本文主要是介绍美团Leaf使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。
美团Leaf就是用于生成对应公式的Id的工具。
为什么我们要使用美图Leaf?
UUID
优点:
- 性能非常高:本地生成,没有网络消耗。
缺点:
- 性能非常高:本地生成,没有网络消耗。
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用,不适合添加索引。
雪花算法:依赖机器的时间来通过时间戳生成对应的ID,在机器的本机的时间发生问题时,就可以出现重复的情况。
美团Leaf文档: 美团Leaf文档
美团Leaf的模式
号段模式
号段模式采用的是基于MySQL数据生成id的,它并不是基于MySQL表中的自增长实现的,因为基于MySQL的自增长方案对于数据库的依赖太大了,性能不好,Leaf的号段模式是基于一张表来实现,每次获取一个号段,生成id时从内存中自增长,当号段用完后再去更新数据库表。
原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
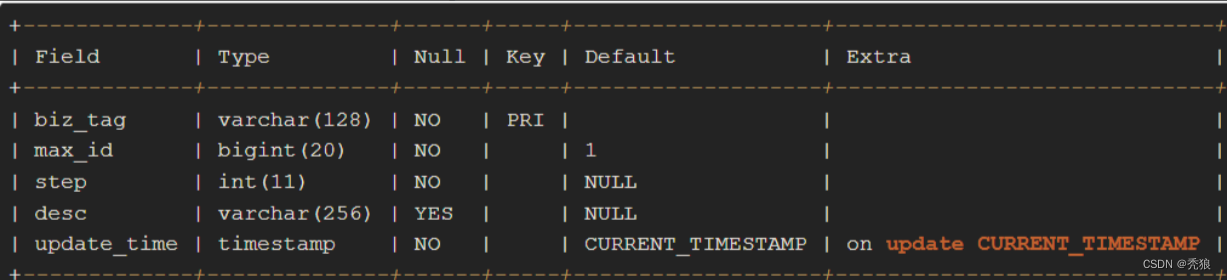
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step。
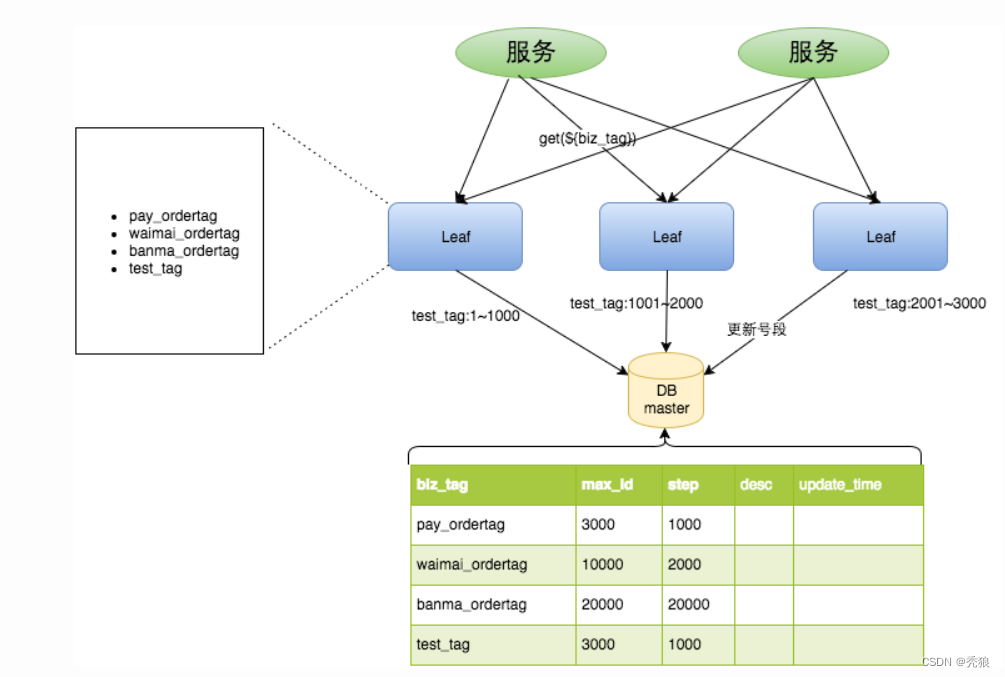
缺点:
- ID号码不够随机,能够泄露发号数量的信息,不太安全。
- TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺。
- DB宕机会造成整个系统不可用。
解决方案:
缺点1的解决方案:在Id的使用上我们还会配合用户的手机进行认证。
缺点2的解决方案:使用双Buffer优化,Leaf 取号段的时机是在号段消耗完的时候进行的。
双buffer会存在两个号段,都用于存储Id,用于减少对DB的访问。会在号段一到达到10%就异步去数据库更新下一个号段(就比如:号段1为1~1000,则在号段1中取号的Id到10%就会更新号段2为1001~2000,获取在号段2取号的Id到达10%就会将号段1的号段修改为 2001~3000),即使宕机了,还能用10~20分钟。
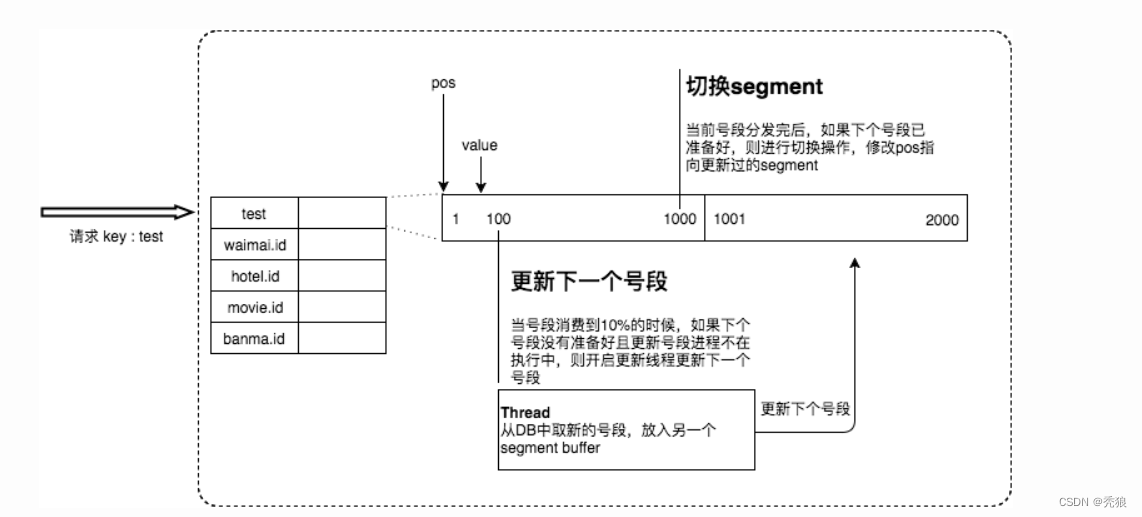
缺点3的解决方案:搭建mysql集群。
美团Leaf的服务部署
通过docker获取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/itheima/meituan-leaf:1.0.1运行docker 容器
docker run \
-d \
-v /itcast/meituan-leaf/leaf.properties:/app/conf/leaf.properties \
--name meituan-leaf \
-p 28838:8080 \
--restart=always \
registry.cn-hangzhou.aliyuncs.com/itheima/meituan-leaf:1.0.1编写application.yml配置文件
#美团leaf对应的数据库
leaf.name=leaf-server
leaf.segment.enable=true
leaf.jdbc.url=jdbc:mysql://192.168.150.101:3306/sl_leaf?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true&useSSL=false
