针对行的分区,主要有四种分区类型:
- RANGE 分区
- LIST 分区
- HASH 分区
- KEY 分区 --类似 HASH 分区,只是要根据用户定义的表达式来进行分区
MySQL 的 Key 分区类型,和微软的 Yukon (SQL Server 2005) 的分区方式很类似的,相对灵活一些,而 Oracle 的复合分区则为范围分区与 HASH 的结合体,这样略失灵活,但是便于管理。
提供一点免费虚拟主机服务
当前本站申请的虚拟主机在国外,有 4.8G 的空间(参考). MySQL 和可以托管的域名等都是无限制的.资源闲着也是浪费,所以准备友情提供一点免费服务:如果有技术圈子内的朋友自己有独立域名的,并且没有地方写 Blog 的,我可以提供免费托管.
这样做的目的: 提供技术交流的圈子,一个小试验田.(最好自己有独立的域名,也可以用 dbanotes.net 或者 OpenRSS.net 的子域名,不过这样流量都算 dbanotes.net 的拉,我并不希望这样.).这个圈子是 Open 的.
可以提供的便利说明: 可供使用的 Blog 软件有 WordPress 与 MT 两种.前者是"一键式"安装,维护起来比较方便;有 Shell/FTP 帐户可以登录.便于自己进行维护;还有其他软件可以提供:phpBB Forum / Advanced Poll / MediaWiki Wiki / Joomla (Mambo) CMS / Gallery Image Album 等.甚至支持 Ruby on Rails .
当然也有一点点要求:
- 不要发政治性的东西,这一条没的商量.
- Blog 请坚持原创,不要 Copy 来 Paste 去的.
- 尽量注意版权问题
- 因为有Shell可以登陆到虚拟主机上,请不要进行安全相关的测试或者是 Crack/伪黑客活动
- 非商业目的
免费的Oracle Database 10g XE
看来真的是免费的午餐越来越多了. 打开 OpenRSS 居然看到一堆和 Oracle 的免费数据库有关的新闻.这是真的! Oracle 居然也推出了一个免费(Free,价格的Free)的 Database 版本: Oracle Database 10g Express Edition .
Oracle 10g Express Edition (XE) 集成了 Oracle HTML DB 2.1 ,便于开发基于 Web 的应用. 当然,这个免费是肯定有功能限制的:只能用于单处理器,最多处理 4G 用户数据.并且支持的内存也不能超过1G. 但是可以肯定Oracle将会逐步放宽这些限制. 联想到 10 月份 Oracle 收购芬兰的数据库技术开发商 Innobase , 看起来 Oracle 是对 MySQL 这一块中小数据库的市场有兴趣不小: 先挖掉 MySQL的半块墙角,然后抛出个半成品探探开源的路.
目前已经有Linux 平台与Windows平台的 Beta 版本可以下载.
Gregarius , Ajaxed Online Rss Reader
第一次注意到 Gregarius 是在 Lilina 的论坛里面. 看到 Gragarius 之后,就想抛掉 Lilina 以及 Ajax-ed Lilina. 因为 本身存在的一些问题没办法解决,不得不放弃.从一个普通用户的角度上看,Lilina 存在的主要问题有:
- RSS 抓取速度太慢.尽管可以利用 Wget 工具在后台构建一个静态页面.但是 Lilina 订阅的种子数量还是不能太多.否则光解析就是灾难.
- RSS Feed 不能分类.所有的 RSS 都放到一起.看起来有点杂乱无章.
- 不支持数据库.
- 开发进度缓慢,基本上已经停止开发.也就是说出现问题能够得到的支持非常的少.
另外一个功能类似的 Feedonfeeds ,结构太松散了.而对比之下, Gregarius 的功能似乎让人惊讶. 我比较关注的几点如下:
- AJAX 能够带来更好的用户体验. 支持 AJAX 化的 Tag定制功能
- Supports themes and plugins 带来了良好的扩展性.
- Search in your feeds 具备查找功能 .
- 良好的 url_rewrite 设计.
- 支持 MySQL 和 SQLite
对 Gregarius 分析了几天之后,接着利用了几天的休息时间,把 Gregarius 在 OpenRSS.net 上搭建了起来.部署应该是个很简单的事情,但是因为是虚拟主机,遇到了很多问题.还好,大部分都已经解决.涉及到的问题大致有如下几个:
站点迁移到了国外
是不是前两天访问不到我的站点? 对这些朋友说声抱歉.这个站点这两天迁移到了国外,因为存在域名解析的问题,可能有的地方 DNS 同步比较慢.从今天下午的访问日志来看,基本正常了.
