本文主要是介绍废物的自学之路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据范围(什么时候用高精)

高精度加法
//高精度-----加法
int a[600],b[600],c[600];
int len;
void jia(string A,string B)
{memset(a,0,sizeof(a));memset(b,0,sizeof(b));memset(c,0,sizeof(c));len=max(A.length(),B.length());for(int i=A.length()-1,j=1;i>=0;j++,i--)a[j]=A[i]-'0';for(int i=B.length()-1,j=1;i>=0;j++,i--)b[j]=B[i]-'0';for(int i=1;i<=len;i++){c[i]+=a[i]+b[i];c[i+1]=c[i]/10;c[i]=c[i]%10;}if(c[len+1]>0) len++;//逆序输出for(int i=len;i>0;i--){cout<<c[i];}
} 高精度乘法
//高精度-----乘法
int a[4005],b[4005],c[4005];
int len;
void cheng(string A,string B)
{memset(a,0,sizeof(a));memset(b,0,sizeof(b));memset(c,0,sizeof(c));len=A.length()+B.length();for(int i=A.length()-1,j=1;i>=0;j++,i--)a[j]=A[i]-'0';for(int i=B.length()-1,j=1;i>=0;j++,i--)b[j]=B[i]-'0';for(int i=1;i<=A.length();i++){for(int j=1;j<=B.length();j++){c[i+j-1]+=a[i]*b[j];}}for(int i=1;i<=len;i++){c[i+1]+=c[i]/10;c[i]=c[i]%10;}while(c[len]==0) len--; //去掉前导0 if(len < 1 ) len=-1; //处理0
} 简单的数据结构
1、可变数组
头文件: #include<vector>
1)vector<int> v(N,i) :建立一个可变数组v,内部元素是int,最开始有n个元素,每个元素初始化为i
2)v.push_back(a) :将元素a插入到数组v的末尾,并增加数组长度
3)v.size() :返回数组v的长度
4)v.resize(n,m): 重新调整数组大小为n,如果n比原来小(删),比原来大,新增部分初始化为m
2、栈
头文件: #include<stack>
1)stack<int> s :建立一个栈s,其内部元素是int
2)s.push(a) :将元素a压进栈s
3)s.pop() :将s的栈顶元素弹出
4)s.top() :查询s的栈顶元素
5)s.size() :查询s的元素个数
6)s.empty() :查询s是否为空
3、队列
头文件: #include<queue>
1)queue<int> q :建立一个队列q,其内部元素是int
2)q.push(a) :将元素a插入到队列q的队尾
3)q.pop() :删除队列q的队首元素
4)q.front() :查询q的队首元素
5)q.back() :查询q的队尾元素
6)q.size() :查询q的元素个数
7)q.empty() :查询q是否为空
优先队列
priority_queue<int> q;//默认为数值大的优先priority_queue<int,vector<int>,less<int> >//less<int> 数值大的优先
priority_queue<int,vector<int>,greater<int> >//greater<int> 数值小的优先
priority_queue, 优先队列,默认是大根堆
size()
empty()
push() 插入一个元素
top() 返回堆顶元素
pop() 弹出堆顶元素
定义成小根堆的方式:priority_queue<int, vector<int>, greater<int>> q;
4、链表
头文件: #include<list>
1)list<int> a :定义一个int类型的链表
2)int arr[5]={1,2,3}; list<int> a(arr,arr+3) :从数组arr中的前三个元素作为链表a的初始值
3)a.size() :返回链表的结点数量
4)list<int>::iterator it :定义一个名为it的迭代器
5)a.begin(); a.end() :链表开始和末尾的迭代器指针
6)it++; it-- :迭代器指向前一个元素和后一个元素
7)a.push_front(x); a.push_back(x) :在链表开头或是末尾插入元素x
8)a.insert(it,x) :在迭代器it的前插入x
9)a.pop_front(); a.pop_back() :删除链表开头或者末尾
10)a.erase(it) :删除迭代器it所在的元素
11)for(it=begin();it!=a.end();it++) :遍历链表
5、集合
本质是红黑树(一种比较优秀的平衡二叉树)
(有序,无重复)重要!!!
