本文主要是介绍“第六十五天”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
固态硬盘:SSD
原理:基于闪存技术Flash Memory ,属于电可擦除ROM,即EEPROM;
由闪存翻译层和存储介质组成;闪存翻译层负责翻译逻辑块号,找到对应页,存储介质是由多个闪存芯片构成的,每一个芯片包含多个块,每个块包含多个页。
(固态硬盘的读取和写入是以“页”为单位的,在固态硬盘的内部结构中,数据存储在被称为“页”的小单元中。一般情况下,一个页的大小是4 KB或8 KB。这里也在提一下,外存由固态硬盘和机械硬盘,固态硬盘的读写单位是 “ 页 ” ,而机械硬盘的是 “ 扇区 ” ,主存的就是内存,是RAM(实际上是RAM和小部分ROM的结合),读取单位一般是 “字节”)
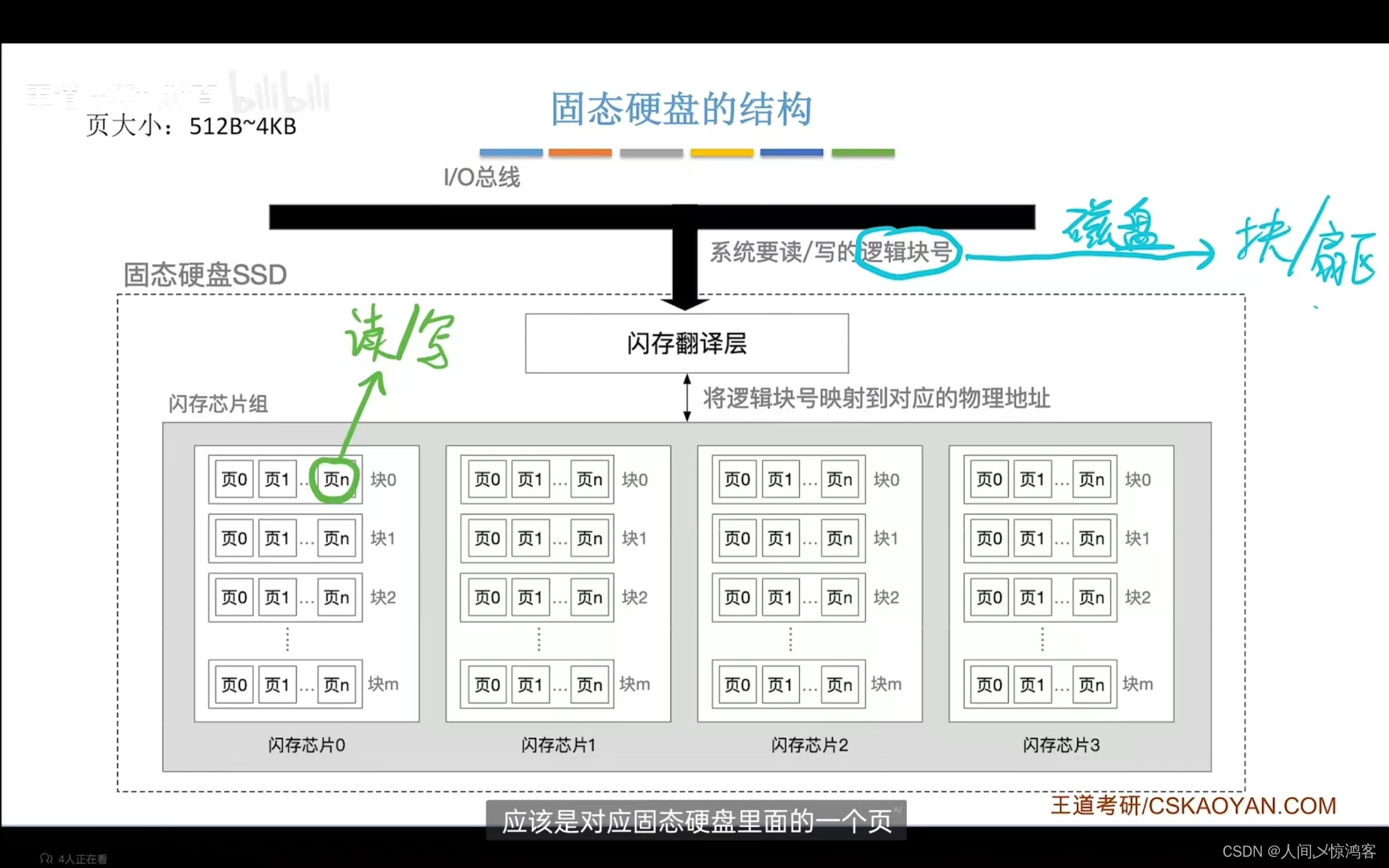
读写性能特性:以“ 页 ”为单位读写,相当于磁盘的“ 扇区 ” ,以块为单位“ 擦除 ”,擦干净的块,其中的每页都可以写一次,读无限次。 支持随机访问(机械硬盘是随机访问和顺序访问的结合),系统给定一个逻辑地址,闪存翻译层可通过电路迅速定位到对应的物理地址。(这里擦除前把块里面的其他页复制到一个新的块的过程中,数据的物理地址是发生改变的(有一个块到另一个块),但系统会自动地把这个新的物理地址映射到原来的逻辑地址) 固态硬盘 读快,写慢,因为要写的页如果有数据的话,需要先将块内其他页全部复制到一个新的(擦除过的)块中,再写入新的页。