leaf.jdbc.username=root
leaf.jdbc.password=123#不开启Leaf-snowflake方案
leaf.snowflake.enable=false#指定美团leaf服务地址
sl.id.leaf = http://192.168.150.101:28838创建sl_leaf数据库的sql语句
CREATE TABLE `leaf_alloc` (`biz_tag` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '',`max_id` bigint NOT NULL DEFAULT '1',`step` int NOT NULL,`description` varchar(256) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`biz_tag`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;-- 插入运单号生成规划数据
INSERT INTO `leaf_alloc` (`biz_tag`, `max_id`, `step`, `description`, `update_time`) VALUES ('transport_order', 1000000000001, 100, 'Test leaf Segment Mode Get Id', '2022-07-07 11:32:16');
封装IdService服务
package com.sl.transport.common.service;import cn.hutool.core.util.StrUtil;
import cn.hutool.http.HttpRequest;
import cn.hutool.http.HttpResponse;
import com.sl.transport.common.enums.IdEnum;
import com.sl.transport.common.exception.SLException;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;/*** id服务,用于生成自定义的id*/
@Service
public class IdService {@Value("${sl.id.leaf:}")private String leafUrl;/*** 生成自定义id** @param idEnum id配置* @return id值*/public String getId(IdEnum idEnum) {String idStr = this.doGet(idEnum);return idEnum.getPrefix() + idStr;}private String doGet(IdEnum idEnum) {if (StrUtil.isEmpty(this.leafUrl)) {throw new SLException("生成id,sl.id.leaf配置不能为空.");}//访问leaf服务获取idString url = StrUtil.format("{}/api/{}/get/{}", this.leafUrl, idEnum.getType(), idEnum.getBiz());//设置超时时间为10sHttpResponse httpResponse = HttpRequest.get(url).setReadTimeout(10000).execute();if (httpResponse.isOk()) {return httpResponse.body();}throw new SLException(StrUtil.format("访问leaf服务出错,leafUrl = {}, idEnum = {}", this.leafUrl, idEnum));}}
