本文主要是介绍【Database System Concept 7th】Chapter 24 Advanced Indexing Techniques 读书笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Chapter 24 Advanced Indexing Techniques
- 24.5 Hash Indices
- 24.5.1 Static Hashing
- 24.5.2 Dynamic Hashing
- 24.5.2.1 Data Structure
- 24.5.2.2 Queries and Updates
24.5 Hash Indices
24.5.1 Static Hashing
这一部分就不介绍了,在14.5中已经介绍过了。
24.5.2 Dynamic Hashing
主要介绍下动态散列的一种方案,称为可扩展散列。
24.5.2.1 Data Structure
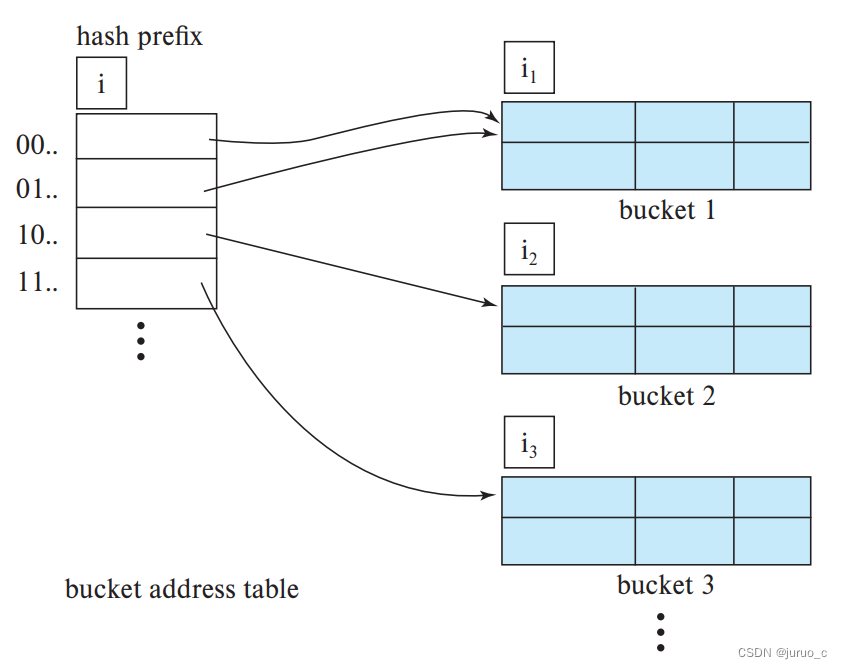
可扩展散列的基本数据结构如下图所示,主要包括两部分:
- bucket address table:桶地址表,类似目录,用于存放桶地址
- bucket:一个一个的桶,用于存放记录
可以注意下图中,桶地址表上方与每个桶的上方都标有一个整数,其中,桶地址表上方的整数 i i i称为全局位深度(grobal depth),每个桶 j j j上方的整数 i j i_j ij称为局部位深度(local depth)。
关于全局位深度 i i i和桶 j j j的局部位深度 i j i_j ij有以下性质:
- 桶地址表中,指向桶 j j j的表项数为 2 i − i j 2^{i-i_j} 2i−ij个
- 存放于桶 j j j中的记录,他们搜索码的哈希值二进制低 i j i_j ij位都一样
