本文主要是介绍GPTZero:论文打假神器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
记住这张脸他是全美学生的公敌。

别的学生在AI大浪潮间翻云覆雨,有的用GPT代写作业,有的用GPT代工论文,大家都忙的不亦乐乎。
正在大家都在欢呼雀跃跟作业拜拜时,就是这个小伙,普林斯顿大学的华裔小天才Edward Tian却反其道行之,用喝杯咖啡的功夫写了个专门检测文章是否由机器代写的照妖镜:GPTZero,它从文本困惑性和突发性入手,Zero背靠统计学的打分,得分越低就越可能被锤为AI代工。
在线体验网址:https://gptzero.me
看我先让GBD4随便写篇论文,再把生成的论文喂给Zero,Zero立马开锤:你的文章有AI代工嫌疑。
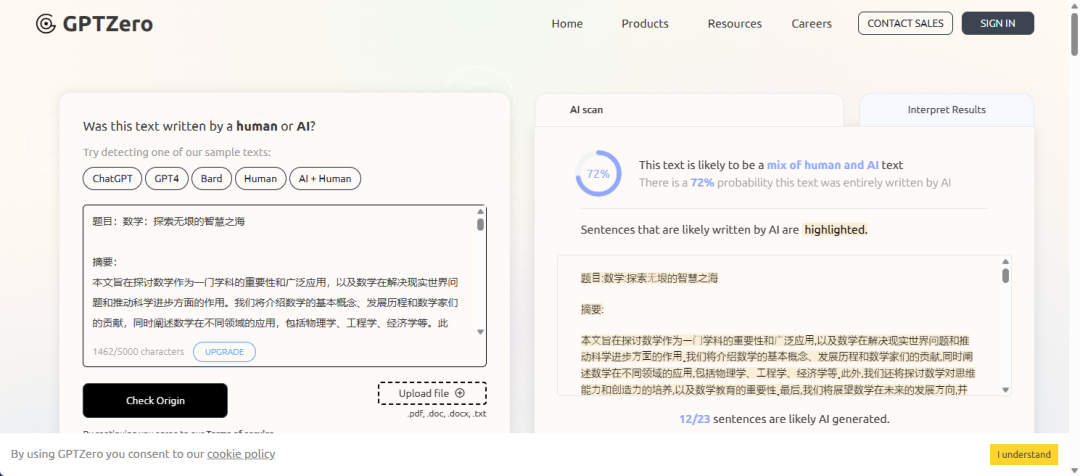
再换一篇真人写的论文测测,这次啊就喜获Zero颁发的合格证书。
(我用GPT Zero去检测我在微信公众号写的原创文章时,很多都被标记为AI代工,可能是我经常使用GPT,已经被同质化了吧)
神器一出,老师狂喜,而Edward Tian一夜成为学生公敌,哀嚎一片。
而不听劝的Edward Tian一边忙着不断修正肌肉的准确度,一边成功得到350万美元的融资和几十家教育相关组织建立合作关系。誓要帮助他们擒住AI间谍。
用魔法打败魔法,不管这事成没成,光反论文这事已经够他名垂青史了。
GPTZero是如何工作的?
在其核心,GPTZero是一个经过训练来进行推理的AI模型。它可以筛查文本 - 无论是句子、段落还是整篇文档 - 并预测这些文本是由人类编写的还是由AI生成的。它就像一只猎犬,可以从海量的文字中嗅探出AI内容。
GPTZero是通过一个大规模的人类编写和AI生成文本的数据集进行训练的,这些数据集从未在互联网上发布过。它被教会识别风格、结构以及其他语言特征中的细微差异,这些差异可以区分人类写作和AI内容。
为了判断一段摘录是否是机器人写的,GPTZero使用了两个指标:“困惑度"和"突发性”。困惑度测量文本的复杂程度;如果GPTZero对文本感到困惑,那么文本具有较高的复杂性,更有可能是人类编写的。但是,如果文本对机器人来说更为熟悉 —— 因为它已经在这种数据上进行了训练 —— 那么文本的复杂性会较低,因此更有可能是AI生成的。
另外,突发性是用来比较句子变化的。人类倾向于书写具有更高突发性的文本,例如,一些较长或复杂的句子与一些较短的句子混合出现。而AI生成的句子倾向于更统一。
参考资料:
[1]视频号:科技公园
[2]https://www.npr.org/2023/01/09/1147549845/gptzero-ai-chatgpt-edward-tian-plagiarism
[3]https://blog.enterprisedna.co/gptzero/ 作者:人工智能大讲堂 https://www.bilibili.com/read/cv27597949/ 出处:bilibili
这篇关于GPTZero:论文打假神器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)