从桑林志那里看到 Dreamhost 的主机服务不错的,而且有打折的机会,就赶紧申请了一个. Dreamhost 的虚拟主机功能比较多,最便宜的一款送一个独立域名, 4.8G 的网络空间[2006/01/08: 现在是20G了,每个月1T 带宽(原来是20G)],支持 不限数量的 MySQL 数据库,支持 WordPress / MT 等 Blog 软件, 支持 Awstats 、甚至还有 Ruby on Rails ,吸引我的还有一点是,可以得到 Shell 帐号,其他的功能也很丰富,更为重要的是这些只花了 24 个美金,没错,只有 24 个美金.一年的费用是24美金,我用招行信用卡就可以付款.之后我也建立了一个折扣代码: FENNG . 在申请之后结算的那个地方输入即可。会立刻告诉你节省了多少钱。见下表:

申请 Yearly L1 是性价比最好的一款.
MT 升级到正式版本
杭州大雨! 作为一个北方人,最不喜欢这样无聊的雨.
MT 升级到正式版本! 因为有了前面升级的经验, 所以很顺利.让我比较郁闷的是 FTP 客户端用了一天多的时间才把所有的文件上传完毕.主要是速度太不稳定了.对 3.2 最满意的地方就是 spamlookup 这个插件太好用了.中文用户如果说还有欠缺的话,那就是"中文语言包"了.不过平声一笑说马上会制作的.估计也真的等不了多久.
第一次培训
今天晚上自己给公司的开发人员讲了一课。课程的题目是关于《Oracle SQL 基础与Tuning 》,是作为公司培训计划中的一个小课程(公司今年大小培训不断)。也是参加工作以来第一次给这麽多人正式讲东西。多少有点紧张的。
教材准备好了好久,今天还特地查找了一点资料。可是今天还是被同事发现了一个小Bug 。走上讲台的前几分钟比较紧张,感觉自己的语速也非常的快,没注意到自己是否有不安的小动作。加上这几天嗓子发炎,可能影响听课效果。
讲课这个事情其实是比较枯燥的,最怕的是自己词汇贫乏,或者是口头语,一着急的时候很容易重复曾经说过的词汇。关于口头语,我平时倒似乎不多,不过紧张的时候喜欢随便抓住一句临时作为口头语,影响表达力。自己其实是个有些失败的演讲者。印象中,只有一次曾经效果不错。今天这次课第一节是 Rudolf 老大讲的,那会儿教室里还不算热,到了我那一节,房间里面已经很闷了。真难为了听课的人--因为我讲的不太好
Blog 归来记
这个Blog offline 了足足有一个多月.
站点原来是放在我所在的上一家公司的主机上.因为一些变动,接替我的DBA告诉我空间不能继续用了.当时我正忙得一塌糊涂,根本没时间顾及,好在是把数据备份了出来.
有一段时间都不想继续写了,也是工作比较忙的缘故吧. 幸好 Tigerfish 答应给我一点空间.后来麻烦了 cometrue 不少次,不支持Perl,配置CGI-BIN,配置 Apache,安装DB_File 模块,解决 UTF-8 的显示问题, 总算是把 Blog 重新搭建了起来.其实ITpub本身也提供Blog功能的.可是我自己非常不喜欢这种 Blog 大集中的方式.加上其他种种原因,就放弃了在 ITpub 的那个Blog.
