本文主要是介绍机器学习笔记:RNN值Teacher Forcing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 基本介绍
- Teacher forcing是一种在训练循环神经网络(RNN)时使用的技术,尤其是在序列生成任务中,如机器翻译、文本生成或语音合成。
- 这种方法的目的是更有效地训练网络预测下一个输出,给定一系列先前的观察结果。
1.1 标准RNN训练过程的问题
- 当训练一个用于序列生成的RNN时,通常会让网络预测序列中的下一个元素。(这种模式又被称为free-running mode / autoregressive mode)
- 在标准的训练过程中,网络的预测会被送回作为下一个时间步骤的输入。
- 但是,在初始阶段,由于网络的参数还没有很好的调整,这些预测可能会相当不准确。
- 这种不准确性可以在网络中累积,并可能导致训练过程变得低效。
- (某一个单词预测错了,后面会跟着错,导致模型很难收敛)
1.2 Teacher Forcing的工作原理
- 为了克服这个问题,teacher forcing在训练期间不使用模型自己的预测作为下一步的输入,而是使用真实的输出序列的当前元素。
- 换句话说,在训练时刻t,模型预测时间t的输出后,不是将这个预测值用作时间t+1的输入,模型而是使用真实的数据,即目标序列在时间t+1的真实值。
- 这样,即使前一个预测不准确,网络也可以在准确的数据指导下继续学习。
2 优点
- 快速收敛: 由于网络接收到准确的信息,它通常可以更快地学习正确的参数。
- 稳定训练: 防止错误的累积和传播,使得整个训练过程更加稳定
- 并行保证:保证 Transformer 模型能够在训练过程中完全并行计算所有token
3 缺点
- 露珠效应(Exposure Bias): 在真实应用(推理阶段)中,网络只能依赖于它自己的预测来生成序列,这可能导致在训练时没有遇到的错误。
- 不一致的学习信号: 训练和推理时的行为不一致,可能会导致推理时性能下降。
4 teacher forcing ratio
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks 2015
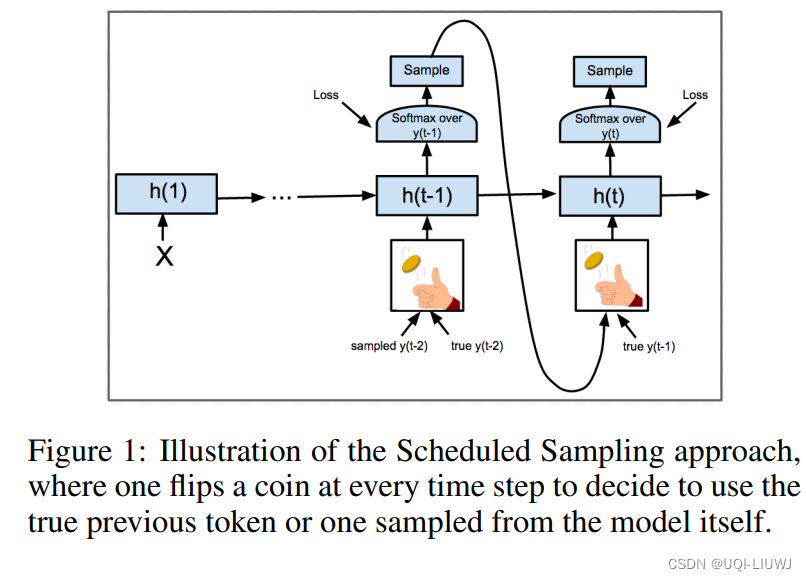
- 模型在训练过程中的每一个steps,有 p的概率选择使用 teachering-forcing,有 1−p 的概率选择使用 Autoregressive。
- 模型在训练前期,p应该尽可能的大,这样能够加速收敛;而在快要结束训练的时候, p 尽可能的小,让模型在 Autoregressive 的方案中尽可能的修复自身生成的错误。
-
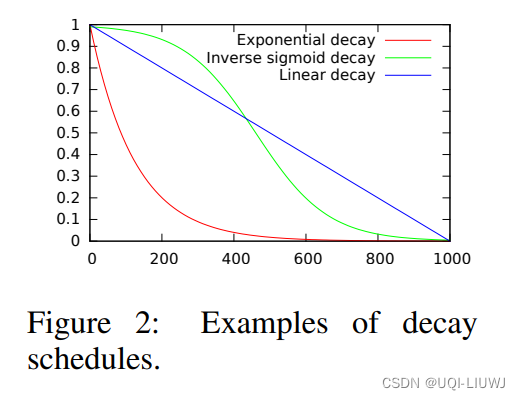
p可以随着训练的Epoch 进行衰减:Exponential Decay, Inverse Sigmoid decay 和 Linear decay
-
- 上面的这个概率 p ,是针对一个token而言的,而不是针对整句话。
- 也就是说在解码过程中,每个token的生成,都要进行着这么一次概率的选择。
- 论文中指出,如果是整句话进行概率选择的话,效果会比较差
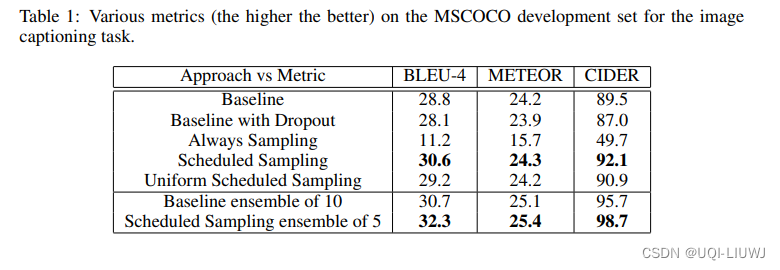
- Always Sampling:相当于在训练过程只使用Autoregressive 方案(每次使用上一步的预测单词),可以发现模型效果非常差,收敛有问题。
- Uniform Scheduled Sampling:每次都有0.5的概率选择 Teacher-Forcing,0.5的概率选择Autoregressive,效果也比 Scheduled-Sampling 要差
这篇关于机器学习笔记:RNN值Teacher Forcing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








