本文主要是介绍Task04:Python操作PDF,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python操作PDF
- 准备
- 批量拆分
- 批量合并
- 提取文字内容
- 提取表格内容
- 提取图片内容
- 转换为图片
准备
首先,安装PyPDF2、pdfplumber、PyMuPDF和pdf2image模块
pip install PyPDF2 pdfplumber PyMuPDF pdf2image
接着找到utils.py 文件,定位到第 238 行原文,如果你使用的是 anaconda,对应的文件路径应该为:anaconda\Lib\site-packages\PyPDF2\utils.py
安装 poppler for Windows,安装链接是:http://blog.alivate.com.au/poppler-windows/
另外,还需要添加环境变量, 将 bin 文件夹的路径添加到环境变量 PATH 中
原文中是这样的:
r = s.encode('latin-1')if len(s) < 2:bc[s] = rreturn r
修改为:
try:r = s.encode('latin-1')if len(s) < 2:bc[s] = rreturn r
except Exception as e:r = s.encode('utf-8')if len(s) < 2:bc[s] = rreturn r
批量拆分
def split_pdf(filename, filepath, save_dirpath, step=5):"""拆分PDF为多个小的PDF文件,@param filename:文件名@param filepath:文件路径@param save_dirpath:保存小的PDF的文件路径@param step: 每step间隔的页面生成一个文件,例如step=5,表示0-4页、5-9页...为一个文件@return:"""if not os.path.exists(save_dirpath):os.mkdir(save_dirpath)pdf_reader = PdfFileReader(filepath)# 读取每一页的数据pages = pdf_reader.getNumPages()for page in range(0, pages, step):pdf_writer = PdfFileWriter()# 拆分pdf,每 step 页的拆分为一个文件for index in range(page, page+step):if index < pages:pdf_writer.addPage(pdf_reader.getPage(index))# 保存拆分后的小文件save_path = os.path.join(save_dirpath, filename+str(int(page/step)+1)+'.pdf')print(save_path)with open(save_path, "wb") as out:pdf_writer.write(out)print("文件已成功拆分,保存路径为:"+save_dirpath)
import os
from PyPDF2 import PdfFileWriter,PdfFileReader
import pdfplumberfilename = '易方达中小盘混合型证券投资基金2020年中期报告'
filepath = 'D:\\组团学习\\易方达中小盘混合型证券投资基金2020年中期报告.pdf'
save_dirpath = 'D:\\组团学习\\task04_out'
split_pdf(filename, filepath, save_dirpath)

批量合并
def concat_pdf(filename, read_dirpath, save_filepath):"""合并多个PDF文件@param filename:文件名@param read_dirpath:要合并的PDF目录@param save_filepath:合并后的PDF文件路径@return:"""pdf_writer = PdfFileWriter()# 对文件名进行排序list_filename = os.listdir(read_dirpath)list_filename.sort(key=lambda x: int(x[:-4].replace(filename, "")))for filename in list_filename:print(filename)filepath = os.path.join(read_dirpath, filename)# 读取文件并获取文件的页数pdf_reader = PdfFileReader(filepath)pages = pdf_reader.getNumPages()# 逐页添加for page in range(pages):pdf_writer.addPage(pdf_reader.getPage(page))# 保存合并后的文件with open(save_filepath, "wb") as out:pdf_writer.write(out)print("文件已成功合并,保存路径为:"+save_filepath)
filename = '易方达中小盘混合型证券投资基金2020年中期报告'
read_dirpath = 'D:\\组团学习\\task04_out'
save_filepath = 'D:\\组团学习\\task04_out1.pdf'concat_pdf(filename, read_dirpath, save_filepath)

提取文字内容
def extract_text_info(filepath):"""提取PDF中的文字@param filepath:文件路径@return:"""with pdfplumber.open(filepath) as pdf:# 获取第2页数据page = pdf.pages[1]print(page.extract_text())
filepath = 'D:\\组团学习\\task04_out1.pdf'extract_text_info(filepath)

