本文主要是介绍SpringCache(Redis),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、springcache是什么
springcache是spring的缓存框架,利用了AOP,实现了基于注解的缓存功能,并且进行了合理的抽象,业务代码不用关心底层是使用了什么缓存框架,只需要简单地加一个注解,就能实现缓存功能了。而且Spring Cache也提供了很多默认的配置,用户可以3秒钟就使用上一个很不错的缓存功能。
二、为什么需要springcache
通常来说,在WEB后端应用程序来说,耗时比较大的往往有两个地方:一个是查数据库,一个是调用其它服务的API(因为其它服务最终也要去做查数据库等耗时操作)。
使用缓存是一个很“高性价比”的性能优化方式,尤其是对于有大量重复查询的程序来说。
三、如何使用Spring Cache
常用注解
分别为@Cacheable、@CachePut、@CacheEvict、@Caching、
@CacheConfig。
除了最后一个CacheConfig外,其余四个都可以用在类上或者方法级别上,如果用在类上,就是对该类的所有public方法生效,下面分别介绍一下这几个注解。
- @EnableCaching
开启缓存注解功能,通常加在启动类上 - @Cacheable
表示这个方法有了缓存的功能,方法的返回值会被缓存下来,下一次调用该方法前,会去检查是否缓存中已经有值,如果有就直接返回,不调用方法。如果没有,就调用方法,然后把结果缓存起来。这个注解一般用在查询方法上。 - @CachePut
加了@CachePut注解的方法,会把方法的返回值put到缓存里面缓存起来,供其它地方使用。它通常用在新增方法上。 - @CacheEvict
使用了CacheEvict注解的方法,会清空指定缓存。一般用在更新或者删除的方法上。
value: 缓存的名称,每个缓存名称下面可以有多个key
key: 缓存的key ----------> 支持Spring的表达式语言SpEL语法 - @Caching
Java注解的机制决定了,一个方法上只能有一个相同的注解生效。那有时候可能一个方法会操作多个缓存(这个在删除缓存操作中比较常见,在添加操作中不太常见)。
SpEL
spring EL ,spring 的一种表达式语言;
在注解后的参数中使用
/*** CachePut:将方法返回值放入缓存* value:缓存的名称,每个缓存名称下面可以有多个key* key:缓存的key*/@PostMapping@CachePut(value = "userCache", key = "#user.id")//key的生成:userCache::1public User save(@RequestBody User user){userMapper.insert(user);return user;}
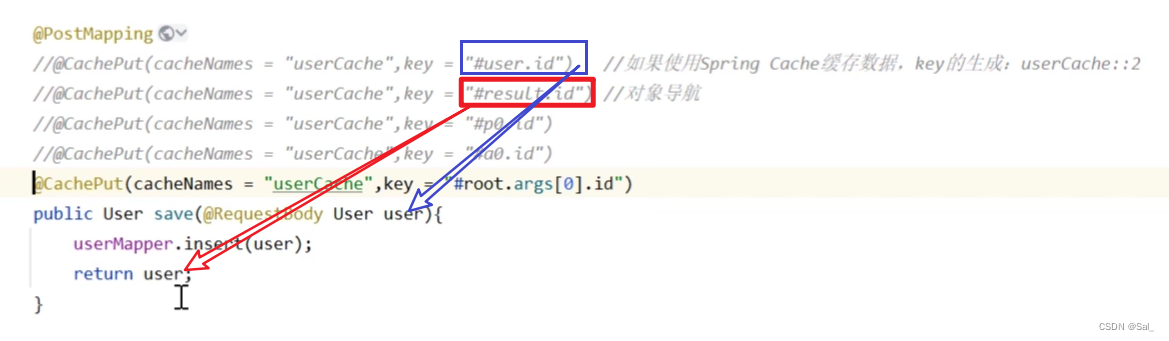
说明 key的写法如下
-
#user.id :
#user指的是方法形参的名称, id指的是user的id属性 , 也就是使用user的id属性作为key ; -
#result.id :
#result代表方法返回值,该表达式 代表以返回对象的id属性作为key ; -
#p0.id:
#p0指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key ; -
#a0.id:
#a0指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key ; -
#root.args[0].id:
#root.args[0]指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key ;
分三步:加依赖,开启缓存,加缓存注解。
以使用Redis为例
依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>
启动类
在启动类添加 @EnableCaching 注解;
实现类
方法上加入@Cacheable注解
@PostMapping@ApiOperation("新增套餐")@CacheEvict(cacheNames = "setmealCache",key = "#setmealDTO.categoryId")//key: setmealCache::100public Result save(@RequestBody SetmealDTO setmealDTO){setmealService.saveWithDish(setmealDTO);return Result.success();}
这篇关于SpringCache(Redis)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