与机械硬盘相比:SSD的读写速度快,随机访问性能高,用电路控制访问位置,而机械硬盘则是通过移动磁臂旋转控制访问位置,有寻道时间和旋转延迟。 SSD安静无噪音,耐摔抗震,能耗低,造假更贵。 SSD的一个 块 被擦除次数过多的话可能会坏掉(重复写同一个快),而机械硬盘的扇区不会因为写入次数太多而坏掉。(因为机械硬盘中,磁盘的扇区是通过改变磁性颗粒的磁化方向来存储数据的。SSD的闪存技术是这样的)

磨损均衡技术:思想:将“ 擦除 ” 平均分布在各个块上,以提升使用寿命 ; 对此有两种方式,动态磨损均衡,静态磨损均衡。前者是写入数据的时候,优先选择累计擦除次数少的新闪存块,后者是SSD监测并自动进行数据分配、迁移,让老旧的闪存快承担以读为主的储存任务,让较新的闪存块承担更多的写任务。
Cache的基本原理和基本概念:
我们的程序或者软件的数据都是存在辅存上的,当我们启动一个程序或者软件的时候,那么系统就会将对应的数据拷贝到内存上。然后CPU就从内存一条条的取指令处理数据,但内存的读写速度相对于CPU很慢,会导致速度矛盾。而我们在真正使用软件的时候,一段时间内我们通常使用的是其中的某个功能,而不是全部功能。