本文主要是介绍[问题已处理]-[zabbix]-zabbix服务器cpu stuck,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天查看zabbix 监控的时候 突然发现zabbix 视图报警
Zabbix escalator processes more than 75% busy
对应的现象 服务器有点卡
连上服务器一看 我的天. cpu负载爆炸 而且呈现增加的趋势,sleeping进程太多.
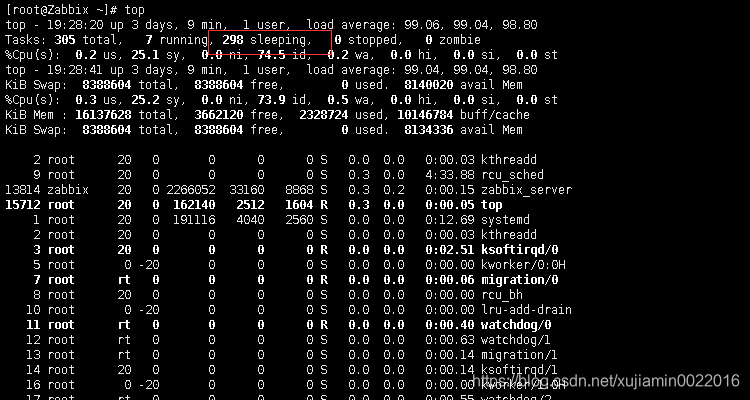
一堆调用报警的脚本

企图使用for循环杀死这些进程 无果!
for i in `ps -ef |grep ding_alarm |grep –v grep |awk '{print $2}'`;do kill -9 $i;done
这是脚本里 调阿里云api的命令

这些进程都处于不可中断的深度睡眠状态
for i in `ps -ef |grep curl |grep -v grep |awk {'print $2'} ` ;do kill -9 $i;done
居然发现kill -9 也杀不掉 有点可怕
找到这个动作 先禁用之后查看

