本文主要是介绍正则化惩罚(超详细),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在了解正则化之前,我们先要了解损失函数。简单来说,损失函数(loss function)就是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的稳健性就越好。函数表达:

正则化惩罚
1、什么是正则化惩罚?
在机器学习特别是深度学习中,我们通过大量数据集希望训练得到精确、泛化能力强的模型,对于生活中的对象越简洁、抽象就越容易描述和分别,相反,对象越具体、复杂、明显就越不容易描述区分,描述区分的泛化能力就越不好。比如,描述一个物体是“方的”,那我们会想到大概这个物体的投影应该是四条边,两两平行且垂直,描述此物体忽略了材质、质量、颜色等等的性状,描述的物体的多,相反,描述的内容越丰富详实则约束越多,识别的泛化性就差,代表的事物就少,比如“一条彩色的白色绣花丝质手帕”,于是我们可以利用正则化找到更为简洁的描述方式的量化过程。
2、正则化法则的定义。
就是把整个模型中的所有权重w的绝对值加起来除以样本数量,其中是一个惩罚的权重,可以称为正则化系数或者惩罚系数,表示对惩罚的重视程度。
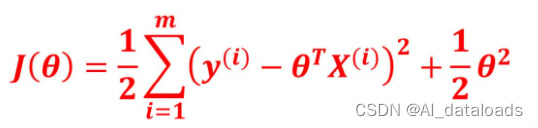
这里的θ值就是正则化的表现
3、正则化表达的方法
(1)L1正则
L1是指向量中各个元素绝对值之和, L1正则化偏向于稀疏,它会自动进行特征选择,去掉一些没用的特征,也就是将这些特 征对应的权重置为0.
(2)L2正则
L2是指各个元素平方之和,L2主要功能是为了防止过拟合,当要求参数越小时,说明模型越简单,而模型越简单则,越趋向于平滑,从而防止过拟合。
代码表现
一般情况下我们用
from sklearn.linear_model import LogisticRegression
这行代码表示
它的含义为
这篇关于正则化惩罚(超详细)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








