本文主要是介绍Codeforces Round #465 (Div. 2) D. Fafa and Ancient Alphabet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目:
Ancient Egyptians are known to have used a large set of symbols 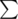 to write on the walls of the temples. Fafa and Fifa went to one of the temples and found two non-empty words S1 and S2 of equal lengths on the wall of temple written one below the other. Since this temple is very ancient, some symbols from the words were erased. The symbols in the set have equal probability for being in the position of any erased symbol.
to write on the walls of the temples. Fafa and Fifa went to one of the temples and found two non-empty words S1 and S2 of equal lengths on the wall of temple written one below the other. Since this temple is very ancient, some symbols from the words were erased. The symbols in the set have equal probability for being in the position of any erased symbol.
Fifa challenged Fafa to calculate the probability that S1 is lexicographically greater than S2. Can you help Fafa with this task?
You know that 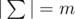 , i. e. there were m distinct characters in Egyptians' alphabet, in this problem these characters are denoted by integers from 1 to m in alphabet order. A word x is lexicographically greater than a word y of the same length, if the words are same up to some position, and then the word x has a larger character, than the word y.
, i. e. there were m distinct characters in Egyptians' alphabet, in this problem these characters are denoted by integers from 1 to m in alphabet order. A word x is lexicographically greater than a word y of the same length, if the words are same up to some position, and then the word x has a larger character, than the word y.
We can prove that the probability equals to some fraction 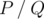 , where P and Q are coprime integers, and
, where P and Q are coprime integers, and 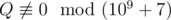 . Print as the answer the value
. Print as the answer the value 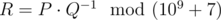 , i. e. such a non-negative integer less than 109 + 7, such that
, i. e. such a non-negative integer less than 109 + 7, such that 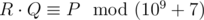 , where
, where 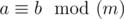 means that a and b give the same remainders when divided by m.
means that a and b give the same remainders when divided by m.
The first line contains two integers n and m (1 ≤ n, m ≤ 105) — the length of each of the two words and the size of the alphabet , respectively.
The second line contains n integers a1, a2, ..., an (0 ≤ ai ≤ m) — the symbols of S1. If ai = 0, then the symbol at position i was erased.
The third line contains n integers representing S2 with the same format as S1.
Print the value 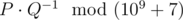 , where P and Q are coprime and is the answer to the problem.
, where P and Q are coprime and is the answer to the problem.
1 2 0 1
500000004
1 2 1 0
0
7 26 0 15 12 9 13 0 14 11 1 0 13 15 12 0
230769233
In the first sample, the first word can be converted into (1) or (2). The second option is the only one that will make it lexicographically larger than the second word. So, the answer to the problem will be 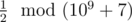 , that is 500000004, because
, that is 500000004, because 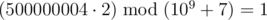 .
.
In the second example, there is no replacement for the zero in the second word that will make the first one lexicographically larger. So, the answer to the problem is 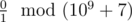 , that is 0.
, that is 0.
题目分析:
n为a串和b串的长度,m为set的大小,a串和b串中为0的位置可以填1-m中的任意一个数,让你求a串字典序大于b串的概率p/q(mod 1000000007)。
为了这道题,调了2个小时的bug竟然发现是数组大小没开够……
p/q好求,就是简单的遍历加上计算,但是求逆元的话我给忘了,下面总结一下分数求逆元。
首先说一下逆元。
若a*x%mode=1,则x是a的逆元。
通过式子,我们可以联想到扩展欧几里得:a*x+mode*y=1,若式子有解,要求gcd(a,mode)=1。
扩展欧几里得算法如下(是辗转相除法的扩展):
void e_gcd(ll a,ll b,ll &x,ll &y)
{
if(b==0)
{
x=1;
y=0;
return ;
}
else
{
e_gcd(b,a%b,x,y);
ll tmp=x;
x=y;
y=tmp-a/b*y;
return ;
}
}
最后求出来的结果可能为负,要加上:x=(x%mode+mode)%mode;
最后一个要注意的点,也是我错的点,就是注意a,b串中0位置的个数最大可能为2*maxn,而不是maxn
附上代码:
#include<stdio.h>
#include<string.h>
#include<algorithm>
#include<iostream>
using namespace std;
typedef long long ll;
const int maxn=1e5+10;
ll string_a[maxn],string_b[maxn];
const long long mode=1e9+7;
ll r[maxn];
ll pow[2*maxn];
void init(long long m)
{
pow[0]=1;
for(long long i=1;i<2*maxn;i++)
pow[i]=pow[i-1]*m%mode;
return;
}
void e_gcd(ll a,ll b,ll &x,ll &y)
{
if(b==0)
{
x=1;
y=0;
return ;
}
else
{
e_gcd(b,a%b,x,y);
ll tmp=x;
x=y;
y=tmp-a/b*y;
return ;
}
}
int main()
{
ll n,m,cnt=0;
scanf("%lld%lld",&n,&m);
for(int i=0;i<n;i++)
scanf("%lld",&string_a[i]);
for(int i=0;i<n;i++)
scanf("%lld",&string_b[i]);
memset(r,0,sizeof(r));
r[n-1]=0;
for(int i=n-2;i>=0;i--)
{
if(string_a[i+1]==0)
r[i]++;
if(string_b[i+1]==0)
r[i]++;
r[i]+=r[i+1];
}
cnt=r[0];
if(string_a[0]==0)
cnt++;
if(string_b[0]==0)
cnt++;
init(m);
ll s_equal=1,ans=0;
for(int i=0;i<n;i++)
{
if(string_a[i]==0)
{
if(string_b[i]==0)
{
ans+=(((s_equal*(m*(m-1)/2%mode)%mode)*pow[r[i]])%mode);
ans%=mode;
s_equal*=m;
s_equal%=mode;
}
else
{
ans+=(((s_equal*(max(m-string_b[i],(ll)0))%mode)*pow[r[i]])%mode);
ans%=mode;
}
}
else
{
if(string_b[i]==0)
{
ans+=(((s_equal*(min(string_a[i]-1,m))%mode)*pow[r[i]])%mode);
ans%=mode;
}
else
{
if(string_a[i]==string_b[i])
continue;
else if(string_a[i]>string_b[i])
{
ans+=(s_equal*pow[r[i]]%mode);
ans%=mode;
break;
}
else
break;
}
}
}
long long q=pow[cnt];
long long x,y;//x为q的逆元
e_gcd(q,mode,x,y);
x=(x%mode+mode)%mode;
ans=ans*x%mode;
cout<<ans<<endl;
}
//错误估计了数组的大小
这篇关于Codeforces Round #465 (Div. 2) D. Fafa and Ancient Alphabet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






