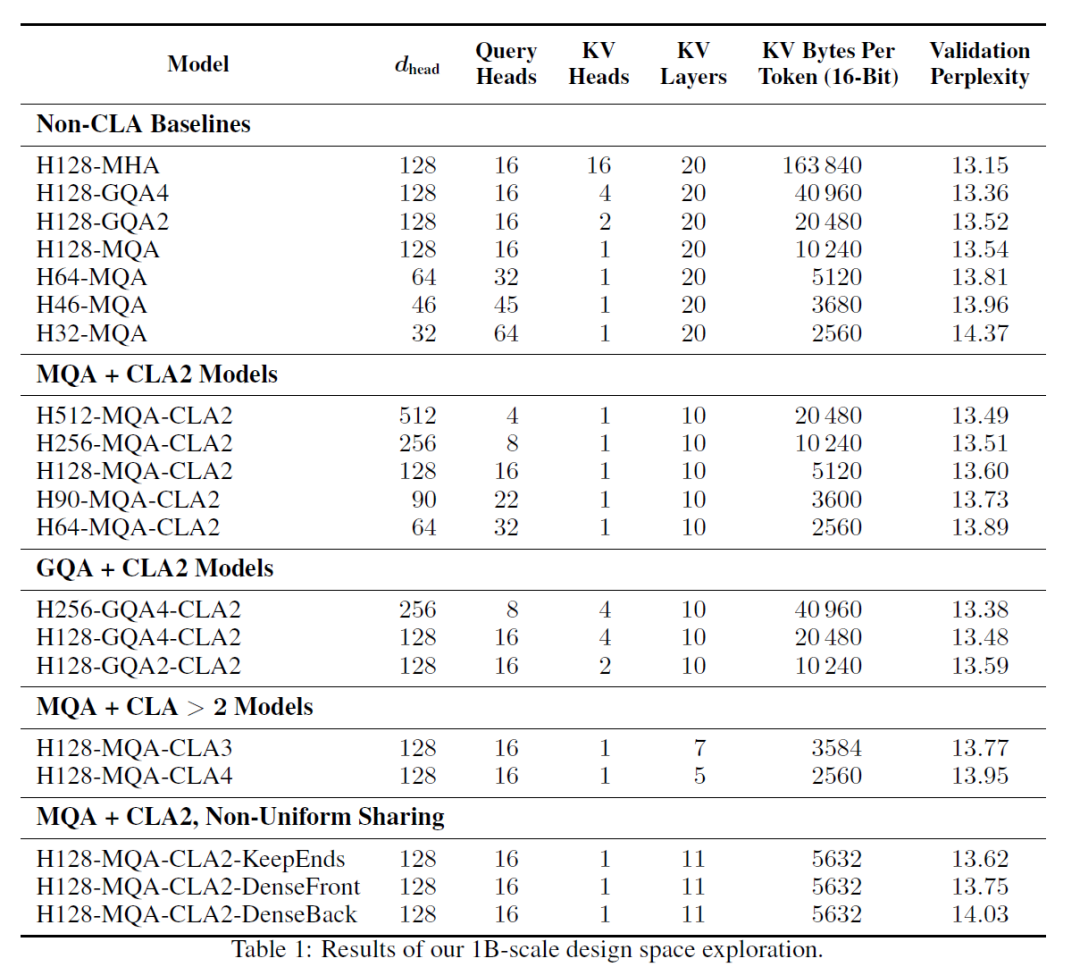
本文主要是介绍「奇思妙想」,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一. main方法可以被其它方法调用吗?
二. 函数和方法真的是一回事吗?
三. 编译型语言VS解释型语言,还有JIT
四. 短路与非短路运算符
五. goto & 循环标签
六. return关键字
七. final关键字
八. 重载和重写的区别
九. 装箱拆箱原理 & 包装类型缓存池(常量池)
十. 注释掉的代码居然还能被执行?
十一. 三种修饰符,四种访问权限
十二. 封装
十三. 多态
十四. 抽象类和接口的异同
十五. Java中的方法冲突
十六. Java到底是值传递还是引用传递{方法的参数传递机制}
编辑
十七. hashCode()到底有什么用,为啥一定要和equals()重写?
十八. 可变参数
十九. 对于小数的处理
二十. 都有常量了,为啥还要用枚举?
二十一. 数组到底是不是对象
二十二. 引用拷贝/浅拷贝/深拷贝
二十三. 为什么要有字符串常量池
二十四. String为什么不可变,有什么好处吗?
二十五. String不可变的弊端?StringBuilder、StringBuffer
二十六. Java中的char为啥占用两个字节?
二十七. 都有数组了,为啥要用集合{容器}?
二十八. 如何选用集合?
一. main方法可以被其它方法调用吗?
- 在C语言中,一个工程内只能声明一个main函数,如果声明多个,则程序无法运行然后报错。
- Java则不同,Java在一个工程内,可以声明多个main方法,但在程序执行时,必须指定一个main方法作为启动入口。
- Java中的main方法是可以被其它方法调用的,Java中的main方法除了当作程序入口,被赋予特殊的意义之外,它本质上还是一个普通的静态方法,因此Java中的main方法是可以被其它方法调用的。
package com.gch.main;public class MainTest {public static void main(String[] args) {A.main(args);B.main(args);}
}class A{public static void main(String[] args) {System.out.println("A...");}
}class B{public static void main(String[] args) {System.out.println("B...");}
}
二. 函数和方法真的是一回事吗?
严格来说,函数和方法本质上都是对一段代码的抽象,但两者的含义却不同:
- 函数英文为Function,它是一个独立的功能,与类和对象无关,需要显式的传递数据。
- 方法英文为Method,它依赖类或者对象,它可以直接处理对象上的数据,也就是隐式的传递数据。
在只支持面向过程的语言中,比如C语言,只有函数没有方法
而Java这种面向对象的语言,所有的方法都得依赖类或者对象,所以只有方法没有函数。
而在Python中,既有函数也有方法。
三. 编译型语言VS解释型语言,还有JIT
高级编程语言,按照程序的执行方式分为两种:一种是编译型语言,一种是解释型语言。
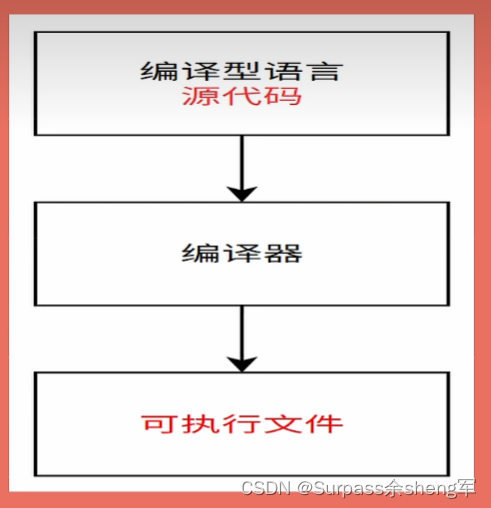
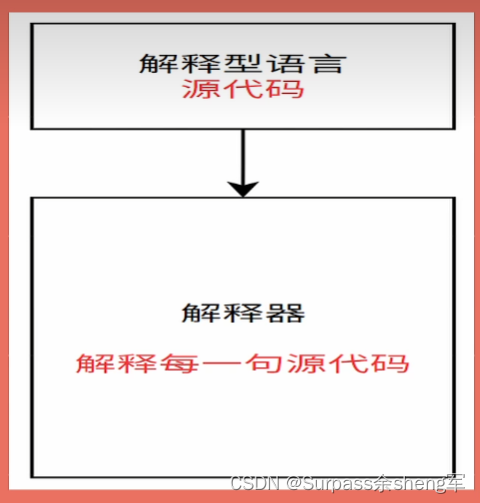
编译型语言:会通过编译器将源代码一次性翻译成机器码之后,然后再让机器执行。一般编译型语言,执行速度比较快,但开发效率比较低,常见的编译型语言有C、C++、Go和Rust。===> 执行前就先行编译
- 特点:源代码中一处有错,就不允许编译
- 简单说,编译型语言是一次性把代码全部翻译好,没问题,才能在机器上执行,所以效率高,但是跨平台性很差,因为是要针对某个机器或者平台先翻译好。
解释型语言:会通过解释器一句一句的将源代码解释成机器码并执行,而不是一次编译全部,边翻译代码边执行。一般解释型语言开发效率比较高,但是执行速度比较慢,常见的解释型语言有Python、JavaScript和PHP都是解释型语言。===> 在执行期才动态解释(解释型语言是将翻译的过程放到执行过程中,这就决定了解释性语言注定要比编译型语言慢上一大截)
- 解释性语言是边翻译代码边执行,翻译到有问题的地方,停止执行,所以效率低,但是跨平台性很好。
- 优点:源代码有错照样能解释执行,遇到错再停下
- 缺点:不断地对源代码进行解释、执行...解释、执行...
这也就是在同样条件下,IOS和安卓APP运行速度有些许差距的原因之一:

