本文主要是介绍网络数据传输流程系列(3)—物理层“从传输块到码字”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:这是4G网络数据传输流程系列的第三课,上一课讲了资源调度,备好粮草,这一课我们集结兵马,趟一趟物理层处理流程。先讲从传输块TB到码字(CW,Code Word),重点是信道编码和速率匹配。有请小编Bob。
物理层处理的起点是MAC层传下来的TB,终点是生成基带OFDM信号。然后上变频或下变频将基带OFDM信号变成射频信号,通过天线发射出去。与资源调度一样,物理层处理也分上行和下行,二者处理流程类似,仍然以下行为例介绍(还记得不?下行是指Bob从基站下载小视频~,关注公众号“wisdom365”了解更多)。
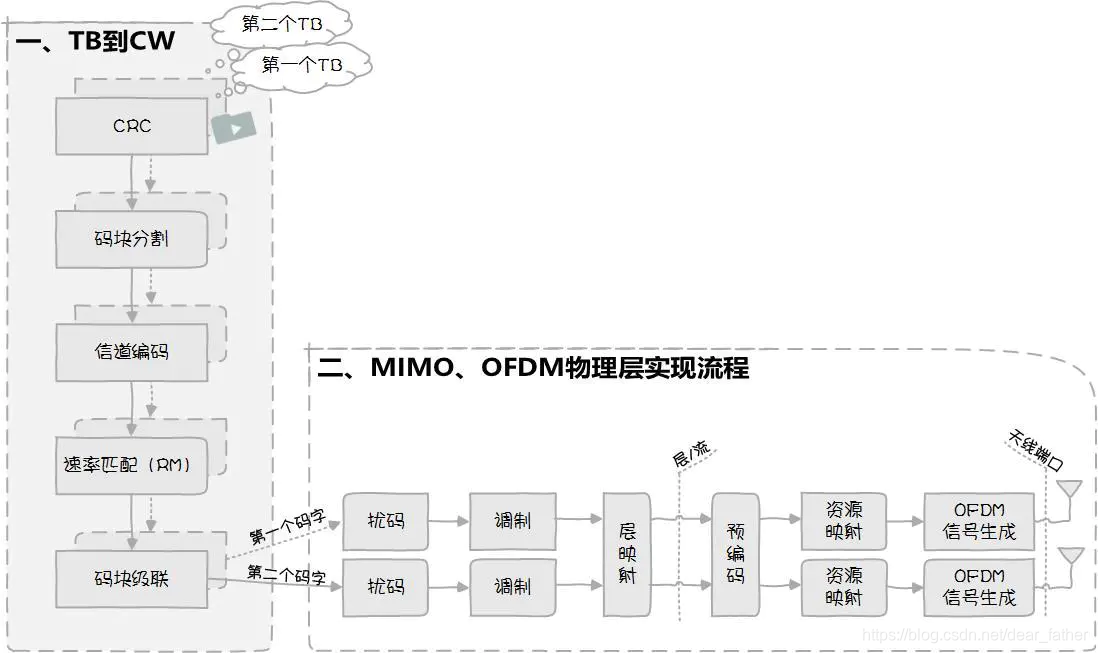
上行和下行处理流程区别在哪?有两点:
(1)下行可以同时处理两个TB,上行只能处理1个TB(注:R10版本上行最多可支持四流传输,此时上行也能同时处理2个TB,但基本未商用);
(2)下行采用OFDM方式,上行为避免峰均比过高采用SC-OFDM,因此,上行处理在层映射和预编码之间增加一步:变换预编码,以达到上行单载波目的。
由于物理层处理步骤实在是太多了,小编只能分成两篇文章来讲,第一篇讲述第1步第5步(上图中标灰的框),第二篇讲述第6步第11步。
物理层处理–从TB到码字
下行能同时处理两个TB,两个TB的处理流程完全相同,因此小编就以一个TB处理流程为栗子,力求说清楚每一步干什么?从哪来?到哪去? 怎么做?