比如我们再打视频电话的时候,CPU大概率需要的指令代码都是和"视频聊天相关的",于是我们便在内存和之间加入了一个Cache,Cache里面存储的就是内存中我们当前经常使用所需要的那部分代码,由于Cache的速度比内存快很多,那么CPU和内存之间的速度矛盾便得到了一定的缓解。(实际上,Cache是被集成在CPU内部的,通过SRAM实现,速度快,成本高 )
局部性原理:
空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的。如:数组元素,顺序执行的指令代码。
时间局限性:在最近的未来要用到的信息,很可能是现在正在使用的信息。如:循环结构的指令代码。
如果基于局部性原理的话,就可以把CPU目前访问的地址 “ 周围 ” 的部分数据放到Cache中。
基于上面,我们还需要界定什么是 “ 周围 ” ,对此我们将主存的存储空间 “ 分块 ” (主存地址进一步拆分为 主存块号 和 块内地址),主存和Cache之间以 “ 块 ”为单位进行数据交换 ,在操作系统中,通常将主存中的“一个块”也称为“ 一个 页/页面/页框”,Cache中的 “ 块 ”也称为 “ 行 ”。而每次被访问的主存块,一定会被立即调入Cache。
对于Cache的性能分析关于Cache的命中率和缺失率,访问方式也有两种,一种是先访问Cache,发现未命中再访问主存,另一种是同时访问Cache和主存,若Cache命中的话则停止访问主存。
Cache——主存的映射方式;
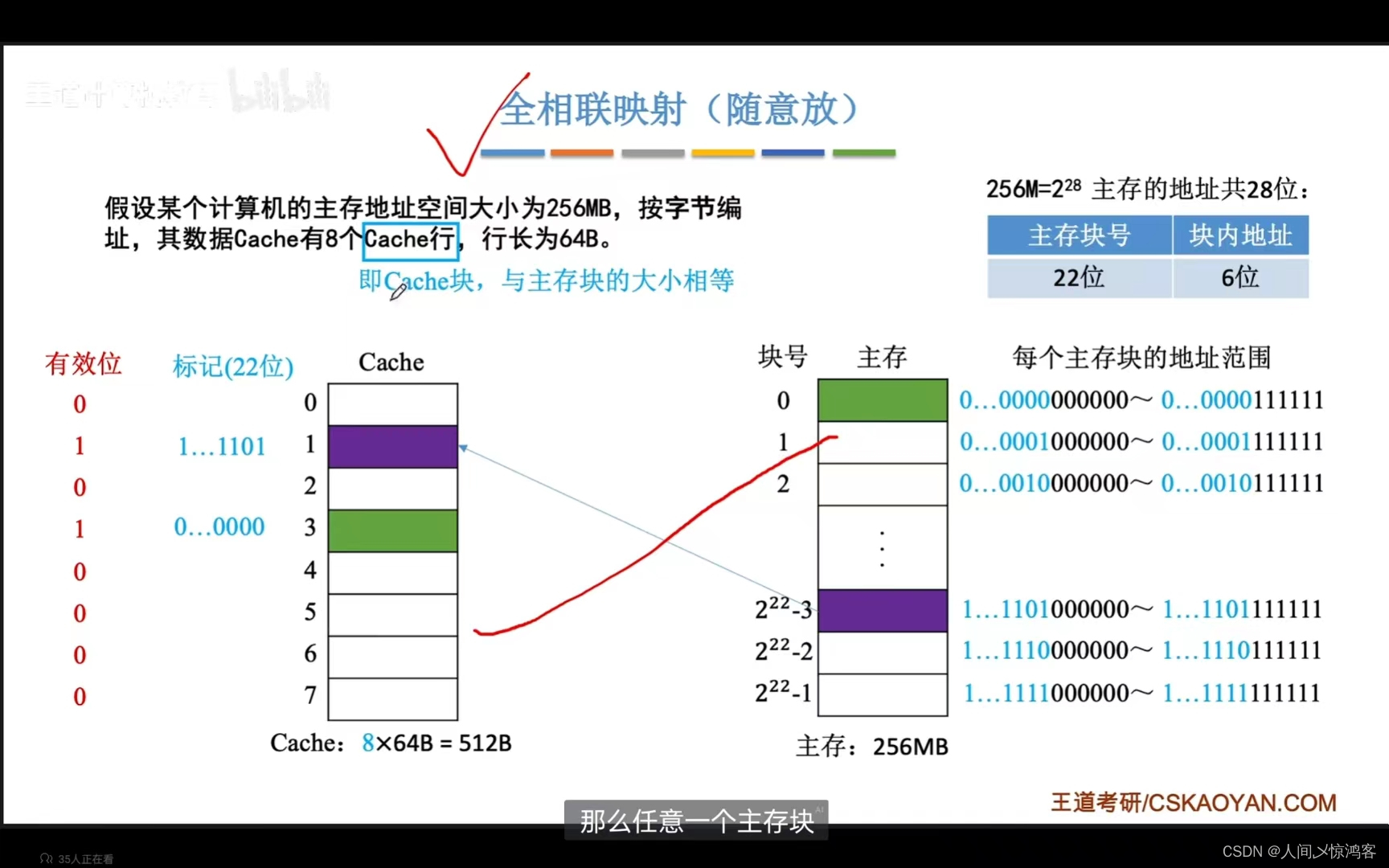