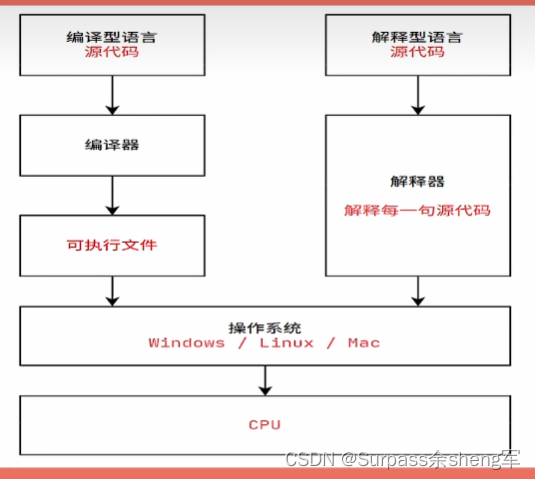
可以发现无论是编译型语言还是解释型语言,都是将源代码翻译成机器码才能执行,其区别在于:一个是执行前就先行编译,一个是在执行期动态解释。
为什么要一定翻译成机器码才能够执行呢?
- 因为计算机只能直接识别和执行特定的指令集,这些指令集就是机器码(机器只能识别0和1);
- 源代码本质上只是一些文本,只有翻译成机器码才算是一个指令或者说一个程序。
为了结合两种类型的优点,发展出了即时编译JIT(Just In Time),让编译与解释并存,Java就是这种类型的代表,Java是编译型+解释型。
- Java之所以是编译与解释并存,是因为它既具有编译型语言的特征,也具有解释性语言的特征,这是怎么做到的呢?
- Java程序会经过先编译后解释这两个步骤,也就是先把源代码编译成字节码(.class文件)---中间语言,到执行期间再将字节码交给Java解释器,翻译成机器码,然后执行。
注意:字节码不是机器码!
四. 短路与非短路运算符
逻辑运算符由 与&& 、或|| 、非!
- 与运算&&和或运算||均为双目运算符,即必须携带两个逻辑值进行运算;
- 非运算符!为单目运算符,即计算单个值。
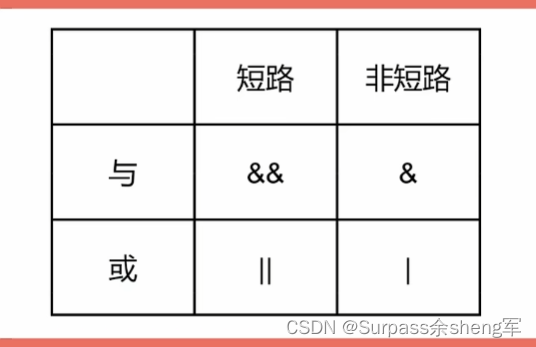
短路和非短路的区别在于:
- 多个表达式结合在一起计算时,若前面的表达式已能得出最终结果,则短路运算就不会计算后面的表达式;
- 而非短路运算则无论如何都会执行所有表达式。
因此我们一般使用短路运算,因为它的效率更高!
五. goto & 循环标签
- continue和break可以改变循环的执行流程,但在多重循环中,这两个语句无法直接从内层循环跳转到外层循环。
- 在一些语言中,比如C,可以通过goto语句实现多重循环的跳转,但在非循环结构中使用goto语句会使程序的结构紊乱,可读性变差
- Java为了防止goto滥用,虽然保留了goto关键字,但这个关键字没有任何作用,然后Java发明了一种带标签的continue和break语句,用来跳出多重循环,实际上它就是一种带限制的,专门用于循环的goto语句
- 通常情况下,我们使用的break和continue语句不带标签,这时就是默认在当前的循环中跳出
- 带标签的循环,实际上就是给这个循环起了个名字,当使用continue或break加上标签时,那就是在标签所在的循环体执行continue或break语句
比如,我在内层循环中使用break,那此时内层循环会停止执行,然后执行下一轮外层循环;
当我使用break + 外层标签,那此时外层循环便会直接终止。

示例:猜数字游戏 OUT标签结束外部死循环

package com.demo;import java.util.Random;
import java.util.Scanner;public class Test3 {public static void main(String[] args) {// 如何动态的给数组赋值?//需求:5个1-20之间的随机数,让用户猜测,猜中要提示猜中,还要输出该数据在数组中第一次出现的索引,//并打印数组的内容出来,没有猜中则继续猜测//1.定义一个动态初始化的数组存储5个随机的1-20之间的数据int [] data = new int[5];//2.动态的生成5个1-20之间的随机数并存入数组中去Random r = new Random();for(int i = 0;i< data.length; i++){//i = 0 1 2 3 4data[i] = r.nextInt(20)+1;}//3.使用一个死循环让用户进行猜测Scanner sc = new Scanner(System.in);OUT:while(true){System.out.println("请您随机输入一个1-20之间的整数进行猜测:");int guessData = sc.nextInt();//4.遍历数组中的每个数据,看是否有数据与猜测的数据相同,相同代表猜中了,给出提示for(int i = 0;i < data.length;i++){if(data[i] == guessData){System.out.println("恭喜您猜中了该数据,运气不错哦!您猜中数据的索引是:"+i);break OUT; //代表着结束了整个死循环!!代表游戏结束了}}System.out.println("您当前猜测的数据在数组中不存在,请重新猜测!!!");}//5.输出数组的全部元素,让用户看到自己确实是猜中了某个数据!//遍历数组for(int i = 0;i < data.length;i++){System.out.print(data[i]+"\t");}}
}
六. return关键字
return语句是作用于方法,用来结束整个方法体。
- return可以单独被调用,用于没有返回值的方法;
- 也可以携带一个值,用于有返回值的方法;
- 如果将return语句放在循环体内,表示直接结束循环,但是要注意,用return结束循环,循环体后面的语句不会被执行。
七. final关键字
- 如果用final来修饰类,则表示这个类不能被继承;
- 如果用final来修饰方法,则表示这个方法不能被子类重写;
- 如果用final修饰变量,则该变量的值在赋值后便无法被修改,无论是成员变量、静态变量还是局部变量都是如此。
注意:如果修饰的是引用类型,则代表该引用只有一次指向对象的机会,即不能变更变量所指向的对象,但是对象的成员属性是可以修改的。
八. 重载和重写的区别
方法的重载,英文为Overloading:是指在一个类中定义相同名字但参数不同的多个方法,调用时会根据不同的参数表达来选择对应的方法。
- 重载方法可以修改返回类型,也可以修改访问权限。
- 简而言之,只要能区分够开来方法,不会造成混淆,则构成重载。
方法的重写,英文为Override:是指子类覆盖父类的方法逻辑,子类的重写方法必须和父类的被重写方法具有相同的方法名称、参数列表和返回值类型,并且重写方法不能使用比被重写方法更严格的访问权限(private < protected < 缺省 < public)。