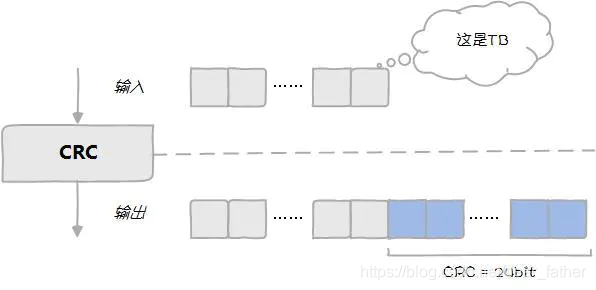
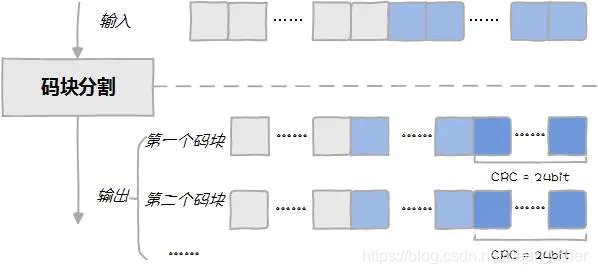
第二步:码块分割。把大码块分割成小码块,每个小码块继续添加24bit的CRC校验。
A:每次码块都要分割吗?A:如果是,为什么要分割呢?A:如果不是,什么样的码块要分割呢?B:不是所有码块都要分割,只有那些很大的码块才要分割。A:多大?B:据《圣经》3GPP TS 36.212记载,大于6144bit的码块才要分割。A:为什么是6144bit?6666不行吗?多吉利B:。。。定义6144是因为下一步信道编码中能处理的最大数据块就是6144bit。
假设有1个很大的TB传下来,数据块后附加24bit CRC校验,发现大于6144bit,则再次分割(假设分成两块),每块后再附加24bit CRC校验。
第三步:信道编码。地球人都知道信道编码的目的是保证信息传输不出错,提高可靠性,否则Alice传过去的小视频就都是马赛克了~~。
怎么实施信道编码呢?简单讲, 发送端在信息bit后附加校验bit,使信息bit和校验bit有一定的数学关系,称为编码;接收端收到后猜传的是1还是0,称为译码,当然这里的猜可不是拍大腿猜,是通过算法有理有据的猜。按照校验bit和信息bit之间的关系可以把信道编码分为线性分组码和卷积码,区别在于,线性分组码的校验bit只和它们要保护的当前传输的信息bit有关系,而卷积码的校验bit除和当前传输的信息bit有关外,还和前一时刻传输的信息bit有关(好绕啊。。),第一步的CRC就可以认为是线性分组码,3G WCDMA采用的就是卷积码。
在4G中,采用的信道编码是著名的Tur…bo…码, 码率为1/3。这一步里,针对第二步码块分割后得到的每个码块独立进行信道编码,输出三行数据,分别是:系统比特流,第一校验比特流,第二校验比特流。
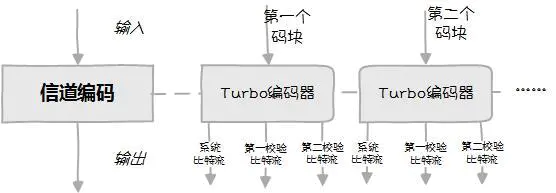
A:话说Turbo不是涡轮发动机的意思吗?Turbo码到底是什么?
B:Turbo码是C. Berrou与A. Glavieux在1993 年瑞士日内瓦举行的IEEE ICC国际通信学会上首次提出的一种级联码,基本原理是编码器通过交织器把两个分量编码器进行并行级联,两个分量编码器分别输出对应校验bit;译码器在两个分量编码器之间进行迭代译码,分量译码器之间传递去掉正反馈的外信息,整个译码过程类似涡轮工作,所以就把这个编码方法称为涡轮码,错了,是Turbo码。A:说人话。。。B:Turbo码编码器其实就是把两个卷积码编码器并行起来,中间加一个交织器,也叫做并行级联卷积码。因为有两个卷积码编码器,每个编码器都会输出校验bit,所以Turbo码输出两个校验bit流,称为第一校验bit流和第二校验bit流,加上原始数据,共输出三行数据。一图胜千言,看下图。A:然后呢?B:编码器中的这个交织器可是神来之笔,Turbo码有增益全靠有它。在4G网络里,这个交织器最大能处理的数据长度是6144bit,这也是为什么第二步里超过6144bit的码块要被拆了。A:欧,然后呢?B:Turbo译码器是两个串联的卷积码译码器,第一个译码器的输出通过交织器打乱顺序后作为第二个译码器的输入,第二个译码器的输出再送回去作为第一个译码器的输入,循环迭代,直到译码完毕。一图胜千言,看下图。A:为什么这么折腾呢?B:这是Turbo码的核心和显著特征,使用外信息进行一次次迭代译码,如此保证Turbo的高性能。