而如果想要提取所有页的文字,只需要改成:
with pdfplumber.open(filepath) as pdf:# 获取全部数据for page in pdf.pagesprint(page.extract_text())
提取表格内容
def extract_table_info(filepath):"""提取PDF中的图表数据@param filepath:@return:"""with pdfplumber.open(filepath) as pdf:# 获取第18页数据page = pdf.pages[17]# 如果一页有一个表格,设置表格的第一行为表头,其余为数据table_info = page.extract_table()df_table = pd.DataFrame(table_info[1:], columns=table_info[0])df_table.to_csv('D:\\组团学习\\dmeo.csv', index=False, encoding='gbk')
import pandas as pdfilepath = 'D:\\组团学习\\task04_out1.pdf'extract_table_info(filepath)
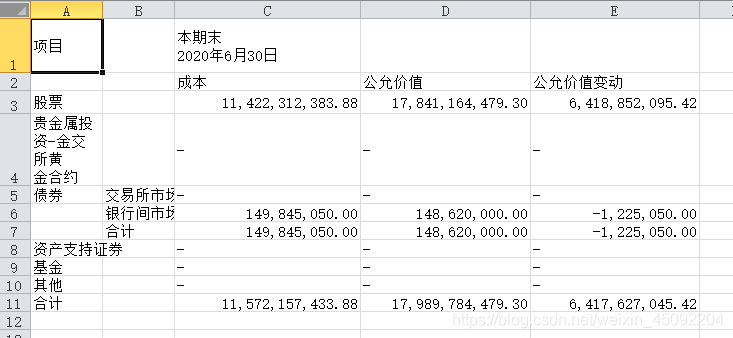
而如果想要提取该页的每一个表格数据,对应的将 extract_table 函数 改成 extract_tables 即可
# 如果一页有多个表格,对应的数据是一个三维数组
tables_info = page.extract_tables()
for index in range(len(tables_info)):# 设置表格的第一行为表头,其余为数据df_table = pd.DataFrame(tables_info[index][1:], columns=tables_info[index][0])print(df_table)# df_table.to_csv('D:\\组团学习\\dmeo.csv', index=False, encoding='gbk')
提取图片内容
def extract_picture_info(filepath,pic_dirpath):if not os.path.exists(pic_dirpath):os.makedirs(pic_dirpath)# 使用正则表达式来查找图片check_XObject = r"/Type(?= */XObject)"check_Image = r"/Subtype(?= */Image)"img_count = 0"""1. 打开pdf,打印相关信息"""pdf_info = fitz.open(filepath)# 1.16.8版本用法 xref_len = doc._getXrefLength()# 最新版本写法xref_len = pdf_info.xref_length()# 打印PDF的信息print("文件名:{}, 页数: {}, 对象: {}".format(filepath, len(pdf_info), xref_len-1))"""2. 遍历PDF中的对象,遇到是图像才进行下一步,不然就continue"""for index in range(1, xref_len):# 1.16.8版本用法 text = doc._getXrefString(index)# 最新版本text = pdf_info.xref_object(index)is_XObject = re.search(check_XObject, text)is_Image = re.search(check_Image, text)# 如果不是对象也不是图片,则不操作if is_XObject or is_Image:img_count += 1# 根据索引生成图像pix = fitz.Pixmap(pdf_info, index)pic_filepath = os.path.join(pic_dirpath, 'img_' + str(img_count) + '.png')"""pix.size 可以反映像素多少,简单的色素块该值较低,可以通过设置一个阈值过滤。以阈值 10000 为例过滤"""# if pix.size < 10000:# continue"""三、 将图像存为png格式"""if pix.n >= 5:# 先转换CMYKpix = fitz.Pixmap(fitz.csRGB, pix)# 存为PNGpix.writePNG(pic_filepath)
import re
import fitzfilepath = 'D:\\组团学习\\task04_out1.pdf'
pic_dirpath = 'D:\\组团学习\\task04_out2'extract_picture_info(filepath,pic_dirpath)
转换为图片
def convert_to_picture(filepath, pic_dirpath):if not os.path.exists(pic_dirpath):os.makedirs(pic_dirpath)images = convert_from_bytes(open(filepath, 'rb').read())
# images = convert_from_path(filepath, dpi=200)for image in images:# 保存图片pic_filepath = os.path.join(pic_dirpath, 'img_'+str(images.index(image))+'.png')image.save(pic_filepath, 'PNG')
from pdf2image import convert_from_bytesfilepath = 'D:\\组团学习\\task04_out1.pdf'
pic_dirpath = 'D:\\组团学习\\task04_out3'convert_to_picture(filepath, pic_dirpath)
这篇关于Task04:Python操作PDF的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




