本文主要是介绍用Python30秒自动获取指定关键词的国际论文?思路清奇的我是这样做的......,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
背景
思路
实现方式
一、找到搜索页面
二、获取论文相关的DOI
三、通过DOI匹配出论文的下载地址进行下载
总结
背景
又到了一年一度的毕业季,各路的同学们都在为了参考论文而发愁,本文我们通过Python来获取指定关键词的论文。
思路
本次我们的目标是获取一部分指定关键词的相关论文,首先我们来整理一下思路。
- 通过百度学术找到论文的相关搜索页;
- 通过详细的搜索页找到论文对应的DOI;
- 通过DOI匹配出论文的下载地址进行下载。
实现方式
一、找到搜索页面
因为我们要借助百度学术来获取论文的DOI的值,因此我们先尝试通过百度学术的搜索页构造出可以匹配关键词的URL地址。
百度学术的搜索页URL如下,我们可以发现在URL中可以通过更改关键词(Key)来组合出不同的关键词URL。

导入模块代码:
# 导入所需模块
import requests
import re
import os
from urllib.request import urlretrieve匹配URL代码:
# 获取URL信息
def get_url(key):url = 'https://xueshu.baidu.com/s?wd=' + key + '&ie=utf-8&tn=SE_baiduxueshu_c1gjeupa&sc_from=&sc_as_para=sc_lib%3A&rsv_sug2=0'return urlget_url('Python')设置请求头:
# 设置请求头
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36','Referer': 'https://googleads.g.doubleclick.net/'
}二、获取论文相关的DOI
这一步我们要找到百度学术中提供的DOI信息并进行获取,从百度学术中可以看到的DOI信息如下所示:
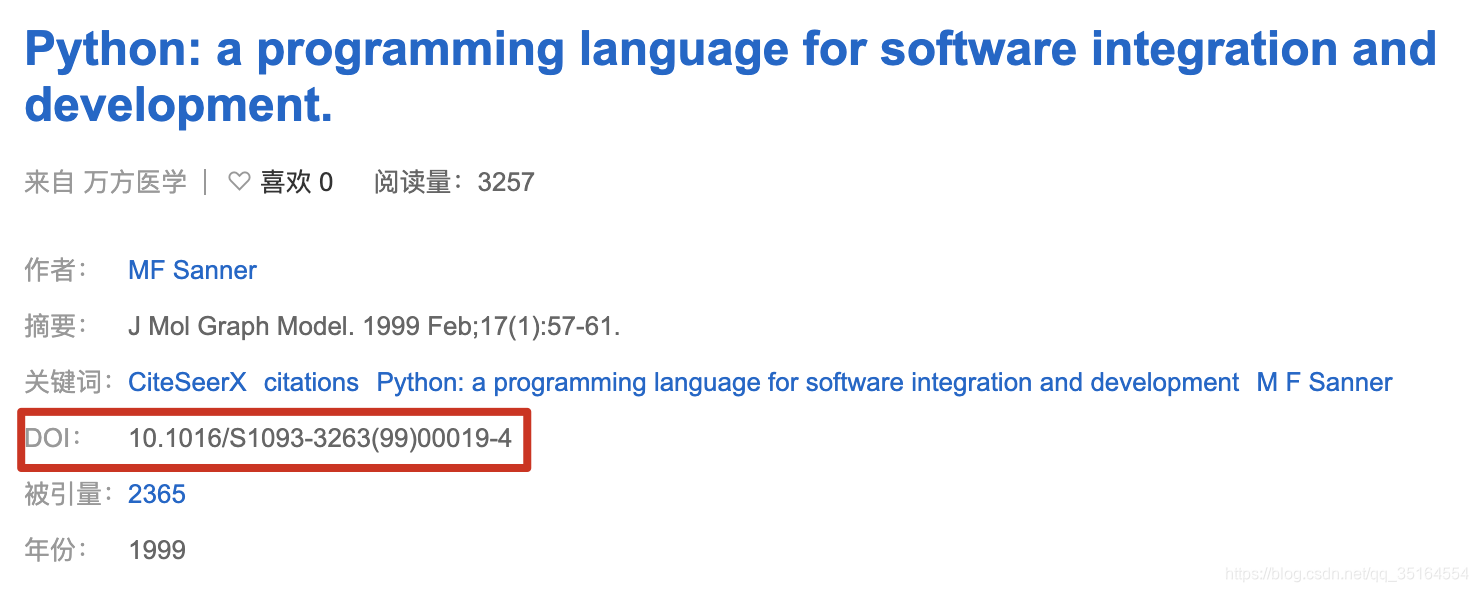
通过Python爬取并解析出DOI的方式如下:
# 获取相关论文的DOI列表
def get_paper_link(headers, key):response = requests.get(url=get_url(key), headers=headers)res1_data = response.text#找论文链接paper_link = re.findall(r'<h3 class=\"t c_font\">\n +\n +<a href=\"(.*)\"',res1_data)doi_list = [] #用一个列表接收论文的DOIfor link in paper_link:paper_link = 'http:' + linkresponse2 = requests.get(url=paper_link, headers=headers)res2_data = response2.text#提取论文的DOItry:paper_doi = re.findall(r'\'doi\'}\">\n +(.*?)\n ', res2_data)if str(10) in paper_doi[0]:doi_list.append(paper_doi)except:passreturn doi_lista = get_paper_link(headers,'apple')三、通过DOI匹配出论文的下载地址进行下载