头文件: #include<set>
1) set<int> ds :建立一个名字叫做 ds 的、元素类型为int的集合
2) ds.insert(x) :在集合中插入一个元素,如果这个元素已经存在,则什么都不干
3) ds.erase(x) :在集合中删除元素 x ,如果这个数不存在,则什么都不干
4) ds.erase(it) :删除集合中地址为 it 的元素
5) ds.end() :返回集合中最后一个元素的下一个元素地址。很少使用,配合其他方法进行比较,以确认某个元素是否存在
6) ds.find(x) :查询 x 在集合中的地址,如果这个数不存在,则返回 ds.end()
7) ds.lower_bound(x) :查询不小于 x 的最小的数在集合中的地址,如果这个数不存在,则返回 ds.end()
8) ds.upper_bound(x) :查询大于 x 的最小的数在集合中的地址,如果这个数不存在,则返回 ds.end()
9) ds.empty() :如果集合是空的,则返回 1,否则返回 0
10) ds.size() :返回集合中元素的个数
11) set<int>::iterator it :定义一个名为 it 的迭代器
12)遍历:for(it=ds.begin();it!=ds.end();it++)
13) ds.clear() : 清空全部元素
14)保留有序的特性,但是可以有重复元素 multiset<int> ds
6、map关联集合
1) map<A,B> ds :建立一个名字叫做ds,下标类型为A,元素类型为B的映射表,例如map<string,int> 就是一个将string映射到int的映射表
2) ds[A]=B :把这个"数组"中下标为A的位置的值变成B,这里下标可以是任意类型,不一定限定为大于0的整数,比如map<string,string> da,就可以进行ds["wdnmd"]="gan"的操作
3) ds[A] :访问这个"数组"中下标为A的元素,比如可以进行cout<<ds["wdnmd"]<<endl;这样的操作
4) ds.end() :返回映射表中最后一个元素的下一个元素地址
5) ds.find(x) :查询x在映射表中的地址,如果这个数不存在,返回ds.end() (下标!!!)
6) ds.empty() :如果映射表是空的,返回1,否则返回0
7) ds.size() :返回映射表中的元素个数
8)ds.count(x) : 查询下标为x的元素,有返回1,无返回0 (下标!!!)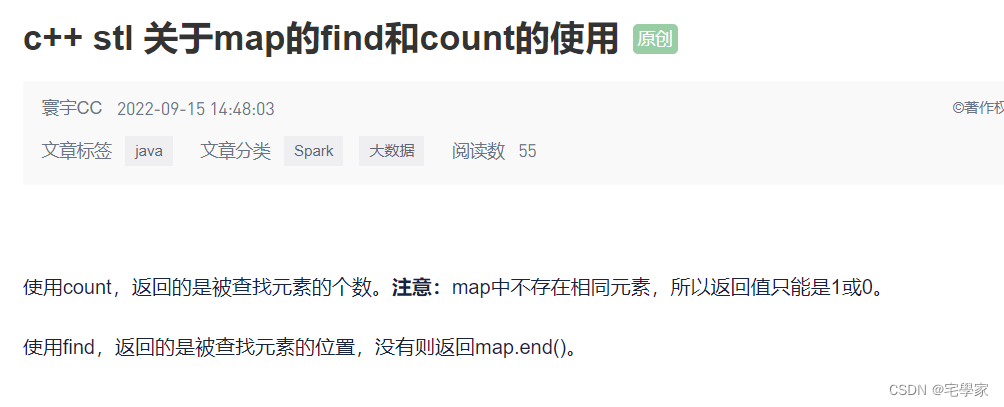
二维数组与三维数组
先理解二维数组,int a[3][4]; 理解成3行4列。例如:
1 2 3 4 // 第1行
5 6 7 8 // 第2行
9 10 11 12 // 第3行。 你可以理解成 行索引号 是直角坐标y值,列索引号 是直角坐标x值.