九. Java真的一切皆对象吗?
- Java是一门面向对象的语言,在Java世界当中,万物皆对象,这种思想是Java语言的基石和核心,Java一切的特性和设计都是围绕面向对象进行的,但是在Java设计之初,却创造了一个例外,那就是基本数据类型,这八种基本数据类型不是对象,任何和对象相关的特性对它们都无效。
验证:我们知道所有的对象都继承自Object顶层父类,都从Object类中继承过来了几个方法,比如toString(),创建任意一个Java对象,都能调用其toString()方法,然而基本类型却无法调用,这一点就可以得知:基本数据类型确实不是对象。

Java为了实现一切皆对象,因此有了包装类。
- Java为每一个基本数据类型都创造了与之对应的类,从而让基本数据类型可以转换为对象,这些类称之为包装类。
- 基本类型和包装类型互相转换的过程就称之为装箱和拆箱,装箱、拆箱无需我们手动进行,Java会自动帮我们做好。
- 将基本类型赋值给包装类型,就完成了自动装箱;将包装类型赋值给基本类型就完成了自动拆箱。
- 至此,基本类型便可以转换为普通的对象,进而拥有了对象的一切特性。

九. 装箱拆箱原理 & 包装类型缓存池(常量池)
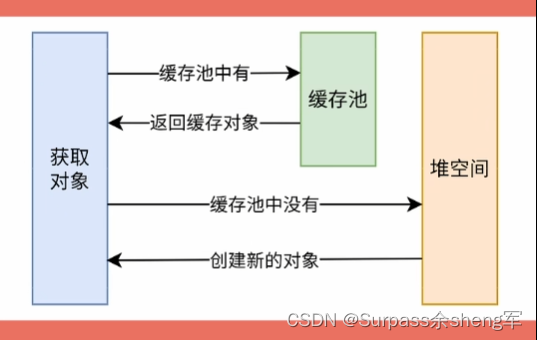
包装类型缓存池(常量池):它是事先存储一些常用数据 => 用以提高性能,节省空间的一种技术。大部分的包装类型都实现了缓存池,当我们在自动装箱时,如果基本数据类型的值处在缓存范围内,则不会重新创建对象,而是复用缓存池中已事先创建好的对象。

Integer默认缓存了[-128,+127] 范围的值,只要是这个范围的值自动装箱,便会返回相同的对象,所以如果是包装类型互相比较的话, 不要用==判断,而要用equals()方法判断,不同的包装类缓存的范围不同。

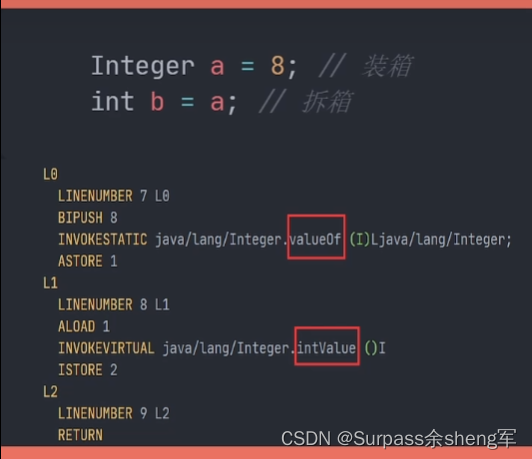
自动装箱和自动拆箱的原理:
查看自动装箱或自动拆箱的字节码时便可以发现:
- 自动装箱实际上是调用了包装类型的valueOf()方法
- 自动拆箱实际上是调用了xxxValue()方法。xxx => 基本类型
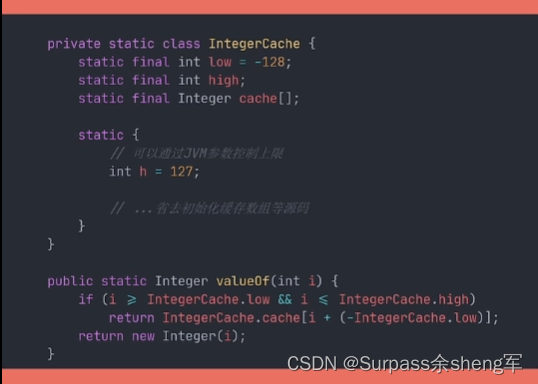
原理搞清楚后我们可以发现,在创建包装类对象时,要么使用自动装箱,要么尽量使用valueOf()方法,而不要直接new,因为valueOf()方法利用了缓存,而直接new是直接创建对象,没有利用缓存。

