本文主要是介绍【Git】安装和常用命令的使用与讲解及项目搭建和团队开发的出现的问题并且给予解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Git的简介
介绍
Git的特点及概念
Git与SVN的区别
图解
编辑 命令使用
安装
使用前准备
搭建项目环境
编辑 团队开发
Git的简介
介绍
Git 是一种分布式版本控制系统,是由 Linux 之父 Linus Torvalds 于2005年创建的。Git 的设计目标是为了更好地管理 Linux 内核代码的开发。相较于其他版本控制系统,如 SVN,Git 有更快的速度、更强大的分支管理功能、更好的适应性和更好的安全性。Git 现在已成为最流行的版本控制系统之一,广泛应用于软件开发和团队协作。
Git的特点及概念
分布式版本控制: Git 是分布式的,这意味着每个开发人员都拥有完整的代码库的副本,而不是依赖于集中式服务器。这使得开发人员能够独立工作,并在没有网络连接的情况下进行版本控制操作。
代码仓库: Git 使用仓库来存储代码和版本历史。一个仓库包含所有的代码、分支、提交历史以及配置信息。
提交(Commit): 提交是 Git 中的基本操作,它代表了代码库的一个快照,包括一组修改和相关的提交信息。提交是不可更改的,每个提交都有一个唯一的哈希标识。
分支(Branch): 分支是指代码库中的不同开发线,允许开发人员在不影响主要代码线的情况下进行独立的开发。Git 的分支操作非常高效,允许轻松创建、合并和删除分支。
合并(Merge): 合并是将一个分支的更改合并到另一个分支的操作。Git 提供了多种合并策略,以确保代码被合并到目标分支时不会引入冲突。
远程仓库(Remote Repository): 远程仓库是分布式团队协作的关键,它允许开发人员协同工作、共享代码,并在不同的位置之间同步代码。
克隆(Clone): 克隆是从远程仓库创建一个本地副本的过程。通过克隆,开发人员可以开始在自己的计算机上工作。
拉(Pull)和推(Push): 拉操作用于将远程仓库的更改同步到本地仓库,而推操作用于将本地更改上传到远程仓库。
标签(Tag): 标签是对特定提交的符号引用,通常用于标识版本或重要的里程碑。
Git与SVN的区别
Git 和 SVN 是两种不同的版本控制系统,虽然它们的目的类似,但有很多区别。以下是其中一些主要区别
分布式 vs 集中式:Git 是一种分布式版本控制系统,每个人都可以获取完整的代码副本并在本地工作,因此即使没有网络连接,也可以持续工作。而 SVN 是一种集中式版本控制系统,每个开发者只能获取代码的一个副本,需要访问集中式服务器才能进行工作。
分支管理:Git 的分支管理非常强大且易于操作,可以轻松地在本地创建、切换、合并和删除分支。而 SVN 的分支管理相对较弱,需要在服务器端进行操作,因此需要更多的权限。
速度:Git 的速度比 SVN 快得多,因为 Git 使用本地硬盘缓存,而 SVN 每次操作都需要从服务器获取数据。
可用性:Git 可以在 Windows、Linux 和 Mac OS X 等多个操作系统平台上运行。而 SVN 的 Windows 支持相对较差,通常需要依赖第三方工具。
数据完整性:Git 将数据保存在一个以 SHA1 校验和为基础的内容寻址文件系统中,从而可以防止数据损坏和篡改。而 SVN 依赖于中央服务器来保护数据完整性。
总的来说,Git 功能更加强大且灵活,适用于需要高效协作和分支管理的团队开发;而 SVN 则更适合单个开发者或较小的团队,不需要太多分支管理功能。
图解
 命令使用
命令使用
安装
在Git官网进行下载,( 下载2.2以上的版本 )
Git - Downloads
进入官网点击Windows