现在变3维 int a[2][3][4]; 理解成深度(或高度)有2层的 3行4列 的数组。
原来的 1 到 12 数值在 第一层,现在 有了第二层,第二层 数值是
13 14 15 16
17 18 19 20
21 22 23 34
所以 3 维数组 int a[z][y][x], 就有 z 层 y*x 大小的矩阵。
元素是二维数组的一维数组
头文件
#include<iostream> // cin
#include<cstring> //memset()函数头文件
#include<cstdio> //scanf()、printf() 头文件
#include<string> // string数据类型 头文件
#include<cmath> //数学相关
#include<algorithm> //__gcd()
typedef long long LL; //把long long替换成 LL 以节约打字时间
线性筛法(欧拉筛)
bool isPrime[100000010];
//isPrime[i] == 1表示:i是素数
int Prime[6000010], cnt = 0;
//Prime存质数void GetPrime(int n)//筛到n
{memset(isPrime, 1, sizeof(isPrime));//以“每个数都是素数”为初始状态,逐个删去isPrime[1] = 0;//1不是素数for(int i = 2; i <= n; i++){if(isPrime[i])//没筛掉 Prime[++cnt] = i; //i成为下一个素数for(int j = 1; j <= cnt && i*Prime[j] <= n/*不超上限*/; j++) {//从Prime[1],即最小质数2开始,逐个枚举已知的质数,并期望Prime[j]是(i*Prime[j])的最小质因数//当然,i肯定比Prime[j]大,因为Prime[j]是在i之前得出的isPrime[i*Prime[j]] = 0;if(i % Prime[j] == 0)//i中也含有Prime[j]这个因子break; //重要步骤。见原理}}
}并查集
int f[10001];//初始化
void set(int f[])
{for(int i=1;i<=10000;i++){f[i]=i;}
}//查找 (路径优化)
int find(int x)
{if(f[x]==x) return x;elsereturn f[x]=find(f[x]);
}//连接
void join(int a,int b)
{int x=find(a),y=find(b);if(x!=y) f[x]=y;
}
字符串相关
1、fgets()函数
读入一行字符串,并存入数组中,空格也一起存下了
用法:fgets(s,sizeof(s),stdin); //char s[20]; 只能是字符型数组,不能是string类型
fgets(s,sizeof(s),stdin); //char s[20]; 只能是字符型数组,不能是string类型getline()函数,可以将完整一行的输入数据读取到字符串中,无论这一行是否有空格。
用法:getline(cin,字符串名称) // cin是输入流 只能是string类型,不能是数组
getline(cin,s); // 只能是string类型,不能是数组2、sscanf()函数
可以从已经存储下来的字符串中读入信息。(会自动忽略掉空格)貌似只能数组
sscanf(s,"%d",&a); // 从s字符串中读入一个整数asprintf()函数,将信息输出到字符串中。
sprintf(s,"%d",a); // 将一个int类型的数a输出到字符串s中详情:洛谷P1957
3、字符串string
- string s :定义一个名字为s的字符串变量
- s=s+str 或 s.append(str) :在字符串s后面拼接字符串 str
- s < str :比较字符串 s 的字典序是否在字符串 str 的字典序之前
- s.size() 或 s.length() :得到字符串 s 的长度
- s.substr(pos,len) :截取字符串 s 从第 pos 个位置开始 len 个字符,并返回这个字符串
- s.insert(pos,str) :在字符串 s 的第 pos 个字符之前,插入字符串 str ,并返回这个字符串
- s.find(str,[pos]) :在字符串 s 中从第 pos 个字符开始查找 str ,并返回位置,找不到返回-1。pos可省略,默认值是0
详情:洛谷P5734
排序相关
1、快速排序
void qsort(int a[],int l,int r)
{int i=l,j=r,flag=a[(l+r)/2];do{while(a[i]<flag) i++;while(a[j]>flag) j--;if(i<=j){int tmp=a[i];a[i]=a[j];a[j]=tmp;i++,j--;}}while(i<=j);if(l<j) qsort(a,l,j);if(i<r) qsort(a,i,r);
}2、sort()函数(a,a+n,cmp)
需要用到algorithm头文件
(cmp通常使用结构体来编写更复杂的比较器)
3、unique(a,a+n)
对a数组从a[0]到a[n-1]进行去重,要求a数组已经有序
返回去重后最后一个元素对应的指针(将它减去a的指针得到的值就是去重后元素的个数)
4、nth_element() :
C++的STL库中的nth_element()方法,默认是求区间第k小的(划重点)。
头文件是#include<algorithm>
详情点这里
5、 lower_bound(a,a+n,...) upper_bound(a,a+n,...)