Google PR 更新以及其他
不期然感冒了,睡得昏昏沉沉,起来又是中午了。发现 Google 工具条的 PR 更新了。我的首页和 BLOG 都变成了 4 。虽然没啥大用处,还是很高兴!查了一下,居然是 1 日更新的(这里)。看看常去的几个 BLOG, Mark Rittman 的 PR 变成了6 。最近大家都在回顾2004,Rittman的 Review Of 2004, Part One ,Review Of 2004, Part Two 这两篇 BLOG 非常值得一看。相比之下,《程序员》杂志1月份的回顾数据库的这一年那篇文章有些儿戏了,大部分内容都是关于 MySQL 的。
个人技术站点维护工具箱
很多朋友都有自己的个人技术站点,技术站点一般来说是内容为王,不过易用性也是值得注意的地方,如何让用户更容易的访问您的站点并快速获取所需要的内容是个很有意思的话题。"工欲善其事,必先利其器",下面从我个人经验的角度介绍几个小工具。便于更有效地维护您的技术站点
推荐优先说明:开源 > 功能 > 易用性 > 灵活性
1 站点访问量统计工具:AWStats
访问量统计应该是网站必不可缺的功能之一,通过 Web 日志统计可以分析到用户习惯、站点的优缺点等,通过统计的反馈,可以有针对性的改进网站,提高站点质量,提升站点的人气度。当然,有的朋友对 Log 的分析也很关心-不过居然把访问日志导入到数据库中做统计,未免有些......不太灵巧。
AWStats (http://awstats.sourceforge.net )是站点统计的首选工具。Open Source 发布,功能不比商业工具逊色,而且,安装配置都比较简单。
关于 AWStats 的安装配置的指导文档好多,但是我认为车东的站点上的那篇指导文档是非常权威的。
AWStats站点 - http://awstats.sourceforge.net
AWStats:跨平台日志统计工具在Windows和GNU/Linux上的使用简介 by Che Dong - http://www.chedong.com/tech/awstats.html
2 页面标准验证工具
网站页面的有效性的问题不应该忽视,符合标准的页面更容易被搜索引擎收录,用户通过搜索也更容易找到相关内容。通过合理设计,页面也能被浏览器更为快速的装载,并可节省宝贵的带宽。
验证相对来说比较简单,可以到相应的站点提交链接即可,稍候片刻就会输出报告。也可以直接上传页面,还可以自己选择输出报告的内容与形式。然后有针对性的进行改进即可。
一些验证工具的地址:
W3C Markup 校验服务 - http://validator.w3.org/
W3C CSS 校验服务 - http://jigsaw.w3.org/css-validator/
Atom 与 RSS 校验服务 - http://www.feedvalidator.org/
robots.txt 校验服务 - http://www.searchengineworld.com/cgi-bin/robotcheck.cgi
3 链接有效性检验与网站地图制作:Xenu
如果网站布满死链接(broken links),用户访问起来肯定会兴味索然。即使站点维护者再加小心,百密一疏,难免有照顾不到的地方。 Xenu's Link Sleuth 是检查死链接非常有效的工具。Xenu 小巧,快速,操作方便,并可支持SSL的链接检测。支持 Windows 95/98/ME/NT/2000/XP,虽然没有提及 Windows 2003,不过在我的 Windows 2003 机器上也表现良好。
Xenu 还有一个很有用的功能--制作站点地图。检查站点完成之后即可选择提供报告,输出为 HTML 格式,稍加修饰就是一页不错的站点地图。本站的站点地图就是用 Xenu 制作的框架。
Xenu需要改进的地方:输出的HTML需要支持W3C标准。
Xenu的主页及下载地址: http://home.snafu.de/tilman/xenulink.html
个人技术站点维护工具箱
很多朋友都有自己的个人技术站点,技术站点一般来说是内容为王,不过易用性也是值得注意的地方,如何让用户更容易的访问您的站点并快速获取所需要的内容是个很有意思的话题。"工欲善其事,必先利其器",下面从我个人经验的角度介绍几个小工具。便于更有效地维护您的技术站点
推荐优先说明:开源 > 功能 > 易用性 > 灵活性
1 站点访问量统计工具:AWStats
访问量统计应该是网站必不可缺的功能之一,通过 Web 日志统计可以分析到用户习惯、站点的优缺点等,通过统计的反馈,可以有针对性的改进网站,提高站点质量,提升站点的人气度。当然,有的朋友对 Log 的分析也很关心-不过居然把访问日志导入到数据库中做统计,未免有些......不太灵巧。
AWStats (http://awstats.sourceforge.net )是站点统计的首选工具。Open Source 发布,功能不比商业工具逊色,而且,安装配置都比较简单。
关于 AWStats 的安装配置的指导文档好多,但是我认为车东的站点上的那篇指导文档是非常权威的。
AWStats站点 - http://awstats.sourceforge.net
AWStats:跨平台日志统计工具在Windows和GNU/Linux上的使用简介 by Che Dong - http://www.chedong.com/tech/awstats.html
2 页面标准验证工具
网站页面的有效性的问题不应该忽视,符合标准的页面更容易被搜索引擎收录,用户通过搜索也更容易找到相关内容。通过合理设计,页面也能被浏览器更为快速的装载,并可节省宝贵的带宽。
验证相对来说比较简单,可以到相应的站点提交链接即可,稍候片刻就会输出报告。也可以直接上传页面,还可以自己选择输出报告的内容与形式。然后有针对性的进行改进即可。
一些验证工具的地址:
W3C Markup 校验服务 - http://validator.w3.org/
W3C CSS 校验服务 - http://jigsaw.w3.org/css-validator/
Atom 与 RSS 校验服务 - http://www.feedvalidator.org/
robots.txt 校验服务 - http://www.searchengineworld.com/cgi-bin/robotcheck.cgi
这篇关于mysql 相关的一些东东,来自dbanotes的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