点击64下载

接下来我们开始安装,没有效果图显示的话,直接就默认跳过就行
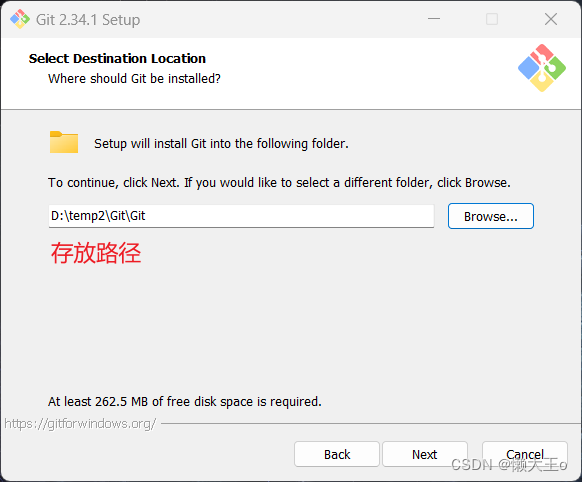
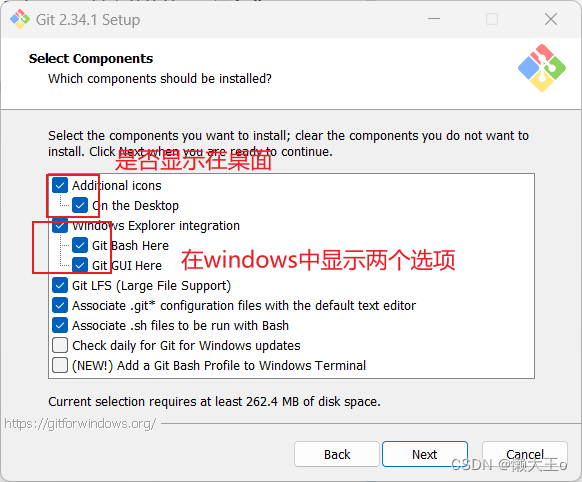




