本文主要是介绍Java系列之:字符串UTF-8 编码格式转换位 UTF-32 【生僻字截取问题】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。
前言
在项目开发中遇到这样一个需求,就是要将包含生僻字字符串的首字母屏蔽为 * ;比如:𣓃𬱖㛃依䶮 屏蔽后为 *𬱖㛃依䶮 。如果使用一般的substring()字符串 截取会出现异常异常,有些生僻字是有两个汉字组合而成。切割的时候 会截取一半、导致剩下部分出现意外。
解决方法
改变字符的编码格式,将UTF-8的编码格式 转换为 UTF-32 的编码格式,这样,每个字符都占用4个字节,截取的时候,按四位字节截取就可以有效解决这个问题。有关UTF-32 编码的介绍如下图

代码案例
方法说明
-
String的getBytes()方法是得到一个操作系统默认的编码格式的字节数组。例如:byte[] orignalUTF_32 = TransferString.getBytes("UTF-32");将得到UTF-32编码格式的字节数组。 -
与getBytes相对的,可以通过
new String(byte[], decode)的方式来还原字符串。例如:String result = new String(afterUTF_32,"UTF-32");可以将这个字节数组 再次还原为原来的字符串。
UTF-8 转换为 UTF-32
String TransferString = "𣓃𬱖㛃依䶮"; byte[] orignalUTF_32 = TransferString.getBytes("UTF-32");System.out.println("UTF-32 字节长度:" + orignalUTF_32.length);
输出如下:UTF-32 字节长度:20 这个时候,每个字符都占用 4个字节。
看一下如果是UTF-8编码 字节的长度是:
String TransferString = "𣓃𬱖㛃依䶮"; byte[] orignalUTF_8 = TransferString.getBytes("UTF-8");System.out.println("UTF-8 字节长度:" + orignalUTF_8.length);
输出如下:UTF-8 字节长度:17 这个时候每个字符 占用字节长度不一致,就不容易处理。
代码实际案例
中间对字节数组进行截取操作,如果是UTF-32 编码的,四个字节对应一个字符。就可以方便操作。然后将截取后的的字节数组 再次转换为 字符串。
@org.junit.Testpublic void testdemo02(){try {String TransferString = "𣓃𬱖㛃依䶮"; //处理隐藏第一个字符byte[] orignalUTF_32 = TransferString.getBytes("UTF-32");int lastIndex = orignalUTF_32.length;byte[] afterUTF_32 = Arrays.copyOfRange(orignalUTF_32,4,lastIndex);//截取String result = new String(afterUTF_32,"UTF-32");String TransferStringSub = "*"+result;System.out.println(TransferStringSub);}catch (Exception e){}}
查看几个实际转换的例子:
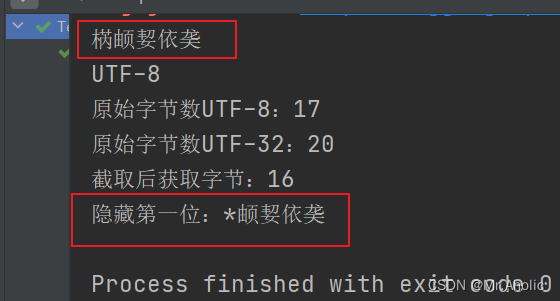
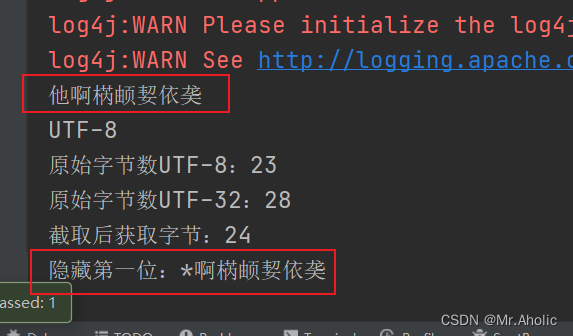
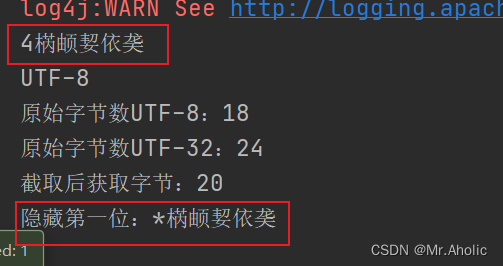
这篇关于Java系列之:字符串UTF-8 编码格式转换位 UTF-32 【生僻字截取问题】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





