本文主要是介绍SQL Server 2017 Always On AG on Linux(三)AlwaysOn AG 配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现可在 Windows 上使用 SSMS 连接 Linux 上的 SQL Server 配置 AlwaysOn AG。
1. 在节点 server111 实例上创建可用性组,名为 LINUX_SQLAG。

Windows Server 故障转移群集:当可用性组托管在属于 Windows Server 故障转移群集的 SQL Server 的实例上时使用,以实现高可用性和灾难恢复。 适用于所有受支持的 SQL Server 版本。
EXTERNAL :当可用性组托管在由外部群集技术(例如 Linux 上的 Pacemaker)管理的 SQL Server 的实例上时使用,以实现高可用性和灾难恢复。 适用于 SQL Server 2017 (14.x) 及更高版本。
NONE :当可用性组托管在不由群集技术管理的 SQL Server 的实例上时使用,以实现读取缩放和负载均衡。 适用于 SQL Server 2017 (14.x) 及更高版本。
选择 EXTERNAL,Linux 环境下,创建并配置Always On Availability Group后,将安装和配置Pacemaker。“数据库级别运行状况检测” 勾选此框,为可用性组启用数据库级别运行状况检测 (DB_FAILOVER)。 数据库运行状况检测会说明数据库何时不再处于联机状态、何时出错以及何时触发可用性组的自动故障转移。(更多参考:Always On 可用性组的“指定可用性组选项”页)
2. 选择可用性数据库(为了测试,先创建一个完整模式的库并备份)

3. 添加副本并设置

可以看到,故障转移模式从以前的“手动” 和“自动”,变为 “外部(External)”。故障转移模式值 External 用于与 Pacemaker 等Linux集群资源管理器一起处理故障转移。
其他选项配置都差不多:

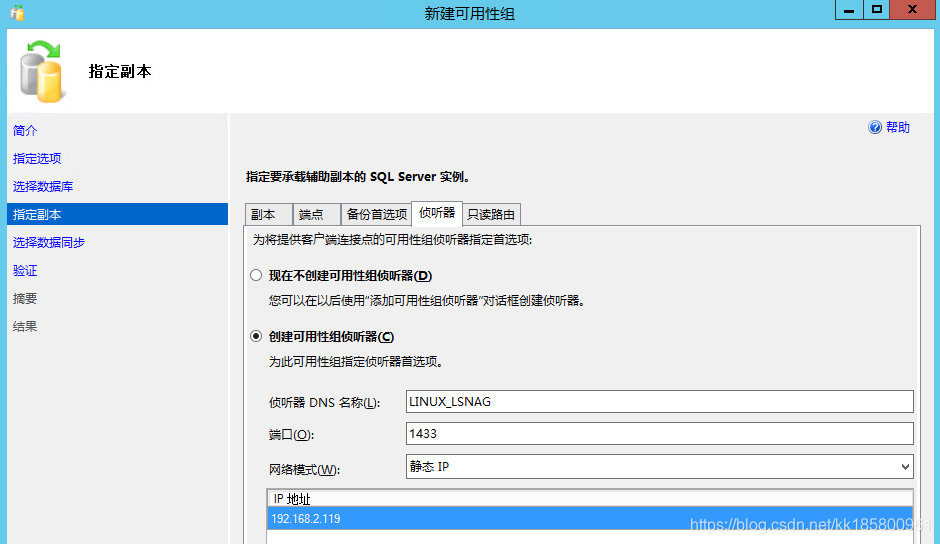
4. 侦听器配置
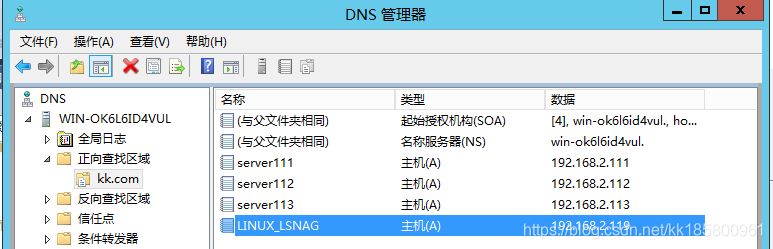
必须手动将侦听器名称添加为DNS记录: LINUX_LSNAG , IP为 192.168.2.119
创建侦听器:
5. 只读路由配置(此处用于测试随意配置的)

6. 选择数据库同步

这里选择 “自动种子设定” ,因为数据库较小。SQL Server 自动为此组中的每个数据库创建次要副本。 自动种子设定要求数据和日志文件路径在参与此组的每个 SQL Server 实例上均相同。(更多参考:“选择初始数据同步”页(AlwaysOn 可用性组向导))
7. 验证及检查


最后忘记截图了………
完成后结果:


Always On Availability Groups 配置脚本如下,在 SQLCMD 模式下,批量执行以下脚本。
(设置 SQLCMD 模式:打开SSMS任意实例查询窗口——>查询——>SQLCMD模式)
--- YOU MUST EXECUTE THE FOLLOWING SCRIPT IN SQLCMD MODE.:Connect 192.168.2.111,1433 -U sa -P sa@PWS123456IF (SELECT state FROM sys.endpoints WHERE name = N'Endpoint_AvailabilityGroup') <> 0
BEGINALTER ENDPOINT [Endpoint_AvailabilityGroup] STATE = STARTED
END
GO:Connect 192.168.2.111,1433 -U sa -P sa@PWS123456IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='AlwaysOn_health')
BEGINALTER EVENT SESSION [AlwaysOn_health] ON SERVER WITH (STARTUP_STATE=ON);
END
IF NOT EXISTS(SELECT * FROM sys.dm_xe_sessions WHERE name='AlwaysOn_health')
BEGINALTER EVENT SESSION [AlwaysOn_health] ON SERVER STATE=START;
END
GO:Connect 192.168.2.112,1433 -U sa -P sa@PWS123456IF (SELECT state FROM sys.endpoints WHERE name = N'Endpoint_AvailabilityGroup') <> 0
BEGINALTER ENDPOINT [Endpoint_AvailabilityGroup] STATE = STARTED
END
GO:Connect 192.168.2.112,1433 -U sa -P sa@PWS123456IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='AlwaysOn_health')
BEGINALTER EVENT SESSION [AlwaysOn_health] ON SERVER WITH (STARTUP_STATE=ON);
END
IF NOT EXISTS(SELECT * FROM sys.dm_xe_sessions WHERE name='AlwaysOn_health')
BEGINALTER EVENT SESSION [AlwaysOn_health] ON SERVER STATE=START;
END
GO:Connect 192.168.2.113,1433 -U sa -P sa@PWS123456IF (SELECT state FROM sys.endpoints WHERE name = N'Endpoint_AvailabilityGroup') <> 0
BEGINALTER ENDPOINT [Endpoint_AvailabilityGroup] STATE = STARTED
END
GO:Connect 192.168.2.113,1433 -U sa -P sa@PWS123456IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='AlwaysOn_health')
BEGINALTER EVENT SESSION [AlwaysOn_health] ON SERVER WITH (STARTUP_STATE=ON);
END
IF NOT EXISTS(SELECT * FROM sys.dm_xe_sessions WHERE name='AlwaysOn_health')
BEGINALTER EVENT SESSION [AlwaysOn_health] ON SERVER STATE=START;
END
GO:Connect 192.168.2.111,1433 -U sa -P sa@PWS123456USE [master]
GO
CREATE AVAILABILITY GROUP [LINUX_SQLAG]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY,
DB_FAILOVER = ON,
DTC_SUPPORT = NONE,
CLUSTER_TYPE = EXTERNAL,
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0)
FOR DATABASE [Demo]
REPLICA ON
N'server111' WITH (ENDPOINT_URL = N'TCP://server111:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N'server112')), SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://server111:1433', ALLOW_CONNECTIONS = ALL)
),
N'server112' WITH (ENDPOINT_URL = N'TCP://server112:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N'server111')), SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://server112:1433', ALLOW_CONNECTIONS = ALL)
),
N'server113' WITH (ENDPOINT_URL = N'TCP://server113:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = ((N'server111',N'server112'),N'server113')), SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://server113:1433', ALLOW_CONNECTIONS = ALL)
);
GO:Connect 192.168.2.111,1433 -U sa -P sa@PWS123456USE [master]
GO
ALTER AVAILABILITY GROUP [LINUX_SQLAG]
ADD LISTENER N'LINUX_LSNAG' (WITH IP ((N'192.168.2.119', N'255.255.255.0')), PORT=1433
);
GO:Connect 192.168.2.112,1433 -U sa -P sa@PWS123456ALTER AVAILABILITY GROUP [LINUX_SQLAG] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
GO
ALTER AVAILABILITY GROUP [LINUX_SQLAG] GRANT CREATE ANY DATABASE;
GO:Connect 192.168.2.113,1433 -U sa -P sa@PWS123456ALTER AVAILABILITY GROUP [LINUX_SQLAG] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
GO
ALTER AVAILABILITY GROUP [LINUX_SQLAG] GRANT CREATE ANY DATABASE;
GO
但此时侦听器的状态是离线的:

虽然 SQL Server Always On Availability Group 安装成功了,但是现在无法进行故障转移

这是因为它仍然没有暴露给 Linux 操作系统。要通过侦听器名称访问 Always On Availability Group,必须在Linux群集资源管理器上注册它。下一篇将安装并配置 Linux 集群资源管理器 Pacemaker。配置完成后,可在 Pacemaker 上注册 SQL Server Always On Availability Group 和侦听器名称。
参考:
配置 SQL Server Always On 可用性组以在 Linux 上实现高可用性
Install and Configure SQL Server 2017 Availability Groups on Linux - Part 3
这篇关于SQL Server 2017 Always On AG on Linux(三)AlwaysOn AG 配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