使用前准备
首先我们需要有一个gitee的账号,前往gitee的官网进行注册
Gitee - 基于 Git 的代码托管和研发协作平台
创建账号之后创建一个仓库。点击右上角的+号,并且点击新建仓库
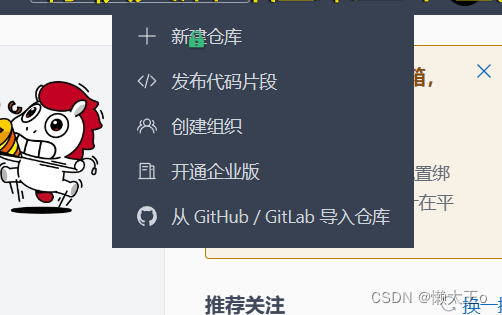
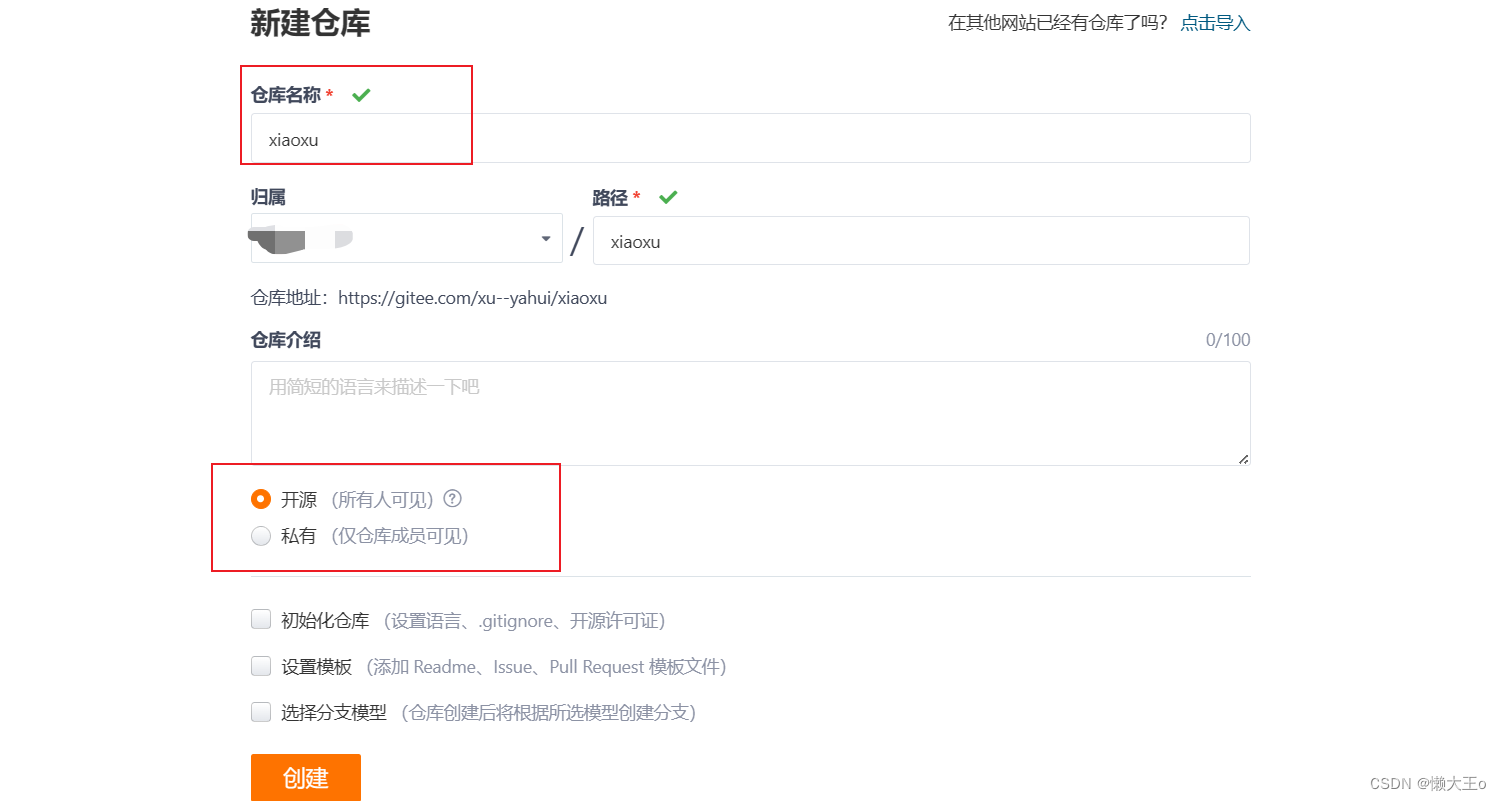
创建完成后,会有简易的命令行入门教程,如:Git 全局设置,创建 git 仓库,已有仓库?
将这些命令全部复制到一个文本文件中进行保存。
之后在本地的目录中,创建一个工作区间,来对项目的开发,在这个工作区间中,鼠标右键
点击Git Bash Here ,打开命令窗口。

打开窗口后,分别将Git 全局设置的命令输入其中分别执行一次。

执行完后,查看本地用户下有没有 .gitconfig 的这个文件,打开看看,和我们的信息是一样的
就OK了

之后根据 创建 git 仓库的命令,先创建仓库,在进入仓库,进入后将该仓库标记为Git管理的仓库


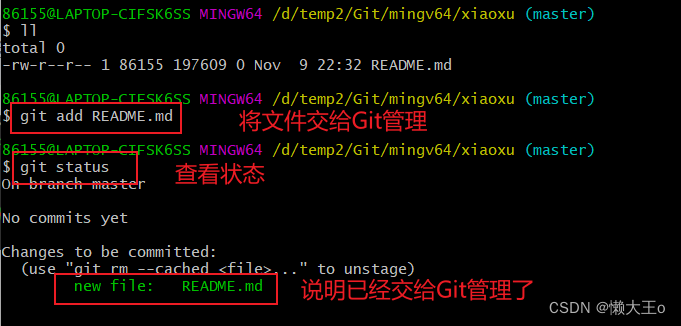
之后进行根据创建 git 仓库的命令,创建一个文件,再将文件给Git管理,之后查看状态
看到如图所示说明已经给Git管理,如果是红色说明没有。
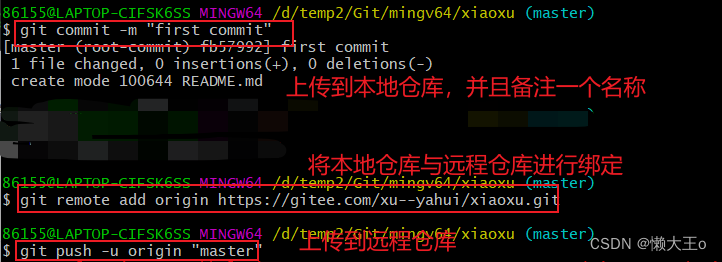
进行根据命令,上传到本地仓库并且给个备注,再将本地仓库和远程仓库进行绑定,绑定后,再将文件上传到远程仓库
本地创建绑定远程仓库时,会要输入Git账号和密码。
再到创建仓库完成的页面刷新,就会看到所上传的文件