十. 注释掉的代码居然还能被执行?
注释是编程语言中一个重要的组成部分,用来在源代码中解释代码的功能,可以增强程序的可读性、可维护性。
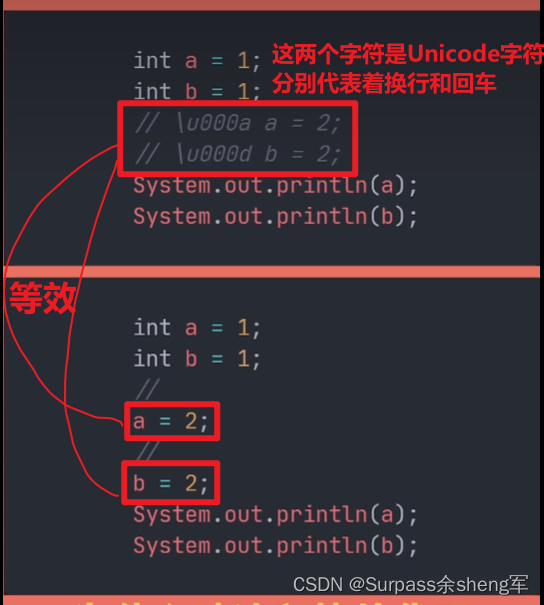
Java源代码允许包含Unicode字符,并且在任何词汇翻译之前,就会对Unicode进行解码
刚才被注释掉的代码就是在被Unicode解码后发生了换行和回车,自然而然就被执行了。
十一. 三种修饰符,四种访问权限
Java中的访问修饰符,用来控制类、静态变量、静态方法、成员变量、成员方法的访问权限。
在Java中有三种访问修饰符,四种访问权限:
- public是最大权限,代表可以被任意访问
- priavte是最小权限,代表只能由当前类访问,只能由类自己访问
- 我们经常将成员变量设置为private,然后选择性的提供public方法以供外部访问成员变量。
- protected权限:被protected修饰符修饰的成员变量或者方法,表示对相同包和其子类可见,protected多用于父类定义好方法模板,供子类去实现自己的逻辑,设计模式中的模板方法就可以通过protected来实现。
- 默认权限:默认权限没有对应的权限修饰符,当变量或方法没有被权限修饰符修饰的时候,就属于默认权限。默认权限表示对相同包内可见,默认权限用的比较少,我们在声明变量和方法时,一般都会指定具体的修饰符。
注意:接口的方法只能使用public权限,并且接口中的方法默认就使用public权限修饰符,哪怕接口中的方法省去了权限修饰符,依然是public权限。
对于类来说只可以使用public权限和默认权限,一个Java文件中只能有一个public类!
十二. 封装
封装说白了,就是隐藏细节!
生活中的封装:
- 你到银行取钱,你只需要提供卡号和密码,柜员就会将现金取给你,至于柜员是在柜台后面如何验证你的密码、余额,又是如何拿到现金给你,你都不知道也无需知道,这就是封装,银行封装了柜员在柜台后面的操作细节。
- 再比如你到餐厅去吃饭,你点好菜之后,只需要等待服务员将菜端上来给你,而不用关心这个菜是如何做好的,这也是封装,餐厅封装了厨师在厨房里面做菜的细节。
程序中的封装:
- 调用库中的某个方法,传入正确的参数,即可让方法运行达到你想要的结果,至于方法内部进行了怎样的操作,你不知道也无需知道,这不就是封装吗?方法封装了算法的细节。

对于对象的成员变量来说,访问权限就是封装的一种体现,比如我们经常用private来修饰成员变量,然后选择性的提供public方法以供外部访问成员变量。
提问:为什么要通过封装好的set和get方法来操作成员变量呢?
- 可以对成员进行更精准的控制,让成员变量和调用者解耦,类内部的结构和实现可以自由修改,同时也能保证数据的安全性、有效性。

十三. 多态
多态:当父类的引用指向子类的对象时,调用的方法是子类重写后的方法,既体现了多种类型的传递,又体现了不同类型的特性,既复用了父类的属性和方法,又扩展了自己的逻辑。
开闭原则:对修改关闭,对扩展开放!
十四. 抽象类和接口的异同

抽象类和接口都是为了将方法进行抽象,然后让子类去实现,所以可以定义抽象方法,这就是两者第一个相同点,第二个相同点不能创建本类对象,只能由子类去实例化子类对象。

- 抽象类可以去实现接口,而接口只能继承接口,并且接口可以继承多个接口,但接口不能继承类。
- 类单继承(extends),接口多实现(implements)!
- 所以,当我们发现既可以使用抽象类也可以使用接口时,我们尽量去选择接口,这样子类的灵活度会更高。
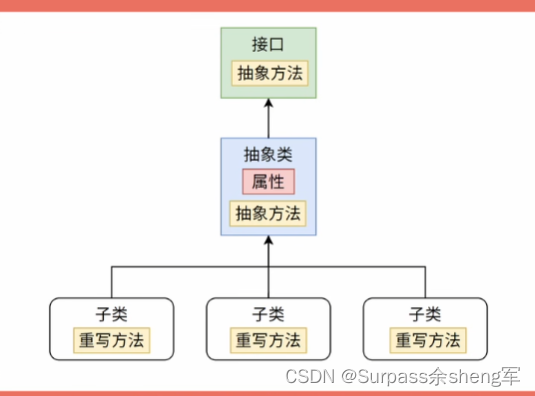
- 抽象类更进一步的抽象后,就诞生了接口
- 接口比抽象类更纯粹,因为它没有了成员属性,只有方法,子类实现接口后,唯一能做的就是重写方法
- 不像抽象类,子类继承抽象类之后,连带着将父类的成员属性也继承过来了,这里就是两者的又一差异点,抽象类可以定义成员属性,而接口不能定义成员属性,只能定义静态属性,而且只能用final关键字定义静态常量,不能定义静态变量,接口除了没有成员属性外,还没有构造器,可以说是非常纯粹了,说白了接口就是一个只有抽象方法和静态常量的类。
抽象类都不能被实例化,还要构造器有啥用呢?
- 它的用处就是限定子类的构造行为,比如抽象类可以将构造器定义好几个参数,子类要想实例化则必须想办法传入这几个参数才行。

什么时候该用抽象类,什么时候该用接口呢?
- 其实很好判断,当你需要让子类继承成员变量或者需要控制子类的实例化时,你就用抽象类;
- 否则,你就用接口。

=> 接口是更加纯粹的抽象类,纯粹就代表着精简,接口比抽象类少了成员属性和构造器,只留下 了静态常量和抽象方法,更能体现标准和规范的含义,这也是我们经常说要面向接口开发。
十五. Java中的方法冲突

- 我们知道,子类最多只能继承一个父类,但可以实现多个接口,自Java8起,接口可以定义静态方法,也可以用defalut关键字实现方法逻辑。
此时问题来了,如果一个子类实现了多个接口,这些接口中都有相同签名的方法实现,那子类调用方法时,会调用哪一个呢?
- 这就是方法冲突,虽然在日常开发中发生冲突的概率很小,但我们不能不知道解决方案。
如果发生了方法冲突,Java会调用优先级最高的方法,哪些优先级高呢?
一句话概括:
- 类的优先级比接口高,子类的优先级比父类高
- 说白了越具体的越优先,越抽象或者离本类越远的优先级就越低
1. 比如你继承了一个类同时实现了一个接口,那就会优先调用类的方法;
2. 如果你实现了好几个接口,这些接口中有一个是子接口,则会优先调用子接口的方法;
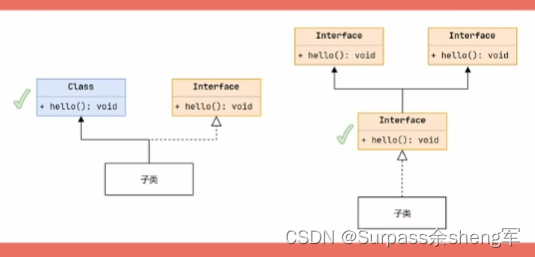
3. 如果都是相同优先级,无法分出高低时,那本类就必须重写方法,来显式的选择指定方法实 现,如果不指定,那就会编译报错。
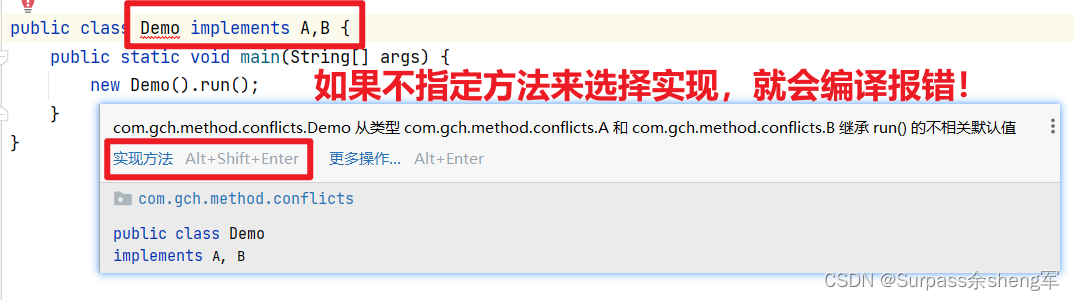
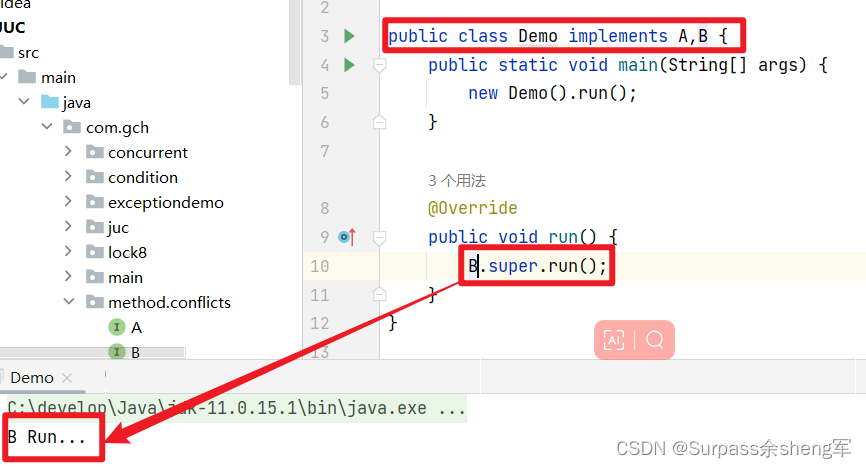
语法如图所示:父类名接上super关键字再接上方法,这是固定的语法格式