这个结构是如何建立出来的、两个位深度分别有什么用处、以及为什么会有以上性质,我们先不管,下一节中会细说,先了解基本概念即可。
24.5.2.2 Queries and Updates
本节主要介绍可扩展散列的记录查询与插入过程,删除过程暂时还没了解,后续补上。
首先是查询过程,当查询包含某个搜索码Key的记录时,首先使用哈希函数 h h h对Key取哈希值 h ( K e y ) h(Key) h(Key),再取出这个哈希值二进制位中的低 i i i位(这里的 i i i表示全局位深度),由桶地址表得到对应的桶地址,从而查询到对应的记录。
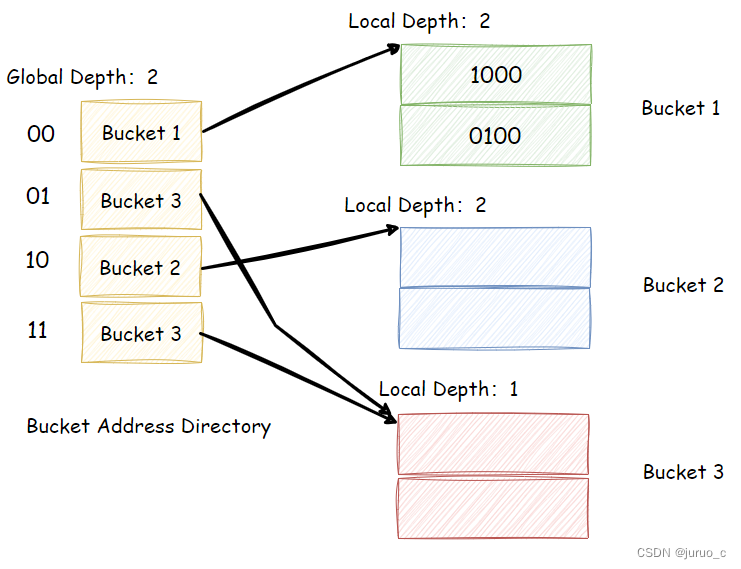
一个具体的例子如下图所示,假设某条记录的搜索码哈希值为0010,由于全局位深度为2,则对应的表项为00,获取到Bucket 1的地址,从而进入bucket 1查找到对应记录。可以看到,Bucket 1中记录的搜索码对应哈希值的低2位都一致。
查询过程相对比较简单,接下来我们来看相对复杂的插入记录过程。当插入一条新的记录时,首先同查询过程一致,根据搜索码找到对应的桶 j j j,然后分为以下情况:
- 若桶 j j j中仍有空间,则直接将记录插入该桶
- 若桶 j j j已满,则需要分裂这个桶并将桶中现有记录加上新纪录重新分配,分为以下两种情况:
- 如果 i = i j i=i_j i=ij,根据上一节的性质可以知道,桶地址表中只有一个表项指向桶 j j j(让我们假设这个表项为 T E j TE_j TEj),此时需要增加桶地址表的规模,使得桶地址表可以容纳由于桶 j j j分裂产生的两个桶指针。具体的做法是,将 i i i加1,这将使得桶地址表的容量翻倍,原来的每个表项都产生出自己的一个副本,新的表项包含和原始表项一样的指针(我们令 T E j TE_j TEj的副本表项为 T E k TE_k TEk,则 T E k TE_k TEk也指向 j j j)。