封装IdEnum枚举类
package com.sl.transport.common.enums;public enum IdEnum implements BaseEnum {
//这里就一个枚举,如果需要其他规则,则继续添加新的枚举即可TRANSPORT_ORDER(1, "运单号", "transport_order", "segment", "SL");private Integer code;private String value;private String biz; //业务名称private String type; //类型:自增长(segment),雪花id(snowflake)private String prefix;//id前缀IdEnum(Integer code, String value, String biz, String type, String prefix) {this.code = code;this.value = value;this.biz = biz;this.type = type;this.prefix = prefix;}@Overridepublic Integer getCode() {return this.code;}@Overridepublic String getValue() {return this.value;}public String getBiz() {return biz;}public String getType() {return type;}public String getPrefix() {return prefix;}@Overridepublic String toString() {final StringBuffer sb = new StringBuffer("IdEnum{");sb.append("code=").append(code);sb.append(", value='").append(value).append('\'');sb.append(", biz='").append(biz).append('\'');sb.append(", type='").append(type).append('\'');sb.append(", prefix='").append(prefix).append('\'');sb.append('}');return sb.toString();}
}
在使用Leaf生成Id时,我们只需要@Autowired IdService即可使用,通过调用getId方法即可。
# transport_order 与 biz_tag字段的值相同
http://192.168.150.101:28838/api/segment/get/transport_order#监控
http://192.168.150.101:28838/cache对应的效果图为下:
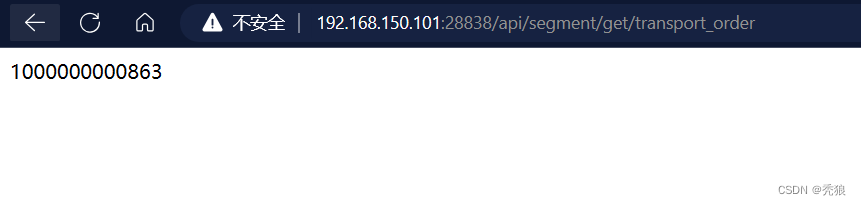

最终完成美团Leaf简单的使用。
这篇关于美团Leaf使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





