本文主要是介绍百度是他更懂中文,我看是骗人的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
百度宣称他更懂中文,还做了一系列广告来宣称这个理论。
其实我没有偏颇哪个搜索引擎,只要是哪个能搜到我要的东西,我就用哪个,而且一般两个都用。
但发觉现在百度越来越不理解我的意思了。我搜索的东西一般不会只有一个词,所以我搜索的时候就希望搜索引擎给我什么内容,每每这个时候,Google大概能理解我90%的意思,但百度只能60%,因为他只搜索其中一个关键词和其它关键词的相关信息,而不是每个词的组合信息。
例如 我搜索 “国有建设用地使用权出让合同 合同补充条款”,我希望结果是 "合同补充条款",Google能理解,百度却不是.

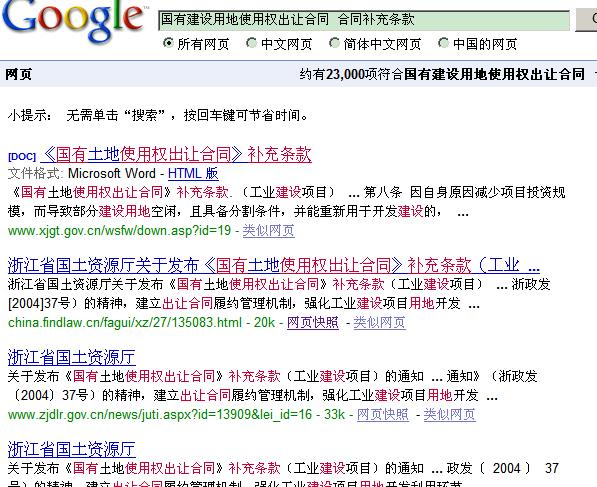
当然还有许多其它例子,我只是例举其一而已。现在用百度就是感觉他的快照不错,速度很快,而Google有时会受到我们组织的关怀一下。。
这篇关于百度是他更懂中文,我看是骗人的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!