关于lower_bound( )和upper_bound( )的常见用法_brandong的博客-CSDN博客
lower_bound():在值有序的数组连续地址找到第一个位置并返回其地址
upper_bound():在值有序的数组连续地址中找到最后一个位置并返回其地址
可翻书 P177
网格相关(数 长方形 和 正方形 )
1、枚举方形的边长(统计边长n x m的大矩形中包含了多少边长a x b的小矩形)
for(LL a=1;a<=n;a++)for(LL b=1;b<=n;b++)if(a==b)squ+=(n-a+1)*(m-b+1); //正方形elserec+=(n-a+1)*(m-b+1); //长方形
2、公式(虽然孩子推不出来)
正方形和长方形的数量总和:n(n+1)m(m+1) /4
抽样选数相关
1、用二进制来选数
(一般最长为64位)
内建函数:__builtin_popcount() (统计二进制中1的个数)直接返回一个数2进制下1的个数
2、全排列问题
next_permutation(a,a+n) 在数组表示内存中产生严格的下一个字典序排列
一般情况下1秒钟很难枚举超过11个元素的全排列
最大公约数
1、辗转相除法
int gcd(int x,int y)
{if(y==0) return x; //递归边界 else return gcd(y,x%y);
}2、头文件 #include<algorithm>
__gcd(x,y)
最小公倍数:(a*b)/ 最小公约数
字母相关
1、只将大写字母变为小写字母(貌似没啥用)
头文件:#include <stdlib.h>
定义函数:int tolower(int c);
卡特兰数
(不懂,先放这里)
二分
1、二分查找
1)左闭右开区间 [ l , r )
序列相同的数有多个,想找 最小 序列
int find(int x)
{int l=1,r=n+1;while(l<r){int mid=l+(r-l)/2;if(a[mid]>=x) r=mid;else l=mid+1;}if(a[l]==x)return l;elsereturn 0;
}2)左开右闭区间 ( l , r ]
序列相同的数有多个,想找 最大 序列
int find(int x)
{int l=1,r=n+1;while(l<r){int mid=l+(r-l)/2;if(a[mid]<=x) l=mid+1;else r=mid;}if(a[l-1]==x)return l-1;elsereturn 0;
}3)闭区间
int find(int L,int R)
{int mid,ans;while(L<=R){if(p(mid)) //条件成立{ans=mid; //用ans来记录mid R=mid-1; } elseL=mid+1; }return ans;
}搜索
1、深度优先搜索
void dfs(int k) //k代表递归层数,或者说要填第几个空
{if( 所有空已经填完了 ){判断最优解/记录答案;return;}for( 枚举这个空能填的选项 ){if( 这个选项是合法的 ){记下这个空(保存现场);dfs(k+1);取消这个空(恢复现场); } }
}
2、广度优先搜索
可以找到步骤最少,距离最近的点
Q.push(初始状态); //将初始状态入队while(!Q.empty()){State u=Q.front(); //取出队首Q.pop(); //出队for(枚举所有可扩展状态) //找到u的所有可达状态vif(是合法的) //v需要满足某些条件,如未访问过、未在队内等 Q.push(v); //入队(同时可能需要维护某些必要信息) } 快速幂
让计算机很快地求出a^b
int quickPower(int a, int b)//是求a的b次方
{int ans = 1, base = a;//ans为答案,base为a^(2^n)while(b > 0)//b是一个变化的二进制数,如果还没有用完{if(b & 1)//&是位运算,b&1表示b在二进制下最后一位是不是1,如果是:ans *= base;//把ans乘上对应的a^(2^n)base *= base;//base自乘,由a^(2^n)变成a^(2^(n+1))b >>= 1;//位运算,b右移一位,如101变成10(把最右边的1移掉了),10010变成1001。现在b在二进制下最后一位是刚刚的倒数第二位。结合上面b & 1食用更佳}return ans;
}int a[30000];
int l=1;
memset(a,0,sizeof(a));
void quickPower()
{// l是答案长度 for(int i=1;i<=l;i++) a[i]*=2;for(int i=1;i<=l;i++){a[i+1]+=a[i]/10;a[i]=a[i]%10;}if(a[l+1]>0) l++;
} 洛谷P1226 【模板】快速幂||取余运算
汉内塔
n:盘子数 从a移动到c,需要借助b
//汉内塔问题
int ans=0;
void hanoi (int n,char a,char c,char b)
{if(n==0) return;hanoi(n-1,a,b,c);printf("%d %c %c\n",n,a,c);hanoi(n-1,b,c,a);
}
并查集
处理不相交可合并集合关系的数据结构(书p240)
洛谷P1551
落谷P1536
int a[2000];
int b[2000];
int find(int x) //查询是否是同一个集合
{if(x==a[x]) return x;return a[x]=find(a[x]);
}
void join(int x,int y) //连接两个集合
{int f1=find(x),f2=find(y);if(f1!=f2) a[f1]=f2;
}
int main()
{int n,m; while(scanf("%d %d",&n,&m)!=EOF && n!=0){for(int i=1;i<1500;i++)a[i]=i;for(int i=1;i<=m;i++){int x,y;cin>>x>>y;join(x,y);}for(int i=1;i<=n;i++){b[i]=find(i);}sort(b+1,b+n+1);int len=unique(b+1,b+n+1)-b-2;cout<<len<<endl;}
}杨辉三角
求组合数
LL i,j;LL a[100][100]={0};//杨辉三角 for(i=0;i<60;i++){a[i][0]=a[i][i]=1;for(j=1;j<i;j++){a[i][j]=a[i-1][j]+a[i-1][j-1];}}//输出for(i=0;i<60;i++){for(j=0;j<=i;j++){cout<<a[i][j]<<" ";}cout<<endl;} 二叉树
二叉树的定义
//二叉树的定义
struct TreeNode
{int data;TreeNode *left;TreeNode *right;.