代码演示:
package com.gch.method.conflicts;public interface A {default void run() {System.out.println("A Run...");}
}
package com.gch.method.conflicts;public interface B {default void run(){System.out.println("B Run...");}
}
package com.gch.method.conflicts;public class Demo implements A,B {public static void main(String[] args) {new Demo().run();}@Overridepublic void run() {A.super.run();}
}
十六. static关键字的四种用法

静态属性、静态方法:
- 在定义属性或方法时,加上static关键字就代表将其声明为静态属性和静态方法,不用创建对象,直接通过类名就可以调用静态的属性和方法。
- 静态属性和静态方法与之对应的是成员属性和成员方法
- 静态的属于类,成员的属于对象
- 成员方法中既可以访问成员属性,也可以访问静态属性。
- 静态方法中却只能访问静态属性,不能访问成员属性。
- 每创建一个对象实例就会随之创建一份成员属性,每个对象的成员属性都各自独立,互不影响,而静态的属性和方法是属于这个类的,在当前程序中只存在一份,并且还没有对象创建时,它就存在了,所以它又怎么可能访问得了后面创建出来得成员属性呢? 因为这个类就这么独一份,它不会像对象一样,可以随时地动态的去创建,
静态代码块:
- 在类中还可以用static关键字来修饰静态代码块
- 静态代码块会在类初始化时运行一次,而普通代码块则是每个对象创建时运行一次。
package com.gch.staticdemo;public class A {/**静态代码块{在类初始化时执行一次}*/static{System.out.println("静态代码块");}/**普通代码块{每个对象创建时执行一次}*/{System.out.println("普通代码块");}/**主函数*/public static void main(String[] args) {// 静态代码块执行一次,普通代码块执行两次new A();new A();}
}

初始化顺序:
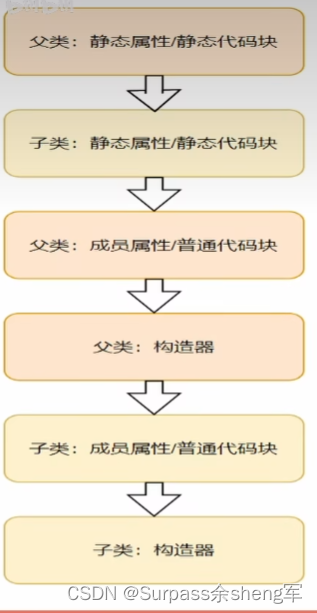
静态属性和静态代码块肯定是要优先于成员属性和普通代码块=>毕竟先有类,然后再有对象,最后才是构造器的初始化。如果有继承关系在,自然是父类优先于子类。
package com.gch.staticdemo;public class Demo {/**静态代码块{在类初始化时执行一次}*/static{System.out.println("静态代码块...");}/**普通代码块{每个对象创建时执行一次}*/{System.out.println("普通代码块...");}/**无参构造器{构造器最后才执行}*/public Demo(){System.out.println("无参构造器...");}/**主函数*/public static void main(String[] args) {// 本段代码的执行顺序:静态代码块 => 普通代码块 => 构造器new Demo();}
}
静态导包:
- 在导包的时候,可以加上static关键字,这样在引用类时可以省去类名,从而简化代码。
package com.gch.staticdemo;import static java.util.concurrent.TimeUnit.MINUTES;
import static java.util.concurrent.TimeUnit.SECONDS;public class Test {public static void main(String[] args) throws InterruptedException {SECONDS.sleep(1);MINUTES.sleep(2);}
}
十六. 四种内部类
内部类,顾名思义就是在一个类的内部定义的类。
不同类型的类,其区别就是作用范围不同,你的类定义在哪,作用范围就是哪。
- Java中常规的类通常是建立在各个包下面,定义这些常规的类时,可以选择加public关键字或者不加。
- 加了public关键字就代表这个这个类可以在本程序任何地方访问;不加则代表只能在这个类所处的包下访问。
- 你这个类能被哪些地方访问,就代表你这个类的作用范围有多大。
- 常规类的作用范围在整个程序或者某个包下,内部类的作用范围就看它定义在哪。
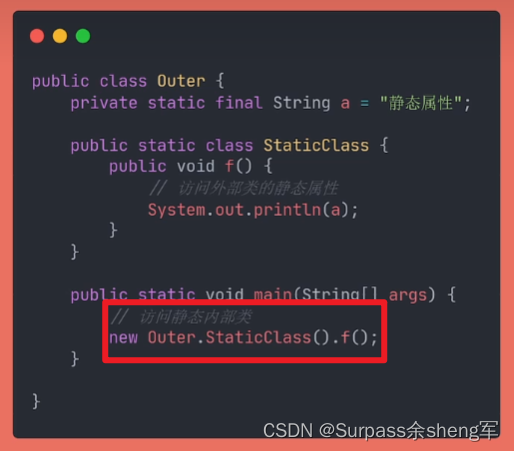
静态内部类:
和静态属性相关,它和静态属性一样,被static关键字修饰,作用范围也和静态属性一样, 静态内部类能够任意访问外部类的静态属性。
成员内部类:
- 和成员属性相关,它和成员属性一样,你怎样定义成员属性,就怎样定义成员内部类
- 对外来说,通过外部类的对象实例就能访问该对象的成员属性,也能访问该对象的成员内部类
- 对内来说,成员内部类能够任意访问外部类的成员属性