A:举个栗子?B:在Turbo码之前,译码不使用外信息,若要判断一个比特是0还是1,你觉得它像1就是1。如果这时周围的小伙伴告诉你这个比特更像0,这个信息就是外信息,是排除了自身判断由别人得到的信息。使用外信息做判断的时候,就要把周围人的判断和自己的判断进行比较,综合两方面得到最终结果。多听听别人意见总是有好处,集思广益嘛。所以Turbo码使用外信息进行迭代解码这一思路,开启了现代编解码理论的大门。A:恩恩。那码率1/3是什么意思?B:信道编码要在信息bit后附加校验bit,信息bit位数/(信息bit位数+校验bit位数)就是码率。1/3的码率就是说对于1个信息bit,要算出2个校验bit来保护它,这样信道编码后得到的数据总长度就是原来的3倍。
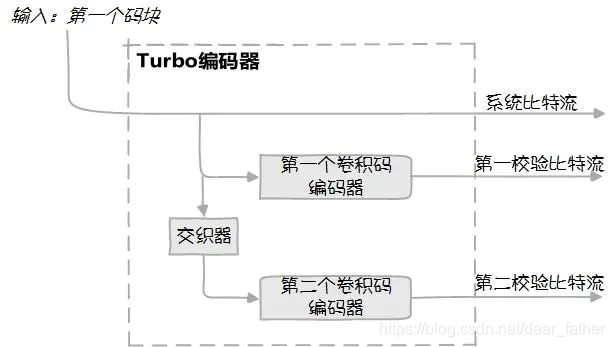

A:好复杂的样子...B:讲了这么多,也是为了纪念Turbo码。2016年10月14日在葡萄牙里斯本,3GPP RAN1确定LDPC码为5G信道编码长码方案,Turbo码结束了在3G、4G时代长达十几年的统治。A:一个时代的落幕,确实让人唏嘘,不过和咱们吃瓜群众有关系吗?B:有啊,话说我曾立志在广袤的大草原中寻找一匹好码,从Turbo到LDPC到polar到喷泉A:套码的汉子你威武雄壮...
第四步,速率匹配。信道编码后的数据最终要通过无线资源传输,但是数据量和传输资源往往不匹配,有时传的数据量多而传输资源不够,有时数据量少而传输资源多,这就需要把这两部分匹配起来,叫做速率匹配,一般有两种方法:(1)打孔,扔掉一些数据bit;(2)重复,复制数据bit充数。
在4G网络,每一个码块信道编码后,Turbo编码器并行输出三行数据,而最终传输的肯定是一行数据流,所以怎么把三行数据再变成一行数据流,首位相接,还是交插组队?无线传输资源不是固定不变的,得到的一行数据流与无线传输资源大小不匹配怎么办?这就是4G网络中速率匹配要解决的问题。
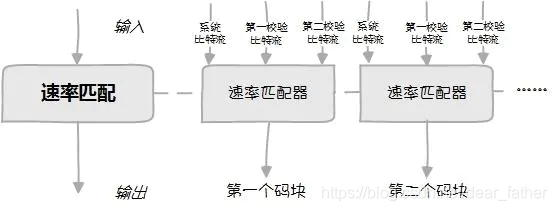
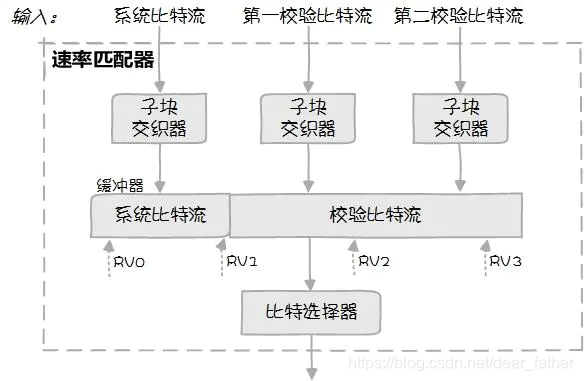
下图是速率匹配器结构图,Turbo信道编码后的三行数据同时输入,分别通过行列交织器后,存在缓冲器中,系统比特流排在缓冲器头部,校验bit流排在尾部。比特选择器在缓冲器中选择一个“起点”,并顺序选出指定大小的一行数据,作为输出。共有四种“起点”选择方式,对应我们常说的4个冗余版本(RV)。
第五步,码块级联。天下大事,合久必分,分久必合。数据处理也一样,第一步中,长度超出6144bit的大码块要分割,这是“分”;这一步,要把分割、信道编码后的码块再首尾相接连起来,这就是“合”。最终仍然得到呈“一字长蛇阵”的数据bit流,形式上和第一步的输入TB是一样的,不过这时数据流改名叫码字(CW,Code Word)。

OK,到这里,小编洋洋洒洒几千字讲完了4G物理层处理中从TB到码字的流程,其中重点是信道编码和速率匹配。下一课Bob小编将介绍4G网络哼哈二将MIMO和OFDM在物理层的实现和处理流程,完成物理层处理的收官之战,敬请期待。
作者:读万卷行万里
链接:https://www.jianshu.com/p/2ae95e278d76
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这篇关于网络数据传输流程系列(3)—物理层“从传输块到码字”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