}; 已知前序和中序,求后序
//已知前序和中序,求后序
void houxu(string pre,string in)
{//序列为空,停止 if(pre.empty()) return;//取前序的第一个,根 char root=pre[0];//删掉 pre.erase(pre.begin());//在中序中找 位置 int k=in.find(root);//切割前序中左 string preleft=pre.substr(0,k);//切割前序中右 string preright=pre.substr(k);//切割中序左 string inleft=in.substr(0,k);//切割中序右 string inright=in.substr(k+1);//左 右 根 houxu(preleft,inleft);houxu(preright,inright);cout<<root;
} 已知后序和中序,求前序
//已知后序和中序,求前序
void pre(string in,string post)
{if(post.empty()) return;char root=*(post.end()-1);post.erase(post.end()-1);int k=in.find(root);string postleft=post.substr(0,k);string postright=post.substr(k);string inleft=in.substr(0,k);string inright=in.substr(k+1);cout<<root;pre(inleft,postleft);pre(inright,postright);
}指针
1、常量指针
const修饰指针(简单地说,就是不可以通过指针去修改值)
const int* p = &a;特点:指针的指向可以修改,但是指针指向的值不能修改
*p=20; (错误,指针指向的值不可以修改)
p=&b; (正确,指针指向可以修改)2、指针常量
const修饰常量
int* const p = &a;特点:指针得指向不可以修改,指针指向的值可以修改
内存四区
代码区、全局区、栈区(自动释放)、堆区(手动释放)
图论相关
邻接表储存图
//图论
邻接表法:
vector<int> p[100];
int n,m;
cin>>n>>m;
//输入
for(int i=1;i<=m;i++)
{int u,v;cin>>u>>v;p[u].push_back(v);
}
//排序
for(int i=1;i<=n;i++)
{sort(p[i].begin(),p[i].end());
} 遍历图
dfs:
bool visit[maxn];
//dfs模板
void dfs(int x)
{if(!visit[x]){visit[x]=true;cout<<x<<" ";}for(int i=0;i<G[x].size();i++){if(!visit[G[x][i]]) dfs(G[x][i]);}
}bfs:
//bfs模板
queue<int> q; void bfs(int x)
{if(!visit[x]){visit[x]=true;q.push(x);}while(!q.empty()){int k=q.front();cout<<k<<" ";q.pop();for(int i=0;i<G[k].size();i++){if(!visit[G[k][i]]){visit[G[k][i]]=true;q.push(G[k][i]);}}}
}
拓扑排序
记忆化搜索----实现拓扑排序 广义上的拓扑排序
//记忆化搜索----实现拓扑排序 广义上的拓扑排序
const int maxn=10005;
vector<int> G[maxn];
int len[maxn]; //某点的工作时间
int vis[maxn]; //某点的最短时间 int dfs(int x)
{if(vis[x]!=0) return vis[x];for(int i=0;i<G[x].size();i++){vis[x]=max(vis[x],dfs(G[x][i]));}vis[x]=vis[x]+len[x];return vis[x];
}int main()
{int n;cin>>n;//建图 for(int i=1;i<=n;i++){int x;cin>>x>>len[i];int y;while(cin>>y){if(y==0) break;// y 为 x 的准备事务,y->x G[y].push_back(x);}}memset(vis,0,sizeof(vis));int ans=0;for(int i=1;i<=n;i++){ans=max(ans,dfs(i));}cout<<ans;
}基于bfs的拓扑排序
- 初始化队列,将入度为 0 的节点放入队列。
- 取出队首,遍历其出边,将能够到达的点入度减一,同时维护答案数组。
- 若在此时一个点的入度变为 0,那么将其加入队列。
- 回到第二步,直到队列为空。
const int maxn=10005;
vector<int> G[maxn];
int len[maxn]; //某点的工作时间
int f[maxn]; //某点的最短时间
int ind[maxn]; queue<int> q;
int n;void bfs()
{for(int i=1;i<=n;i++){if(ind[i]==0) {q.push(i);f[i]=len[i];}}while(!q.empty()){int k=q.front();q.pop();for(int i=0;i<G[k].size();i++){int u=G[k][i];ind[u]--;if(ind[u]==0) q.push(u);f[u]=max(f[u],f[k]+len[u]);}}
}int main()