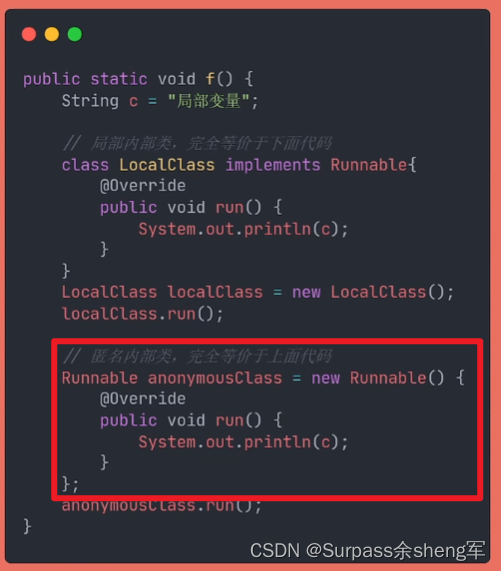
局部内部类:
- 局部变量是定义在方法里面,局部内部类当然也是定义在方法里面了。
- 对外来说,就只有该方法内能调用局部内部类;
- 对内来说,局部内部类可以任意访问该方法内的局部变量。

匿名内部类:
- 其实就是局部内部类的一种简要写法,可以在不声明类名的情况下,继承其它类并创建对象,它的作用范围和局部内部类完全一致。
注意:作用范围可以从内往外访问,不能从外往内访问。
比如:局部内部类可以访问静态属性或静态内部类,但静态内部类可访问不了局部内部类。
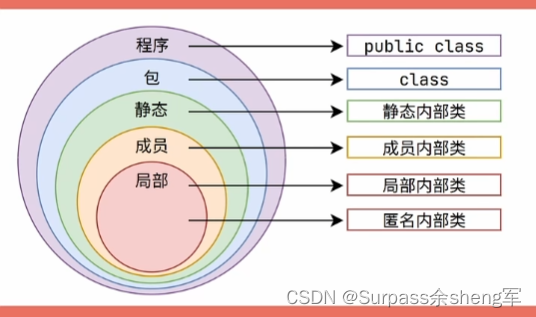
静态内部类和匿名内部类用的比较多。
十六. Java烂设计之Date
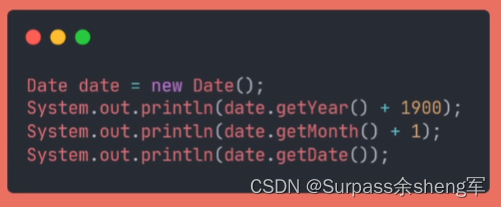
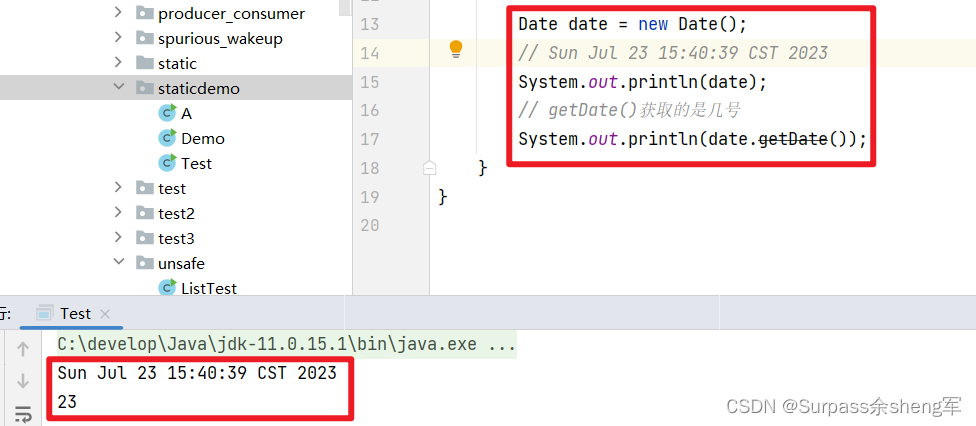
Date和简单日期格式化类SimpleDateFormat类都是线程不安全的。
十六. Java到底是值传递还是引用传递{方法的参数传递机制}
Java只有值传递,没有引用传递。
区分实参和形参:
- 实参:就是我们要传递给方法的实际参数。实参是在方法内部定义的变量。
- 形参:就是我们方法签名上定义的参数。 形参是在定义方法时,()中所声明的参数,形参它是用来接数据的。
无论是基本数据类型的参数还是引用数据类型的参数,都是满足值传递:
- 基本类型的参数传输的是存储的数据值
- 引用类型的参数传输的是存储的地址值

十七. hashCode()到底有什么用,为啥一定要和equals()重写?
- hashCode()和equals()方法一样,都是定义在Object顶层父类中,子类可以进行重写。
- hashCode()方法是Native方法,如果没有重写,通常会将内存地址转化为int数值进行返回。
- 每个对象都有自己的哈希值,因为每个对象都有自己的内存地址。
- 我们用hashCode()方法获取到的这个int数值就是哈希码,也叫散列码,它的作用就是确定对象在哈希表中的索引位置。
- 哈希算法:根据元素的哈希值对数组长度秋雨计算出应存入的位置。
- 只要搞懂了哈希表的机制,也就能搞懂hashCode()方法了。
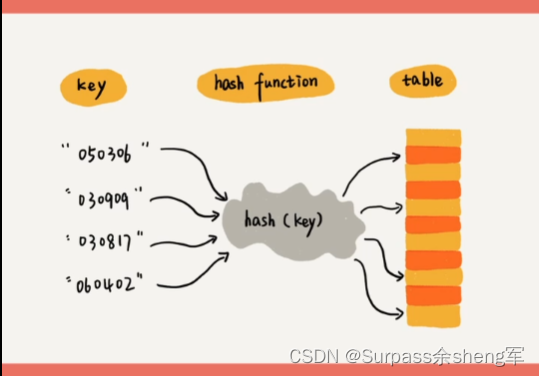
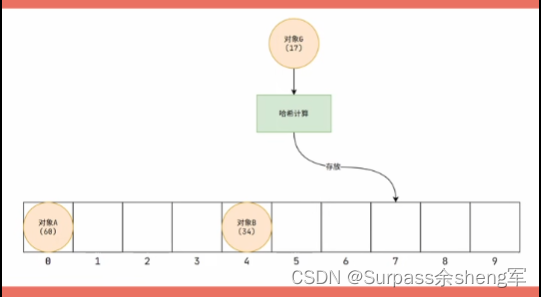
- 假设现在有这么一批需求,我想让一批对象能够存储起来,不允许存储重复的对象,并且能够随时获取对象。
- 一说起存储,我们自然就想到了数组,我们可以将对象挨个放在数组中,当判断对象是否重复存储时或者获取指定对象时, 我们每次都得从头开始遍历数组,挨个和数组中的对象进行equals()比较,equals()结果为真,就代表找到了指定对象。这样确实满足了需求,但有一个问题就是效率太低了,每次都得遍历整个数组,假设数组中有一万个对象,那每次操作我都得比较一万次,此时时间复杂度为O(n),有没有办法提高效率呢?
- 这时候通过hashCode()获取到的哈希码就派上用场了,我们在存放对象时可以通过哈希码来对数组长度取余,这样就能得到元素在数组中要存放的索引位置。
- 比如:数组长度为10,对象的哈希码为17,那17 % 10 = 7, 我们就可以将这个对象存放到下标7的位置上,这样无论是存储元素,还是获取元素,通过数组下标就只用操作一次,时间复杂度为O(1)。===> 哈希码的作用:确定索引位置,就能大幅度的提高效率。
- 不过现在还有一个问题,那就是哈希码是可能会重复的,毕竟哈希码只是通过一定的逻辑计算出来的int数值,两个不同的对象完全有可能哈希码会相同,这就是我们常说的哈希冲突 =>
- 当要存储的对象和已经存储的对象发生哈希冲突时,我们首先要做的就是判断这两个对象是否相等,如果相等就算作是重复元素,我就不用存储了;如果不相等,那我再将新对象想别的办法存起来。
那两个哈希冲突的对象该怎样判断相等呢?
- 当让是用equals()方法了,所以hashCode()方法和equals()方法要同时重写。
- 因为hashCode()方法用来定义索引位置,以提高效率的同时可能会发生哈希冲突,当哈希冲突时,我们就要通过equals()方法来判断冲突的对象是否相等,如果只重写了hashCode()方法,那哈希冲突发生时,即使两个对象相等,也不会被判定为重复,进而导致数组里会存储一大堆重复对象。如果只重写了equals()方法,那两个相等的对象内存地址可不会相等,这样还是会造成重复元素的问题,所以两个方法最好一起重写。
总结:
- hashCode()方法用来在最快时间内判断两个对象是否相等,并定位索引位置,不过可能会出现误差。
- equals()方法用来判断两个对象是否绝对相等。
- hashCode()方法用来保证性能,equals()方法用来保证可靠。
十八. this{本类对象} & super{当前类对象}
this:
- 指定当前类对象的成员属性、成员方法;
- 直接使用this()就代表调用本类的构造方法,这种方式用在构造方法中可以复用其它构造方法的逻辑,比如这段代码中最顶层的构造器已经完成了属性的赋值逻辑,其它构造方法就没必要再写重复的赋值逻辑了,直接传值就好。
package com.gch.thisdemo;/**目标:掌握this()用法:表示调用本类的构造方法*/
public class Person {private String name;private int age;/**有参构造器:已经完成了参数的赋值逻辑*/public Person(String name,int age){this.name = name;this.age = age;}/**无参构造器*/public Person(){this("有参",18);}public Person(String name){this(name,18);}public Person(int age){this("匿名",age);}public static void main(String[] args) {System.out.println(new Person(23));}
}