这一步也是最“神奇”的一步,我们获取到DOI信息之后,可以从网址https://sci-hub.tf/中查找并下载论文,但是通过Python访问网站的时候会发现该网站加入了cloudflare保护(PS:之前没有保护,按照之前的方式教给很多人爬论文后突然加了这个盾,不确定是不是我的功劳。)
破盾
有了思路之后,下一步就是破盾了,博主尝试过多种破盾方式均未能成功,甚至联系了专门开发破解Cloudflare保护的Python模块cloudflare-scrape的开发者,得到的回复就是:项目不能使用了!

最后的最后,我发现该网页中上传的文件都是PDF文件,我们只需要构造出pdf文件的url直接下载就无需登陆网站即可成功下载了(往往复杂的事情简单起来都是很可怕的)。最后构造PDF下载链接代码如下:
#构建sci-hub下载链接
def doi_download(headers, key):doi_list = get_paper_link(headers, key)lst = []for i in doi_list:lst.append(list(i[0]))for i in lst:for j in range(8, len(i)):if i[j] == '/':i[j] = '%252F'elif i[j] == '(':i[j] = '%2528'elif i[j] == ')':i[j] = '%2529'else:i[j] = i[j].lower()for i in range(len(lst)):lst[i] = ''.join(lst[i])for doi in lst:down_link = 'https://sci.bban.top/pdf/' + doi + '.pdf'print(down_link)file_name = doi.split('/')[-1] + '.pdf'try:with open(file_name, 'wb') as f:r = requests.get(url=down_link, headers=headers)f.write(r.content)print('下载完毕:' + file_name)except:print("该文章为空")pass下载模块:
# 检索及下载
key = input("请输入您想要下载论文的关键词(英文):")
doi_download(headers, key)运行结果:
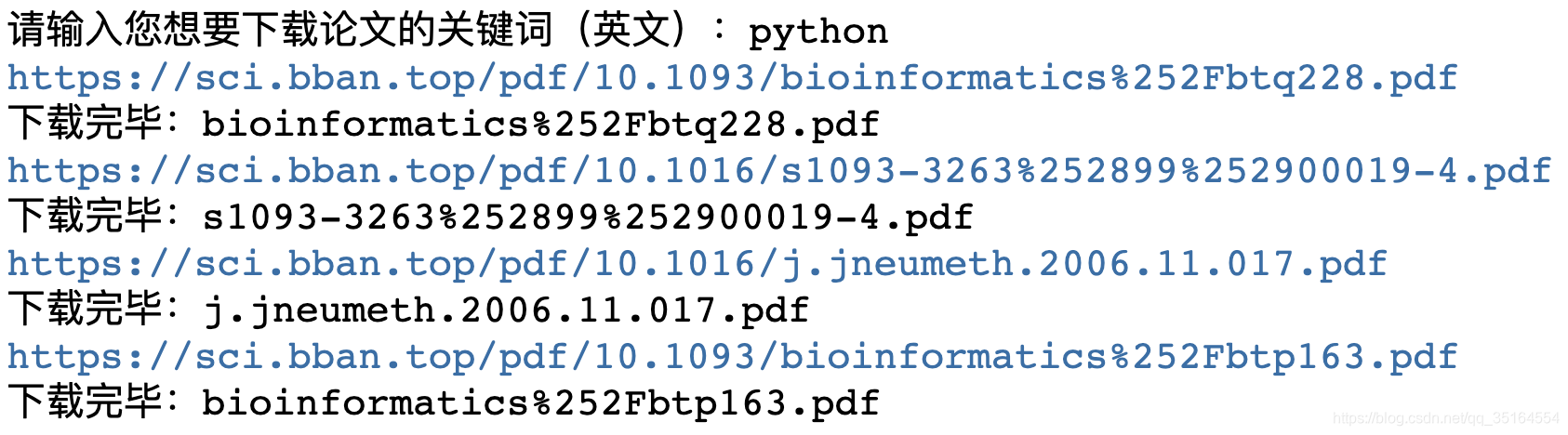
总结
这里只是做一个简单的尝试用于学习交流,如果想要一次性爬取大量的论文修改百度学术代码块的DOI自动获取即可。
这篇关于用Python30秒自动获取指定关键词的国际论文?思路清奇的我是这样做的......的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