{cin>>n;//建图 memset(ind,0,sizeof(ind));for(int i=1;i<=n;i++){int x;cin>>x>>len[i];int y;while(cin>>y){if(y==0) break;// y 为 x 的准备事务,y->x G[y].push_back(x);ind[x]++;}}memset(f,0,sizeof(f));bfs();int ans=0;for(int i=1;i<=n;i++){ans=max(ans,f[i]);}cout<<ans;
}最小生成树
Kruskal:
先把边按照权值进行排序,用贪心的思想优先选取权值较小的边,并依次连接,若出现环则跳过此边(用并查集来判断是否存在环)继续搜,直到已经使用的边的数量比总点数少一即可。
#include<bits/stdc++.h>
using namespace std;const int maxn=2e5+5;struct node
{int u,v,w;
};
node E[maxn];bool cmp(node x,node y)
{return x.w<y.w;
}int f[maxn];int find(int x)
{if(f[x]==x) return f[x];else return f[x]=find(f[x]);
}int main()
{int n,m;cin>>n>>m;//存入 for(int i=1;i<=m;i++){int u,v,w;cin>>u>>v>>w;E[i].u=u;E[i].v=v;E[i].w=w;}sort(E+1,E+m+1,cmp);//初始for(int i=1;i<=n;i++){f[i]=i;} //kruint ans=0;int num=0;for(int i=1;i<=m;i++){int x=find(E[i].u);int y=find(E[i].v);if(x==y) continue;f[x]=y;ans=ans+E[i].w;num++;}if(num!=n-1) cout<<"orz";elsecout<<ans;
}链式前向星
//链式前向星
struct node
{int to;int next;int w;
};
node Edge[maxn];int head[maxn];int cnt=0;void add(int u,int v,int w)
{cnt++;Edge[cnt].next=head[u];Edge[cnt].to=v;Edge[cnt].w=w;head[u]=cnt;
}单源最短路径
无优化版本(迪杰斯特拉)
//单源最短路径 迪杰斯特拉算法bool visit[maxn];for(int i=1;i<=n;i++) dis[i]=2147483647;dis[s]=0;memset(visit,0,sizeof(visit));int pos=s;while(!visit[pos]){visit[pos]=true;for(int i=head[pos];i!=0;i=Edge[i].next){if( !visit[Edge[i].to] && dis[Edge[i].to]>dis[pos]+Edge[i].w)dis[Edge[i].to]=dis[pos]+Edge[i].w;}long long int minn=2147483647;for(int i=1;i<=n;i++){if(!visit[i] && dis[i] < minn){minn=dis[i];pos=i;}}}for(int i=1;i<=n;i++){cout<<dis[i]<<" ";}使用优先队列进行堆优化
#include<bits/stdc++.h>
using namespace std;const int maxn=2e5+5;struct node
{int to;int next;int w;
};
node Edge[maxn];
int head[maxn];
int cnt=0;void add(int u,int v,int w)
{cnt++;Edge[cnt].next=head[u];Edge[cnt].to=v;Edge[cnt].w=w;head[u]=cnt;
}struct priority
{int id;int ans;//重载运算符bool operator < (const priority &x) const{return x.ans<ans;}
};priority_queue<priority> q;bool visit[maxn];
long long int dis[maxn];int main()
{int n,m,s;cin>>n>>m>>s;for(int i=1;i<=m;i++){int u,v,w;cin>>u>>v>>w;add(u,v,w);}for(int i=1;i<=n;i++){dis[i]=2147483647;}dis[s]=0;q.push((priority){s,dis[s]});memset(visit,0,sizeof(visit));while(!q.empty()){priority tmp=q.top();q.pop();int k=tmp.id;if(!visit[k]){visit[k]=true;for(int i=head[k];i!=0;i=Edge[i].next){int z=Edge[i].to;if( !visit[z] && dis[z]>dis[k]+Edge[i].w){dis[z]=dis[k]+Edge[i].w;q.push((priority){z,dis[z]});} }}}for(int i=1;i<=n;i++){cout<<dis[i]<<" ";}
}这篇关于废物的自学之路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