注意:
- 子类会默认调用父类的无参构造器!
- 在被static修饰的地方是调用不了super和this的,因为这两者都和对象相关。
十八. 可变参数
写main方法时,可以将参数声明为数组[ ],也可以声明为可变参数 ... , 两种方法都可以正常运行。

- 可变参数也叫不定长参数,当我们不确定要接收的参数个数时,就可以用...来声明可变参数,它可以接收0个或多个实参。
- 在方法内部可变参数的使用方式和数组完全一致,所以在声明方法时,完全可以将可变参数声明为数组,这也是为什么main方法的两种参数声明方式都可以正常运行。
- 不过声明数组的话,调用方法时,需要自己先构造/构建数组才行,比较麻烦,并且调用方还可以传入null给数组(空指针异常=>NullPointerException);
- 而可变参数当你不传参时,可变参数就会默认构造一个空数组而不是null。
- 可变参数前面可以声明也可以不声明其它参数,但必须得保证可变参数是方法的最后一个参数,负责会编译失败;并且一个形参列表中只能有一个可变参数。

package com.gch.variableparameter;/*** 可变参数{不定长参数}:用于在形参中接收0个或多个参数,也可以接收以一个数组* 可变参数的格式:数据类型...参数名称* 可变参数在方法内部本质上就是一个数组* 一个形参列表中只能有一个可变参数,并且可变参数必须放在形参列表的最后面*/
public class Test {public static void main(String...args) {// ---------- 方法参数为 => 可变参数 -------------// 可以不传参{可变参数会默认构造一个空数组而不是null}printName();// 也可以传一个或多个参数printName("张三");printName("张三","李四");// ---------- 方法参数为 => 数组 -----------// 可以传null,但是运行会报错:java.lang.NullPointerException// printNames(null); 错误的做法// 因此,当方法参数为数组时,在传入实参必须要构建数组// 哪怕没有元素,也必须要构建数组{空数组}printNames(new String[]{}); printNames(new String[]{"张三"});printNames(new String[]{"张三","李四"});}/*** @param names => 可变参数*/public static void printName(String...names){for (String name : names) {System.out.println(name + " ");}}/*** @param names => 数组*/public static void printNames(String[] names){for (String name : names) {System.out.println(name + " ");}}
}
注意:当方法重载时,会优先匹配固定参数的方法,因为固定参数更为确定,匹配度更高。
package com.gch.variableparameter;/**当方法重载时,会优先匹配固定参数的方法,因为固定参数更为确定,匹配度更高!*/
public class Demo {public static void main(String[] args) {printNames("张三");printNames("张三","李四");printNames("张三","李四");printNames("张三","李四","王五");}/*** 方法形参为一个固定参数* @param name*/public static void printNames(String name){System.out.println("方法1");}/*** 方法形参为两个固定参数* @param name1* @param name2*/public static void printNames(String name1,String name2){System.out.println("方法2");}/*** 方法形参为可变参数* @param names*/public static void printNames(String...names){System.out.println("方法3");}
}

十九. 对于小数的处理
package com.gch.bigdecimal;import java.math.BigDecimal;public class Demo {public static void main(String[] args) {
// 很多系统都有处理金额的需求,比如电商系统、财务系统等,float和double处理浮点数会造成精度丢失double money = 1 - 0.9;// 0.09999999999999998System.out.println(money);// 为什么用float和double处理浮点数会造成精度丢失呢?// 出现这个现象是因为计算机底层是二进制运算,而二进制并不能准确表示十进制小数// 所以在商业计算等精确计算中,要使用其它数据类型来保证精度不丢失,一定不能使用浮点数// Java标准库中的BigDecimal类就可以用来精确计算小数// 要创建BigDecimal主要有三种方式 => 前面两个是构造方法,最后一个是静态方法// Alibaba开发规约规定:// 推荐入参为String的构造方法或使用BigDecimal的valueOf(),// 禁止使用构造方法BigDecimal(double)的方式把double值转化为BigDecimal对象// BigDecimal(double)存在精度损失风险,在精确计算或值比较的场景中可能会导致业务逻辑异常// 0.1000000000000000055511151231257827021181583404541015625System.out.println(new BigDecimal(0.1));// 0.1System.out.println(new BigDecimal("0.1"));// 包装浮点数成为BigDecimal对象 => 0.1System.out.println(BigDecimal.valueOf(0.1));System.out.println("----------------------------------------");// BigDecimal两种构建对象方法的比较// 利用BigDecimal的静态方法构建对象,其中equals()不会比较精度BigDecimal d1 = BigDecimal.valueOf(0.33);BigDecimal d2 = BigDecimal.valueOf(0.3300);// trueSystem.out.println(d1.equals(d2));// BigDecimal的入参为String的构造方法的equals()不光会比较值,还会比较精度// 就算值一样,但精度不一样,结果也为falseBigDecimal d3 = new BigDecimal("0.33");BigDecimal d4 = new BigDecimal("0.3300");// falseSystem.out.println(d3.equals(d4));// 所以利用入参为String的构造方法构建的BigDecimal对象// 要比较值是否相等时,需要使用它的compareTo()方法// 被比较的值更大,会返回1;被比较的值更小,会返回-1;两个值相等,则会返回0// 0System.out.println(d3.compareTo(d4));}
}
注意:
- BigDecimal是不可变对象,意思就是加减乘除这些操作都不会改变原有对象的值,方法执行完毕,只会返回一个新的对象,若要获取运算的结果,只能重新赋值。