然后,系统会分配一个新的桶 k k k,让新表项副本 T E k TE_k TEk指向 k k k,并将 i j i_j ij和 i k i_k ik都置为 i i i。最后,将 j j j中的所有记录与新记录重新分配,根据记录搜索码哈希值二进制的后 i i i位确定放入桶 j j j中还是放入桶 k k k中。一个具体的例子如下图所示,当在之前的图中插入一条搜索码哈希值二进制为1000的记录时,
Bucket 1将溢出,故将Global Depth增大1,增加一个新的桶Bucket 4,并将记录根据二进制后三位重新散列。 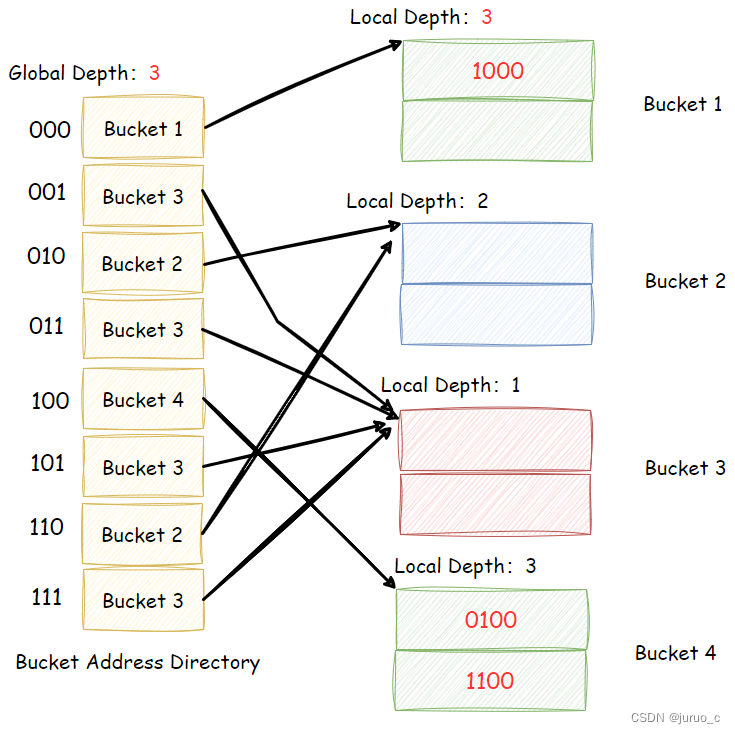
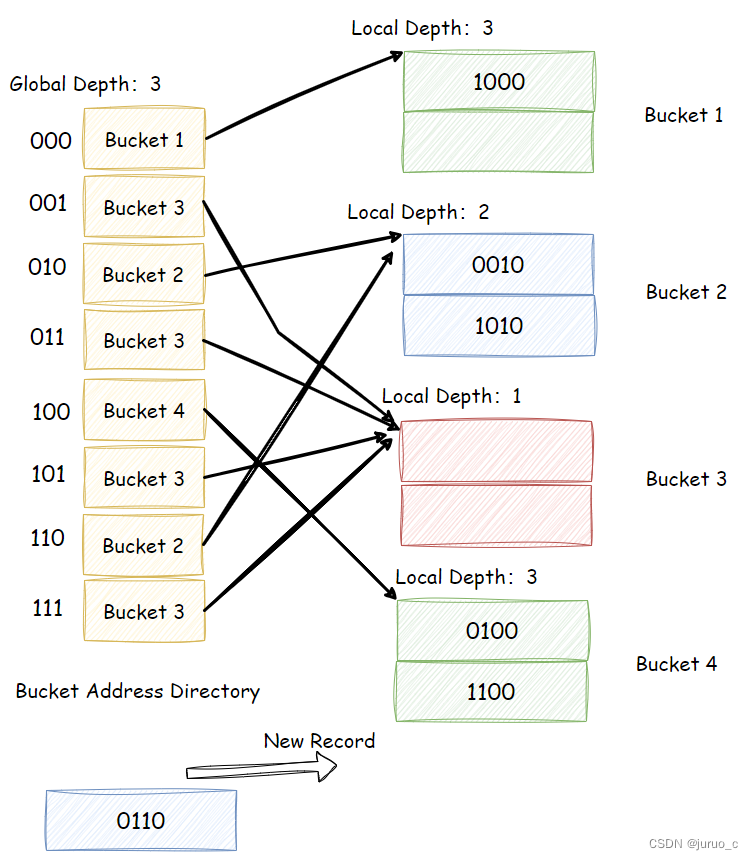
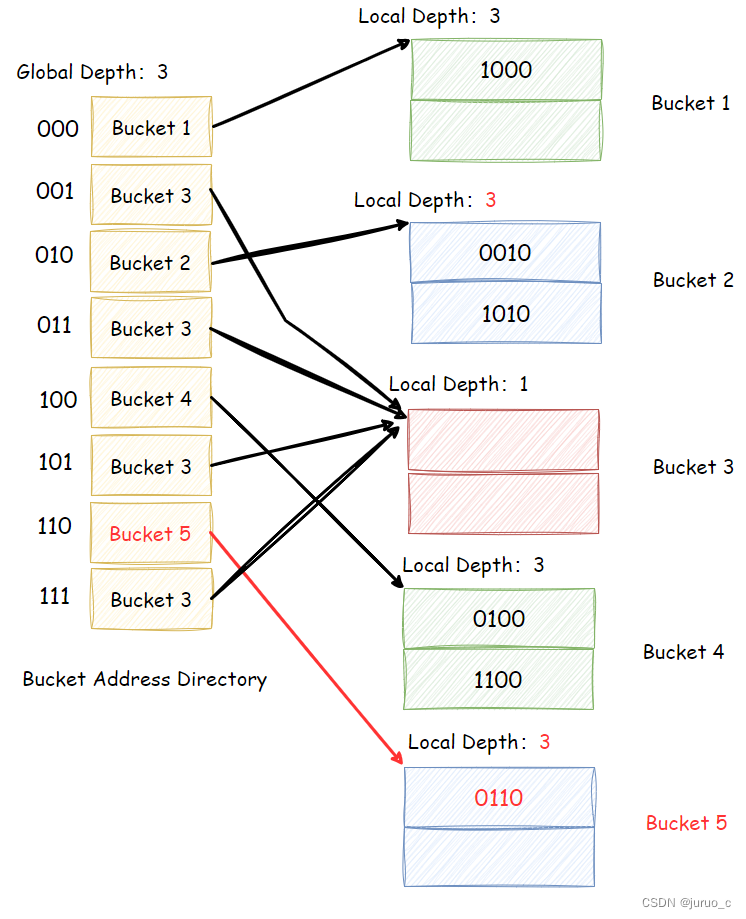
- 如果 i > i j i>i_j i>ij,那么根据上一节中的性质,桶地址表中不止一个表项指向桶 j j j,会有 2 i − i j 2^{i-i_j} 2i−ij个表项指向桶 j j j,此时不需要增加桶地址表的容量,直接分裂桶 j j j即可。具体做法是,系统分配一个新的桶 k k k,将指向 j j j的后 2 i − i j − 1 2^{i-i_j-1} 2i−ij−1个表项修改为指向 k k k,并设置 i j i_j ij与 i k i_k ik为 i j + 1 i_j + 1 ij+1,最后重新散列 j j j中的记录与新纪录。一个具体的例子如下图所示,当向