搭建项目环境
将项目的文件夹复制到Git工作区间,再将这个项目给Git管理,并且仓库状态。
git add . 这个命令是将该文件夹下所有文件给Git管理

将项目上传到本地,并且给与备注,再将项目上传到远程仓库。

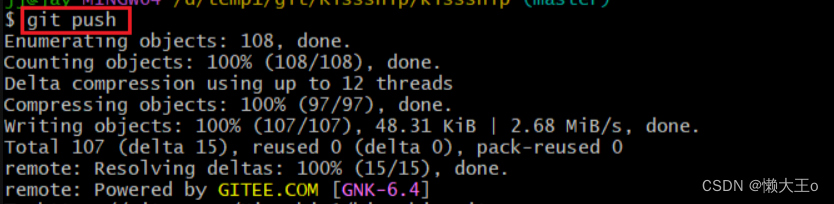 团队开发
团队开发
项目已经在远程仓库部署好了,现在比如 : 开发团队中其他人需要获取其中的项目。
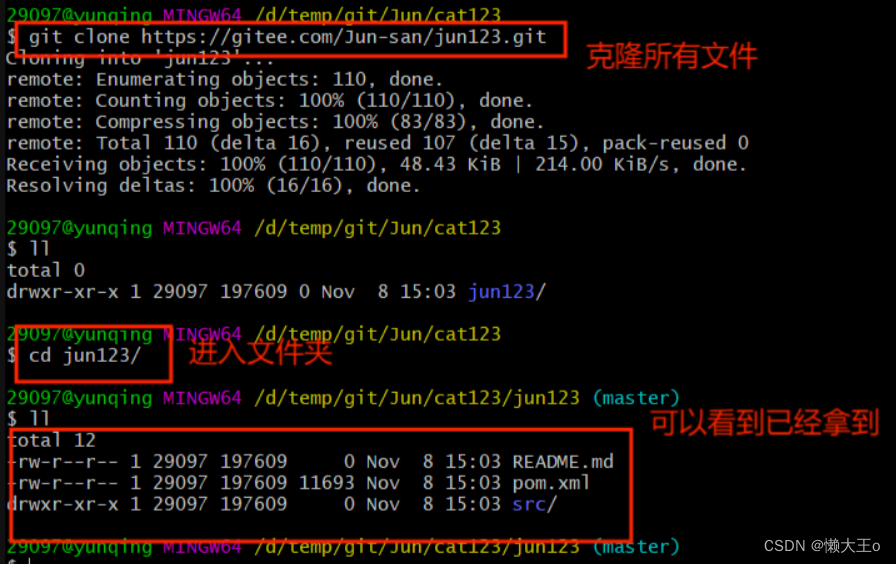
在这个需要获取其中项目的人中的工作区间,一样的,先点击Git Bash Here ,打开命令窗口。
在命令窗口中输入克隆远程仓库中使用文件的命令 :
git clone https://gitee.com/Jun-san/jun123.git
上面的网址是远程仓库的地址,在右上角有克隆的网址,谁需要就复制给谁即可,再加上
命令执行即可拿到所有的文件。

执行完成之后可以进入目录中查看到所有的文件
okok,今天就到这里结束了,咱们下次再见,下班下班!!!!!!!!!!!!!!
这篇关于【Git】安装和常用命令的使用与讲解及项目搭建和团队开发的出现的问题并且给予解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