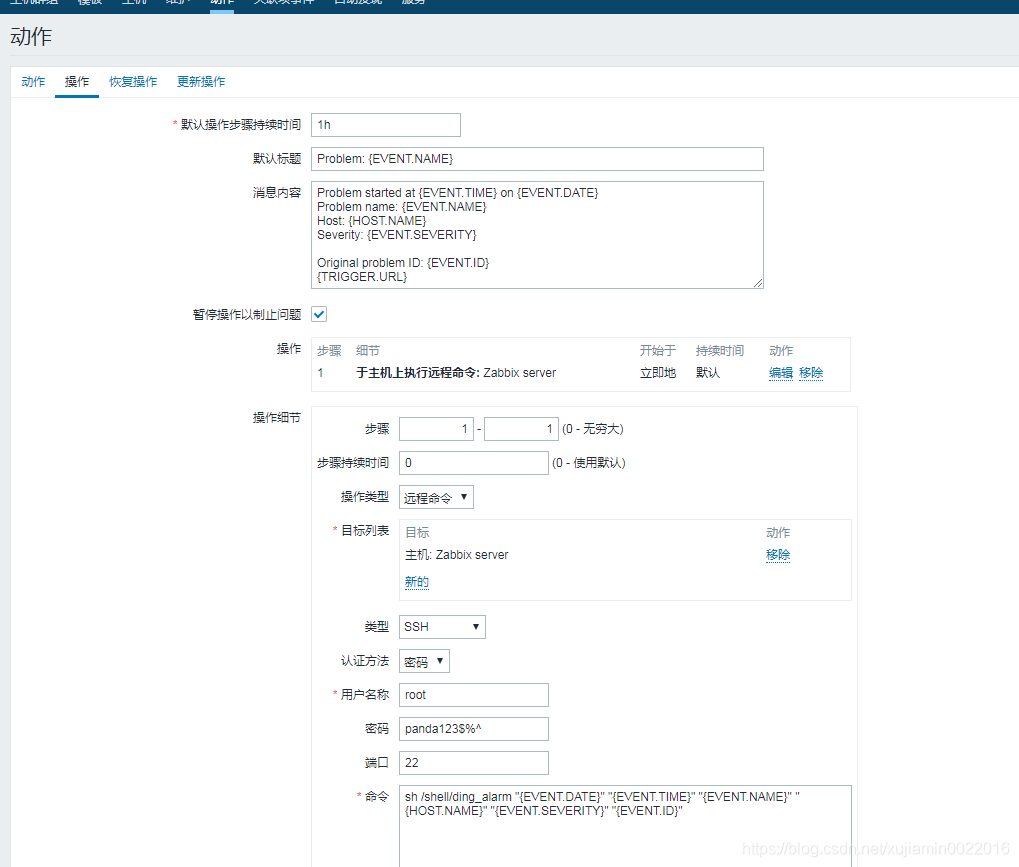
应该是同事离职之后 钉钉群解散了 机器人的token已经不存在了。然后脚本一直调不通。。
再找了下资料
D状态(disk sleep)进程用kill -9命令是不管用的,最简单的方法就是reboot, 除此还可以修改内核,将其进程状态转化为别的状态,然后kill掉。
测试服务器 能不重启当然选择不重启啦 尝试内核方式杀死D进程
1、在Linux下创建一个killd.c文件,该文件的信息如下:
#include <linux/init.h>
#include <linux/kernel.h> /*Needed by all modules*/
#include <linux/module.h>
#include <linux/sched.h> //for_each_process
MODULE_LICENSE("BSD");
static int pid = -1;
module_param(pid, int, S_IRUGO);
static int killd_init(void)
{
struct task_struct * p;
printk(KERN_ALERT "killd: force D status process to death/n");
printk(KERN_ALERT "killd: pid=%d/n", pid);
//read_lock(&tasklist_lock);
for_each_process(p){
if(p->pid == pid){
printk("killd: found/n");
set_task_state(p, TASK_STOPPED);
printk(KERN_ALERT "killd: aha, dead already/n");
return 0;
}
}
printk("not found");
//read_unlock(&tasklist_lock);
return 0;
}
static void killd_exit(void)
{
printk(KERN_ALERT "killd: bye/n");
}
module_init(killd_init);
module_exit(killd_exit);
2、同路径下创建Makefile文件,
//最前面的空格必须是tab键生产,否则编译产生错误Makefile:3: *** missing separator. Stop. 我就遇到了这个坑
内容如下:
obj-m := killd.o
all :
$(MAKE) -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules //最前面的空格必须是tab键生产,否则编译产生错误Makefile:3: *** missing separator. Stop.
clean:
$(MAKE) -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
3、在当前目录下执行make
报错
make: *** /lib/modules/3.10.0-957.21.2.el7.x86_64/build: 没有那个文件或目录。 停止。
查看了一下文件,是软连接,指向的文件已经不存在 mmp

4、进入/usr/src/kernels/下看有没有相应的内核开发包,没有,就安装,若有跳过第一步
UNAME=$(uname -r)
yum install gcc kernel-devel-${UNAME%.*}
或者wget 下载安装
wget http://vault.centos.org/7.6.1810/os/Source/SPackages/kernel-3.10.0-957.el7.src.rpm
不敢用find 因为yum都用不了,用了yum就卡住。