Bucket 2插入两个记录之后,再插入一个记录,这时Bucket 2溢出;由于Bucket 2的Local Depth小于Global Depth,于是不需增大Global Depth,直接将表项 110 110 110指向的桶修改为新增桶Bucket 5即可,然后重新散列Bucket 2与新纪录。
- 如果 i = i j i=i_j i=ij,根据上一节的性质可以知道,桶地址表中只有一个表项指向桶 j j j(让我们假设这个表项为 T E j TE_j TEj),此时需要增加桶地址表的规模,使得桶地址表可以容纳由于桶 j j j分裂产生的两个桶指针。具体的做法是,将 i i i加1,这将使得桶地址表的容量翻倍,原来的每个表项都产生出自己的一个副本,新的表项包含和原始表项一样的指针(我们令 T E j TE_j TEj的副本表项为 T E k TE_k TEk,则 T E k TE_k TEk也指向 j j j)。然后,系统会分配一个新的桶 k k k,让新表项副本 T E k TE_k TEk指向 k k k,并将 i j i_j ij和 i k i_k ik都置为 i i i。最后,将 j j j中的所有记录与新记录重新分配,根据记录搜索码哈希值二进制的后 i i i位确定放入桶 j j j中还是放入桶 k k k中。一个具体的例子如下图所示,当在之前的图中插入一条搜索码哈希值二进制为1000的记录时,
以上就是基本的查询操作与插入操作的过程,但插入操作并不是很完善。考虑这样一种情况,假设每个桶的容量为 2 2 2,当我们存在3条记录均包含相同的搜索码时,就会造成桶溢出,此时使用溢出桶方式来解决,即串链表形式,在14.5中已经叙述过,这里就不再赘述了。
这篇关于【Database System Concept 7th】Chapter 24 Advanced Indexing Techniques 读书笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