全相联映射:主存块可以放在Cache的任意位置;
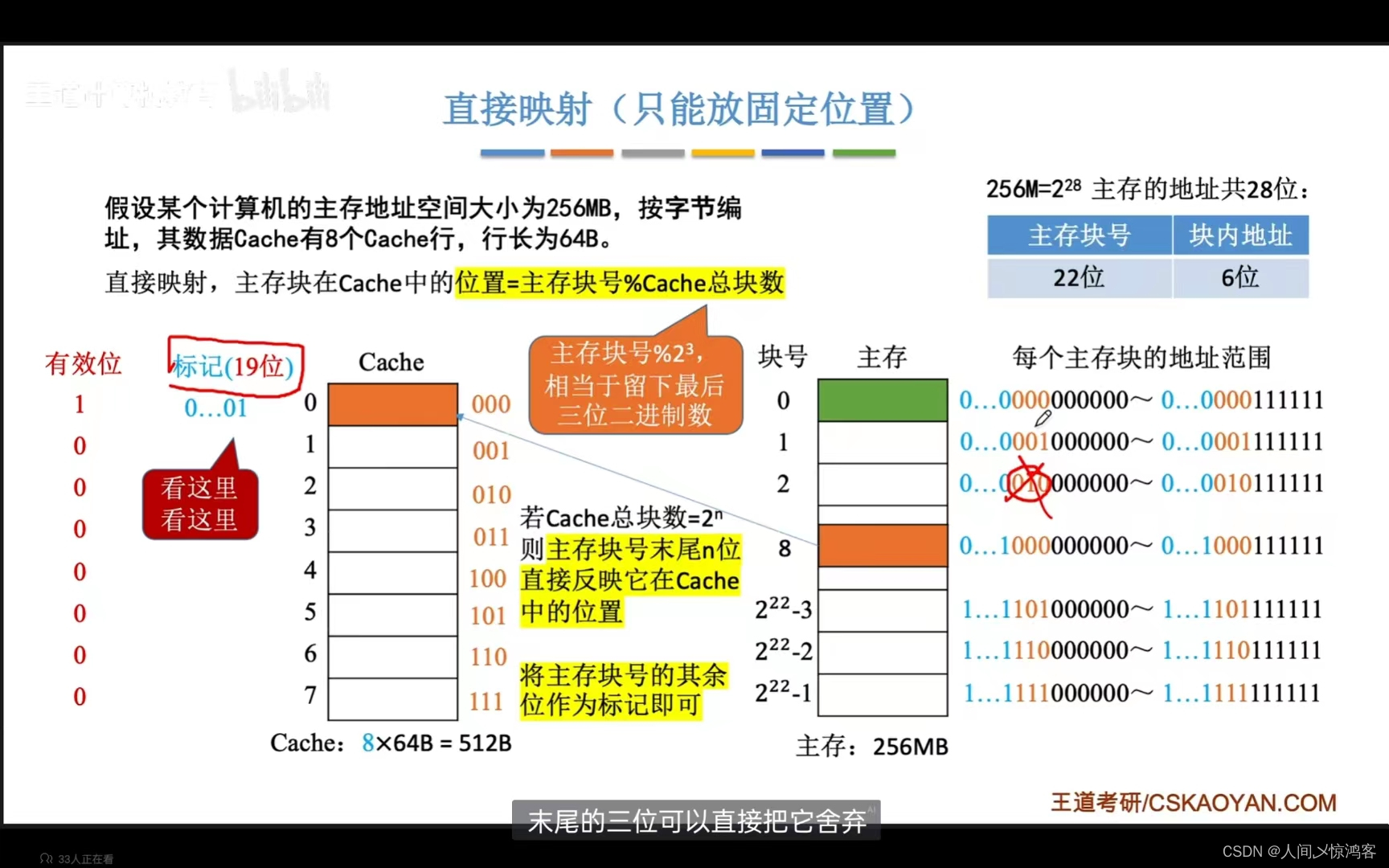
直接映射:每个主存块只能放到一个特定的位置,Cache块号 = 主存块号 % Cache总块数;
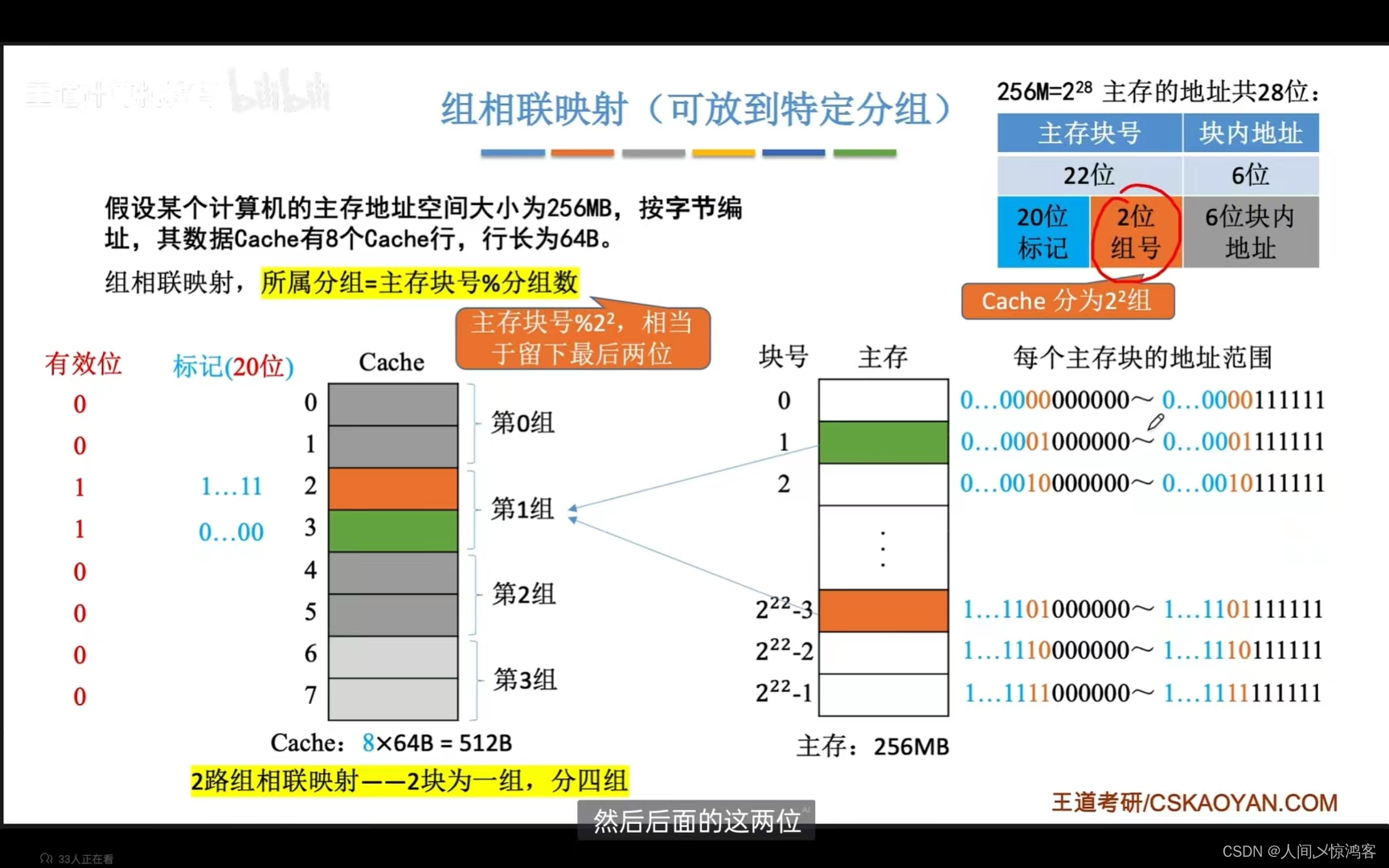
组相联映射:Cache块分为若干组,每个主存块可放到特定分组中的任意一个位置,
组号 = 主存块号 % 分组数 。
这里还是要提模求余这个东西看样子主要应用还真不是求余。

为了区分Cache中存放的是哪个主存块,需要给每个Cache块增加一个“ 标记 ”,用来记录对应的主存块号,除了标记外,还要增加一个有效位,来表示当前的Cache块是否存有数据。
全相联映射:随意放
对于全相联映射,主存的主存块有多少,标记就需要多少位,比如如果某个计算机的主存地址空间大小是256MB(B表示字节,b表示比特),按字节编址,其数据Cache有8个Cache行,行长64B,256MB对于的是2^28bit,也就是主存的地址共28位,由于Cache的行长是64B,则主存可以划为256MB / 64B=2^22个块,所以主存地址有22位的主存块号和6位的块内地址。所以Cache的标志也应该是22位,还要再外加一位的有效位,表示当前块是否被占用。
