本文主要是介绍听小董谝存储七,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
序章
一些设定
关于WAL
恢复
我爱glt
序章
前面几章,我们已经明白了particle层的读写流程。但是我们还有问题如果机器断电了,数据怎么恢复。
一些设定
首先我们得先确定下面几个问题
1 什么时候需要恢复数据?
当进程挂掉的时候
当机器直接死机了
2 什么时候恢复的数据会真的被使用?
我们有三个副本,当一个或者两个副本死掉了,我们会指向搬迁操作,把数据在新的地方变成新的三副本。只有当3个机器都死掉了,我们才需要使用恢复的数据。
3 哪些数据需要恢复?
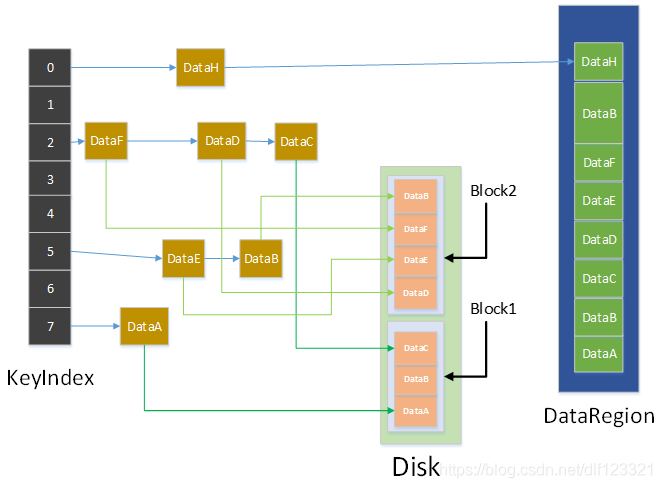
图一 particle层的数据分布
如上图,我们先分析一下,图里面的几个模块都在什么地方。
共享内存里:黄色的索引块,DataRegion里面的数据
磁盘里:那就是已经下刷到磁盘里面的数据。
不管是否断电,磁盘里的数据都在,跑不了。我们不用管。
如果只是进程死掉了,那么进程重启的时候,只要重新把共享内存拉起来就能继续工作了。
如果是机器之间挂掉了,重新启动机器后,共享内存没有了。如果我们此时什么都不做,那我们面对的情况就是一个磁盘,磁盘里面有一堆数据,但是我压根不知道哪个key在哪个位置。
没有桥,老子就过不了河了么?
我tm绕着地球走一圈照样能过去!
就好像你给我一个没有了索引的字典,你让我怎么查?
没有索引的字典就不能查了么?
当然可以。我把字典的正文一页页的看,然后看到一个字就把它记录到索引里。我手动恢复索引不就OK了。
我们要恢复的其实就是内存里的索引。
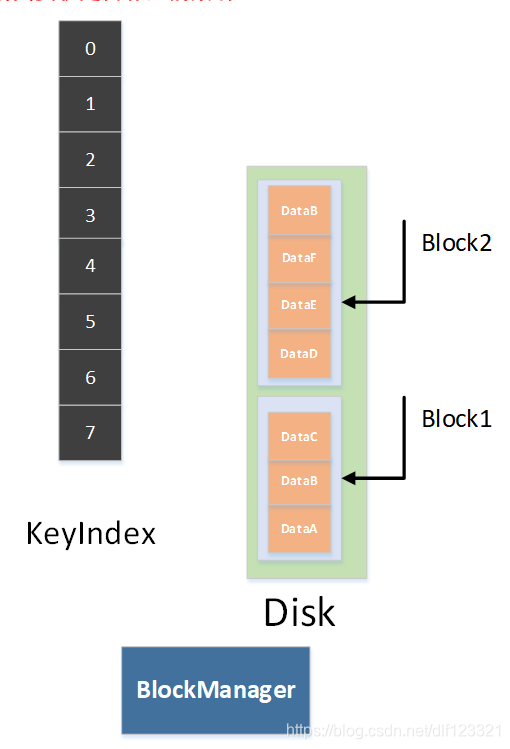
图二 丢失了索引
如上图二,我们没有任何数据索引。可是我们有BlockManager的索引,(前面每次下刷数据,回收block的时候,blockmanager的数据都会落盘)我们按照block生成的顺序从最早到最近依次遍历所有的block就能把数据索引反向补充回来。
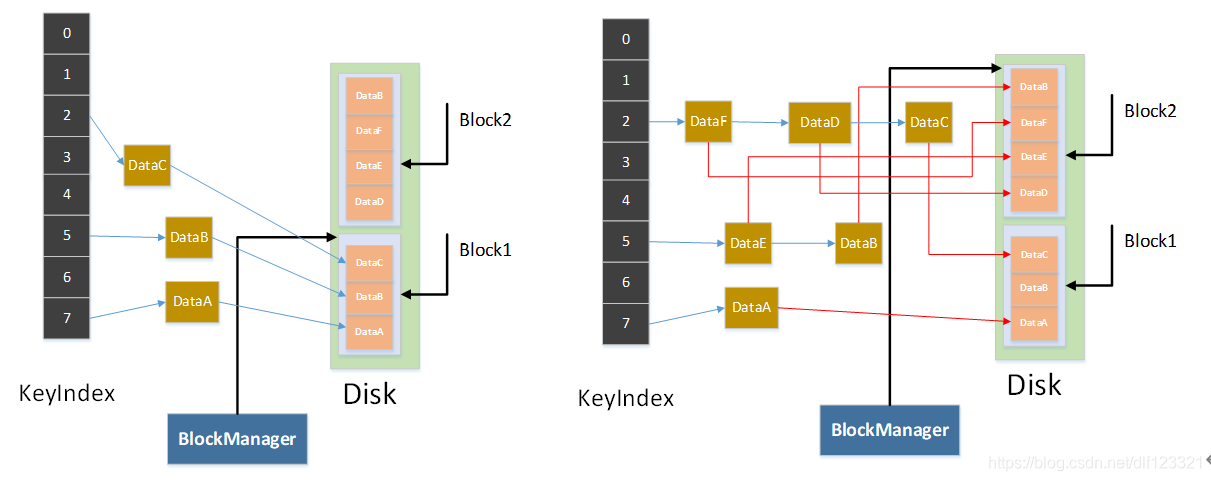
图三 根据blockManager 依次遍历block
图三有两个block里面都有DataB,该怎么处理呢?还需要说么?