然后我 发现我的yum 进程在之前安装iostat的时候就已经卡住了
放弃治疗
进行reboot
远程reboot之后,连接断开了,但是服务器一直起不来,估计也是夯住了
得国庆放假结束 进行物理机重启了
原因分析大致猜测可能是下面2个原因
1故障的时候top查看到iowait并不高. 刚好这个报警邮件是调阿里云钉钉机器人的, 同事离职之后解散了钉钉群,这个钉钉机器人其实已经不存在了 (用了多个群和多个机器人来告警不同级别的告警信息) ,然后导致脚本请求的时候一直在等待响应. 积累了很多报警进程和curl命令的进程,都是由于故障号238482.所有的curl进程都在尝试发送同一条报警信息.然后钉钉api却没有给脚本返回值,等待的进程越来越多,以至于夯住了.
2 由于加入了10多台H3C服务器,zabbix配置没有进行修改,可能是当时mysql的数据库卡住了,iowait 比较高,导致进程全部进入D状态,后来io下来了,但是没有唤醒这些D进程.也可能是zabbix配置的默认配置太低,缓存和StartPoller个数太少
具体原因分析需要去服务器上看下当时的系统日志和内核信息.才能确认
10.8号检查了服务器,内核日志 没有看到异常。可能没看懂- -。
zabbix-server.log 和postgresql.log都是报错索引的问题,像是由于下面几条报错引起的
2019-09-30 00:00:24.980 CST [23438] 错误: 索引"history_uint_1"在块90623上包含未期望的零页
2019-09-30 00:00:24.980 CST [23438] 提示: 请重建索引 (REINDEX).
2019-09-30 00:00:24.980 CST [23438] 语句: select clock,ns,value from history_uint where itemid=35736 and clock<=1569772824 and clock>1569769224 order by clock desc limit 3
大概是数据查询和写入的时候 需要将脏页中的数据写入到磁盘,但是io不够,导致sql都在等待,然后查询sql因为索引损坏,查的也很慢,导致CPU负载持续上升。
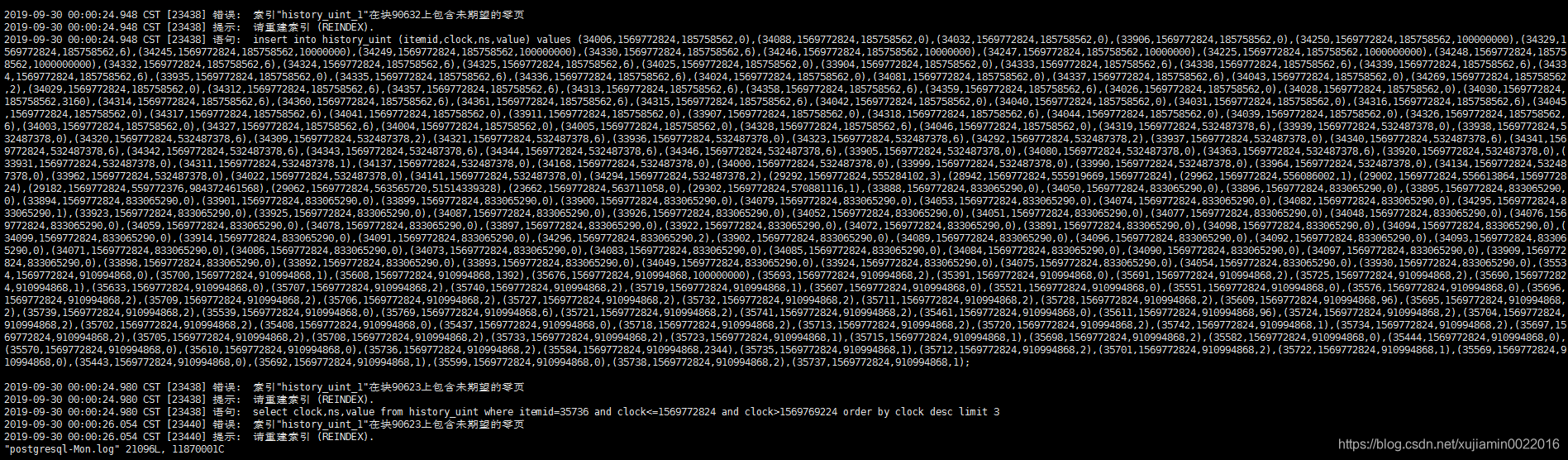
看到一篇也是zabbix的mysql报这个问题的博客
https://blog.51cto.com/3887111/1917400
history_uint损坏致mysql频繁重启导致zabbix_server关闭解决办法
参考https://blog.csdn.net/leishen1992/article/details/78634219
这篇关于[问题已处理]-[zabbix]-zabbix服务器cpu stuck的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






