本文主要是介绍【Python】通报和点评自动化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言:
没想到从19年底阔别报表自动化,即使做到领导后,仍然逃不掉开发自动化报表的工作…
这次自动化需求,主要是需要点评,用Excel很难办到,SQL和VBA都可以,但要写很多很多脚本,所以思前想后还是用Python吧。
二、结果样式:
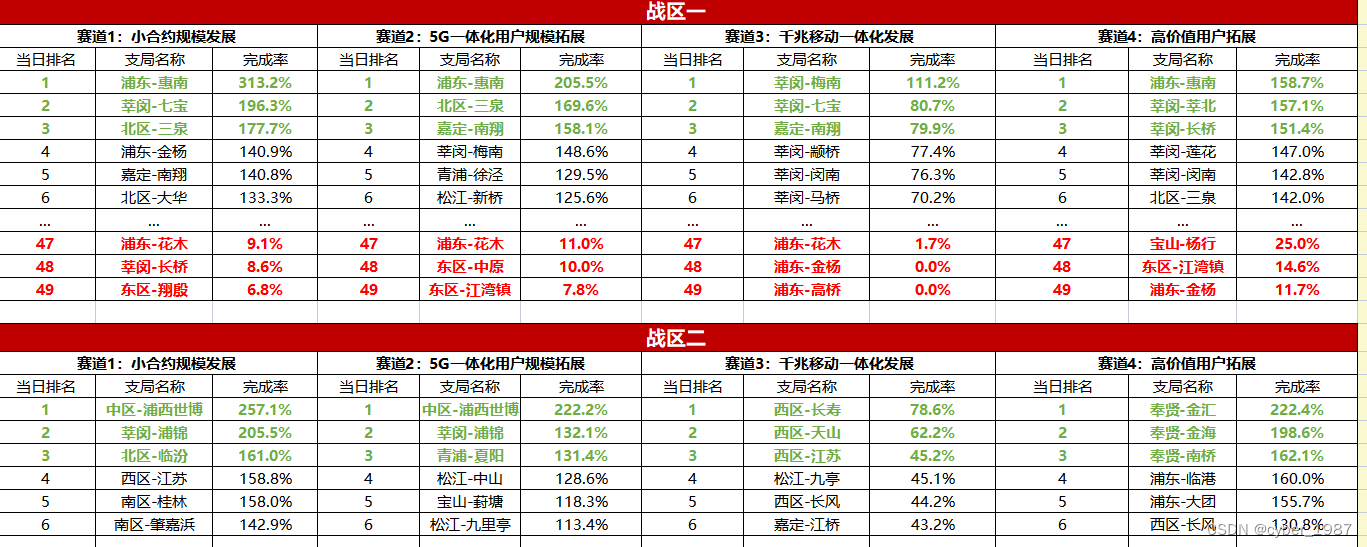
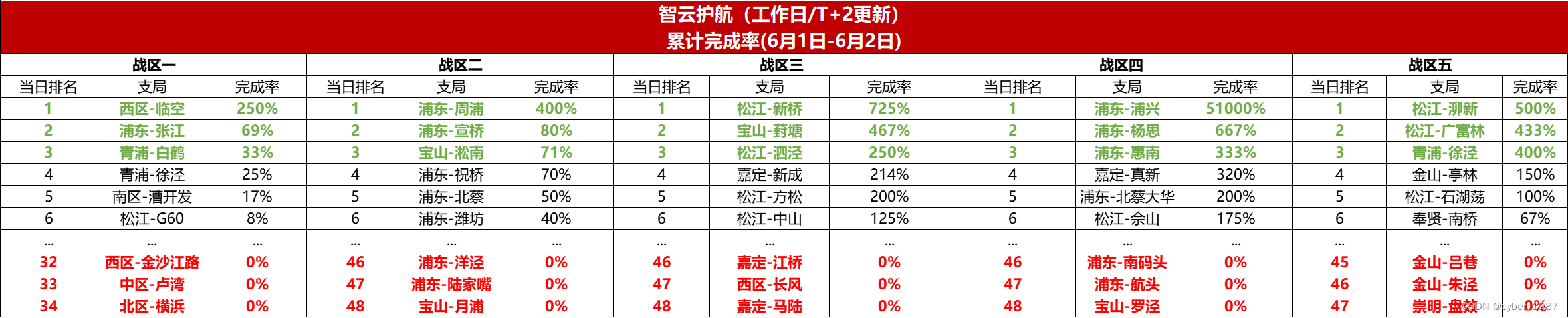

三、Python脚本
Excel的准备就不说了,准备好后可以省略很多很多代码
import pandas as pd
import osdef branch_1_4():'''1-4赛道支局数据'''data = pd.read_excel('2022年第二届天翼杯客户经营大赛日报_公式版.xlsx',sheet_name="赛道1-4支局",skiprows=2,usecols=[3, 8, 14, 26, 32, 38],names=['支局名称', '小合约完成率', '5G完成率', '千兆完成率', '129完成率', '总得分'])zhanqu_dict = {'战区1': [0, 49, [1, 2, 3, 4, 5, 6, '...', 47, 48, 49]],'战区2': [49, 101, [1, 2, 3, 4, 5, 6, '...', 50, 51, 52]],'战区3': [101, 155, [1, 2, 3, 4, 5, 6, '...', 52, 53, 54]],'战区4': [155, 191, [1, 2, 3, 4, 5, 6, '...', 34, 35, 36]]}total_df = pd.DataFrame(columns=['战区', '排名_小合约', '支局名称_小合约', '完成率_小合约', '排名_5G', '支局名称_5G', '完成率_5G','排名_千兆', '支局名称_千兆', '完成率_千兆', '排名_129', '支局名称_129', '完成率_129'])temp_df2 = pd.DataFrame({'战区': '', '排名_小合约': '', '支局名称_小合约': '', '完成率_小合约': '', '排名_5G': '','支局名称_5G': '', '完成率_5G': '', '排名_千兆': '', '支局名称_千兆': '', '完成率_千兆': '','排名_129': '', '支局名称_129': '', '完成率_129': ''}, index=['A'])branch_judge_dict = {'战区1': {'前三': [], '后三': []}, '战区2': {'前三': [], '后三': []},'战区3': {'前三': [], '后三': []}, '战区4': {'前三': [], '后三': []}}for k, v in zhanqu_dict.items():temp_data = data.iloc[v[0]:v[1], :]# 这边获得支局总得分的前三和后三temp_data2 = temp_data.sort_values('总得分', ascending=False)branch_judge_dict[k]['前三'] = list(temp_data2['支局名称'])[:3]temp_data2 = temp_data.sort_values('总得分', ascending=True)branch_judge_dict[k]['后三'] = list(temp_data2['支局名称'])[:3]# 这边获得支局分赛道的结果temp_dict = {}for ele in ['小合约', '5G', '千兆', '129']:temp_data = temp_data.sort_values(ele + '完成率', ascending=False)top6_name = list(temp_data['支局名称'])[:6]last3_name = list(temp_data['支局名称'])[-3:]temp_name = top6_name + ['...'] + last3_nametop6_score = list(temp_data[ele + '完成率'])[:6]last3_score = list(temp_data[ele + '完成率'])[-3:]temp_score = top6_score + ['...'] + last3_scoretemp_dict['战区'] = ktemp_dict['排名_' + ele] = v[2]temp_dict['支局名称_' + ele] = temp_nametemp_dict['完成率_' + ele] = temp_scoretemp_df = pd.DataFrame(temp_dict)total_df = total_df.append(temp_df, ignore_index=True)total_df = total_df.append(temp_df2, ignore_index=True)total_df.to_csv('赛道1-4支局排名数据.csv', encoding='gbk', index=False)branch_judge_text = '【支局】1至4赛道\n'for k, v in branch_judge_dict.items():branch_judge_text += k + ':领先 ' + '、'.join(v['前三']) + ';' + '落后 ' + '、'.join(v['后三']) + ';\n'with open('支局点评.txt', 'w') as f:f.write(branch_judge_text)def branch_5():'''赛道5支局数据'''data = pd.read_excel('2022年第二届天翼杯客户经营大赛日报_公式版.xlsx',sheet_name="赛道5",skiprows=19,usecols=[3, 9, 10],names=['支局名称', '时序完成率', '排名'])zhanqu_dict = {'战区1': [0, 34, [1, 2, 3, 4, 5, 6, '...', 32, 33, 34]],'战区2': [34, 82, [1, 2, 3, 4, 5, 6, '...', 46, 47, 48]],'战区3': [82, 130, [1, 2, 3, 4, 5, 6, '...', 46, 47, 48]],'战区4': [130, 178, [1, 2, 3, 4, 5, 6, '...', 46, 47, 48]],'战区5': [178, 225, [1, 2, 3, 4, 5, 6, '...', 45, 46, 47]],}for k, v in zhanqu_dict.items():temp_data = data.iloc[v[0]:v[1], :]temp_data = temp_data.sort_values('时序完成率', ascending=False)temp_dict = {}top6_name = list(temp_data['支局名称'])[:6]last3_name = list(temp_data['支局名称'])[-3:]temp_name = top6_name + ['...'] + last3_nametop6_score = list(temp_data['时序完成率'])[:6]last3_score = list(temp_data['时序完成率'])[-3:]temp_score = top6_score + ['...'] + last3_scoretemp_dict[k + '排名'] = v[2]temp_dict[k + '支局'] = temp_nametemp_dict[k + '完成率'] = temp_scoretemp_df = pd.DataFrame(temp_dict)if k == '战区1':total_df = temp_dfelse:total_df = pd.concat([total_df, temp_df], axis=1)total_df.to_csv('赛道5支局排名数据.csv', encoding='gbk', index=False)if __name__=="__main__":file_list = os.listdir('.')for file in file_list:if file in ['赛道1-4支局排名数据.csv','赛道5支局排名数据.csv','支局点评.txt']:os.remove(file)branch_1_4()branch_5()
PS:不要问我要清单,内部数据,不可能给的!
这篇关于【Python】通报和点评自动化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