搞定了,数据都恢复了。
恢复个屁!
还有一些数据在DataRegion里面呢,那些数据还没有进磁盘呢!断电就没有了。
关于WAL
刚才提到在dataregion里面的数据还没有下刷,都在内存里,断电自然就没有了。那么,咱们就把它们也放到磁盘里。写内存之前,就先放到磁盘里。也就是所谓的WAL(Write Ahead Log)。具体什么流程呢?如下图四的左半部分,就是数据在写入dataregion之前,就先写入缓存,如果缓存里面的数据大于8KB,就下刷到磁盘里的binlog文件里。 (这个文件在mysql里面叫redo log)
(有人说又要下刷磁盘,这恐怕对性能又损失。没办法,我们做的就是一个平衡的事情,而且顺序写ssd,速度也不是慢点不可接受,如果不下刷,或者说压根就不引人binlog机制,速度确实能快点,但是一旦断电就麻烦了)
那磁盘里面的binlog得有多大?换句话说,binlog得保存多久。 看图四的右半部分。Binlog的长度不会大于dataregion的长度。每次从dataregion里面取数据下刷的时候,就会更新binlog的起点。
这样一来,任何时候断电,我们最多损失8KB的数据。(当然,我们也可以来一个数据,就顺序写一次binlog到ssd,但是前面也说了,这就是个平衡,你也可以当缓存大于80KB的时候下刷。)
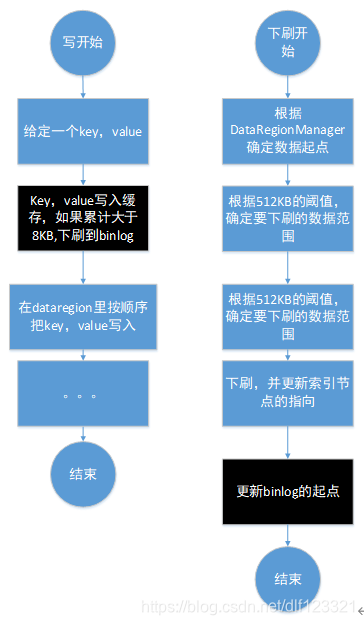
图四 引入wal的写流程
恢复
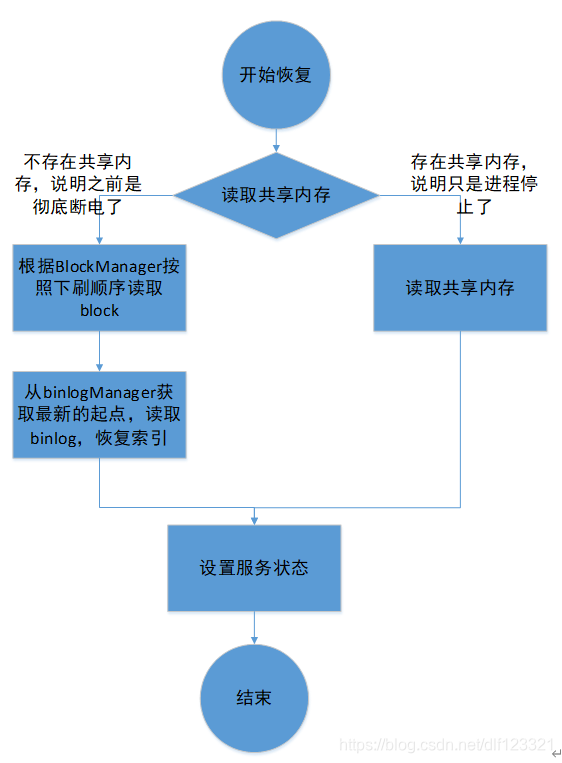
图五 恢复流程
主体流程就不解释了,你就想想你拿到一个只有正文的字典,怎么自己整理出索引。
关于最后还有一个设置服务状态,即使数据全部恢复了,也不会立即对外服务,需要后台开发任务手动设置一个标志位。毕竟三个机器都死的概率不大,真的需要从磁盘恢复数据的频率也不高,具体什么时候开始服务还是需要后台开发再评估一下的。
这篇关于听小董谝存储七的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