全相联映射,CPU访问主存地址的时候,先是把这个主存地址的前22位(以上面的例子为例,实际不一定)对比Cache中的所有块的标记, 如果标记匹配且有效位为 1 的话,则意味着Cache命中,便访问块内地址对应的单元 , 如果未命中,或者有效位为 0 ,则正常访问主存。
优点在于Cache存储空间利用充分,命中率高,缺点在于查找标记最慢,有可能要对比所有行的标记。
直接映射;只能放固定位置,主存块号%Cache总块数
对于直接映射(同样的以上面例子为例),实际上Cache的总块数如果视为 2^n,那么主存块号中末尾的n位都直接反映在它在Cache中的位置,比如上面的这个Cache有8行,也就是 2^3 ,那么主存块号的末尾三位就可以通过在Cache中的位置推断出来,如块号为8(1000)的放在Cache的行0(0000)(8%8)(0~7),块11(1011)放在Cache的行3(011),也就是模求余之后相当于留下最后n位的二进制数,我们可以利用这个特性对Cache的标志进行优化,也就是省略后面的n位,将主存块号的其余位作为标记即可,这样上例原本标记的22位就可以变成 19位。(这样主存的地址中主存块号又可以进一步划分为标记和行号,上例的原本的22位主存块号可进一步划分为19位的标记和3位的行号)。
CPU访问主存地址时,首先根据主存块号的后n位的行号确定Cache的行, 然后如果主存块号的前m位(m等于主存块号减去行号n,也就是标记的位数)与Cache标记匹配且有效位为1,那么Cache命中,访问对应的地址单元, 若未命中或者有效位为 0 ,则正常访问主存。
