本文主要是介绍兴达易控232转profinet在搅拌站使用案例配置案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
该搅拌站所采用的是双行星动力搅拌桨混合机,借助兴达易控232转profinet网关(XD-PNR200)与PLC和变频器进行通信,从而实现对变频器的精确控制,大大提升了搅拌过程的稳定性和效率。
这一方案还具备高度的灵活性和可扩展性,使得搅拌站能够适应不同生产需求的变化。通过使用先进的控制系统,该搅拌站能够实现精确的参数设置和调整,从而确保搅拌过程的质量和一致性。

下面进行配置:
打开博图,添加PLC;本案例使用的是1200PLC。
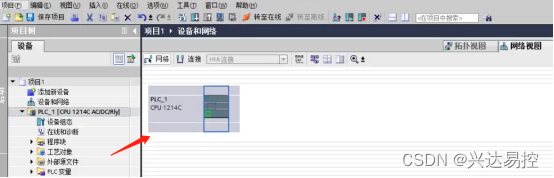
添加GSD文件
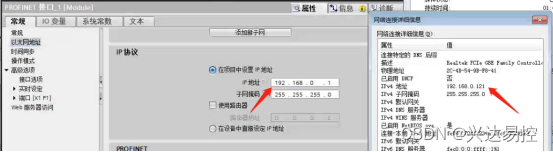
配置PLC的IP地址(PLC的IP地址应与本机的IP地址保持在同一网段上)
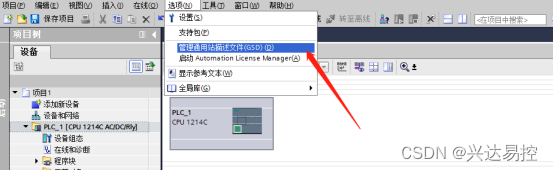
在网络视图下找到硬件目录并点击进入,在硬件目录下找到本网关驱动XD-PNR,双击添加到博图
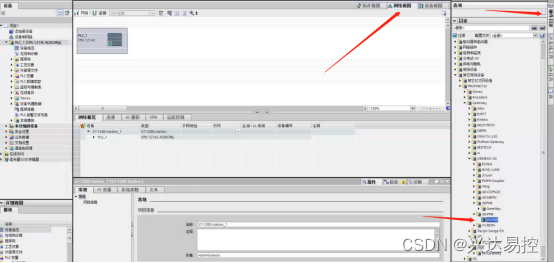
在博图里连接PLC与网关
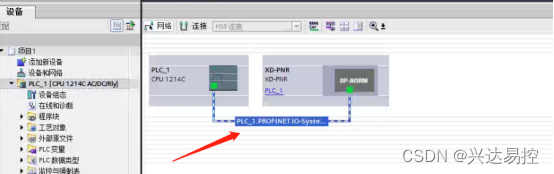
双击网关配置IP地址(应与PLC的IP地址保持在同一网段上)
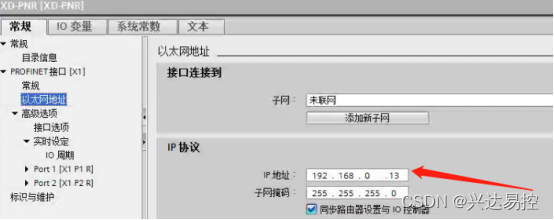
右击分配网关设备名称
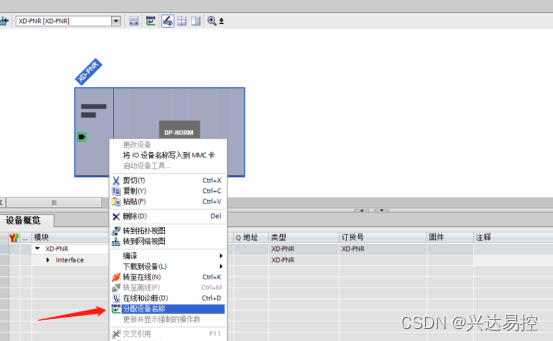
点击更新列表,自动搜索到网关,选中搜索到的设备,点击分配即可
在设备目录下找到硬件目录并点击,设置数据读写长度,在这里设置读4个数据长度,写4个数据长度
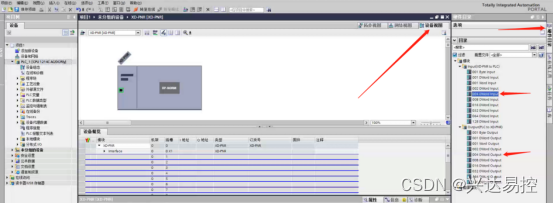
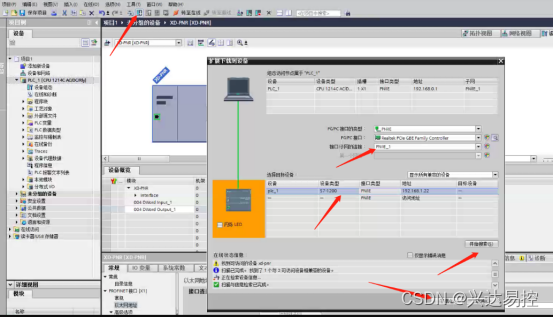
找到工具栏中的下载按钮并点击,点击“接口/子网的连接”的下拉菜单选择PN/IE_1插槽,点击搜索,选中自动搜索到的设备,点击下载,按照提示往下操作即可
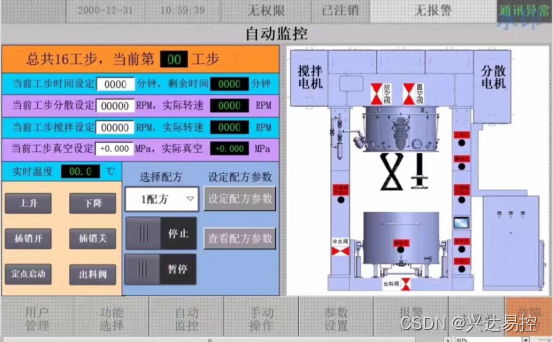
触摸屏显示画面
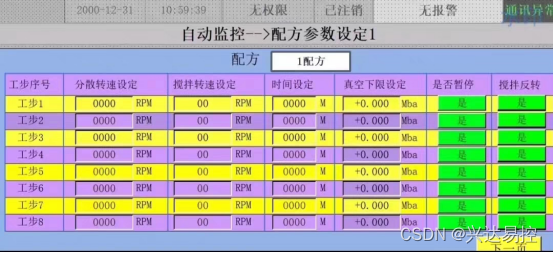
监控数值画面
兴达易控232转profinet网关(XD-PNR200)作为连接器,能够实现PLC与变频器之间的数据传输和信号转换。这样,PLC就能够准确地控制变频器,调整其运行状态和参数,以应对不同的工艺需求。通过这种方式,生产线的自动化过程更加智能化和自动化,提升了生产效率和质量,降低了人工操作的风险和成本。

这篇关于兴达易控232转profinet在搅拌站使用案例配置案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