优点在于对于任意一个地址,只需要对比一个标记,查找标记最快,缺点在于Cache存储空间利用不充分,命中率低。
组相联映射:可放到特定分组,所属分组=主存块号%分组数
这个和直接映 射时有点类似的,更像是前面两种的中和,把Cache的多个行分为若干个组,比如上面的8行分为四组,一组有两个块,这样同样的分组数如果是2^n,那么主存块号中末尾的后n位就表示组号,在第几组,这样的话标记位数可能不如直接映射那么少(比如这里四组是2^2,那么标记就是20位,而直接映射是19位),那也是映射更加灵活(直接映射的话,主存的第n块,只能映射到对应到Cache的一个块,而组相联映射的话,主存的第n块,映射到的是Cache对应的一个组,这个组里面的块只有没有被占,就都可以放)。(主存块号这里可以划分位标记和组号)
CPU访问主存地址,首先根据主存块号的后n位(这里的n对应的是组号),确定所属分组号,然后和组里面的块挨个比较,如果主存块号中的标记和分组内的某个标记匹配且有效位为 1 ,那么命中,访问对应的单元,若没有命中或有效位为 0 ,则正常访问主存。
优点缺点实际上就是上面两种方式的折中,综合效果较好。
n路组相联映射——每n个Cache行为一组。
这篇关于“第六十五天”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