二十. 都有常量了,为啥还要用枚举?
当我们需要使用一些固定不变的数据时,就可以将其声明为静态常量,以方便复用。
- 比如我要定义春夏秋冬四季,就可以用int数值表示,当然也可以用字符串等其它类型表示。
package com.gch.enumdemo;public class Season {/** 春 */public static final int SPRING = 1;/** 夏 */public static final int SUMMER = 2;/** 秋 */public static final int AUTUMN = 3;/** 冬 */public static final int WINTER = 4;
}
- 静态常量定义好后,直接通过类名便可以调用。
public static void main(String[] args) {System.out.println(Season.SPRING);System.out.println(Season.SUMMER);System.out.println(Season.AUTUMN);System.out.println(Season.WINTER);}尽管静态常量使用起来很方便,不过有些时候会带来一些问题:
- 比如你定义一个方法用来接收四季的数值,然后根据不同数值执行不同的逻辑,此时你会发现你没有办法限制调用者传什么值进来,它可以按照常量的范围传递1234,也可以传递5678,最主要的是你没有办法有效的让调用者直观感受应该传什么值,毕竟你的参数只是int类型,就代表只要传递int数值就是合法的,当然你可以在方法注释上写清楚数字范围,也可以说明要用常量,还可以对意外数值进行逻辑处理,但这些做法都增加了调用者的心智负担,并不是一个好的设计。
/*** 只能传递1-4* 可以使用Season常量* @param season 四季分别代表的int数值*/public static void f(int season){switch(season){case 1:// 春天逻辑...break;case 2:// 夏天逻辑break;case 3:// 秋天逻辑break;case 4:// 冬天逻辑break;default:// 处理意外数值}}public static void main(String[] args) {f(Season.SPRING);f(Season.SUMMER);f(3);f(4);f(5);f(-100);}为了更好的提示调用者或者说更好的限制调用者,我们可以改进一下:
- 我们将之前的int常量改为自定义的季节类型
- 同时将类声明为final,以防继承
- 构造方法声明为private,以防止外部实例化
这样我就能保证在程序内季节类型的对象只会有这几个常量,然后方法参数就可以改为季节类型了,这样调用者就只能传递你定义好的常量, 他最多只能额外传递一个null值,要是传别的类型,编译器就会直接报错。我们通过这种设计就做到了在没有任何额外说明和额外逻辑的情况下限制住了调用者传递的内容,对于调用者来说,他也能非常直观的理解这个方法的参数限制。
恭喜你,你已经发明了枚举,这种设计就是枚举的原理,我们可以使用枚举更方便的来满足之前的操作!
package com.gch.enumdemo;
/**自定义枚举*//** 将类声明为final,以防继承 */
public final class Season {/** 春 */public static final Season SPRING = new Season();/** 夏 */public static final Season SUMMER = new Season();/** 秋 */public static final Season AUTUMN = new Season();/** 冬 */public static final Season WINTER = new Season();/** 构造器私有,以防止外部实例化 */private Season(){}
}
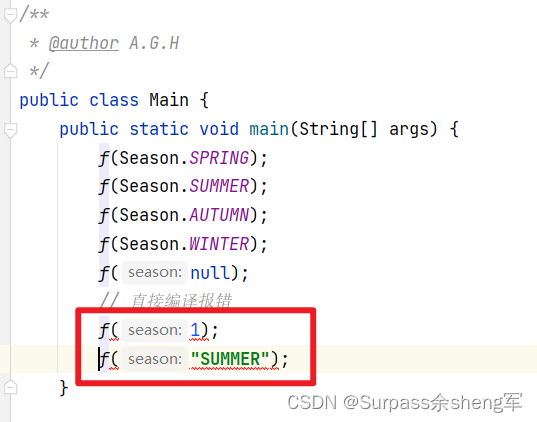
package com.gch.enumdemo;/*** @author A.G.H*/
public class Main {public static void main(String[] args) {f(Season.SPRING);f(Season.SUMMER);f(Season.AUTUMN);f(Season.WINTER);f(null);// 直接编译报错
// f(1);
// f("SUMMER");}/*** @param season 方法参数为Season类型*/public static void f(Season season){}
}
在Java中enum关键字来声明枚举,然后就可以直接定义枚举值了,调用时和静态常量一样都非常方便,同时枚举本身就是一种类型,所以天然的就限制了调用者能够传递的数据类型,并且枚举值还可以使用switch来判断,更加方便。
package com.gch;/**定义enum枚举类*/
public enum Season {/** 春 */SPRING,/** 夏 */SUMMER,/** 秋 */AUTUMN,/** 冬 */WINTER;
}
package com.gch;/**Java中的枚举*/
public class Main {public static void main(String[] args) {f(Season.SPRING);f(Season.SUMMER);f(Season.AUTUMN);f(Season.WINTER);// 传null值运行时会报空指针异常=>java.lang.NullPointerExceptionf(null);// 编译器会直接报错
// f("SUMMER");
// f(1);}/*** @param season 参数类型为enum类Season*/public static void f(Season season){switch(season){case SPRING:break;case SUMMER:break;case AUTUMN:break;case WINTER:break;}}
}
将枚举反编译后就可以发现和我们之前的设计基本一致,和普通的class类也没啥区别,只是它继承了Enum父类,并从父类中继承下来了一些方法可供使用。
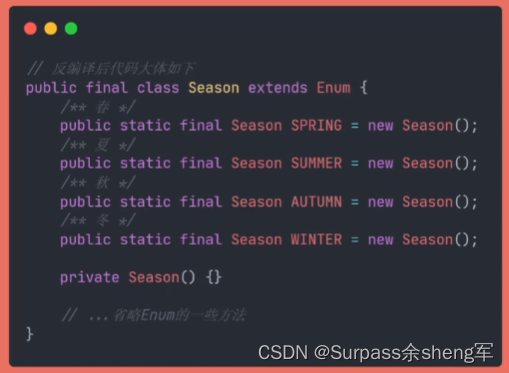
这里要注意:Enum父类我们无法手动继承,只能用enum关键字来定义枚举,这是Java的语法规定。
总结:
- 枚举能够更好的帮助我们限定语义,能够在编译阶段就检查每个值的合理性,并且可以用于switch判断,以及自带了多个方法提供使用,比普通的常量更加方便。
- 当然,并不是说必须使用得枚举, 常量下在许多场景下都非常合适,根据自己的实际情况来选择即可。
二十一. 数组到底是不是对象
在Java语言规范中明确说明,数组就是对象:

请你来验证数组是对象:
- 首先,数组有自己的字段和方法,也能调用所有的Object方法
- 用instanceof关键字也能看出数组是一个Object
- 将数组直接赋值给Object也没问题。
package com.gch.array;public class Demo {public static void main(String[] args) {int[] arr = new int[5];// trueSystem.out.println(arr instanceof Object);Object o = arr;}
}
我们知道对象都是引用类型,对象本身创建在对堆中,变量拿到只是对象的引用地址,所以如果两个变量指向的是同一个数组,那么只要其中有一个变量修改了数组中的值,另一个变量也能观察到数组数据的变化。
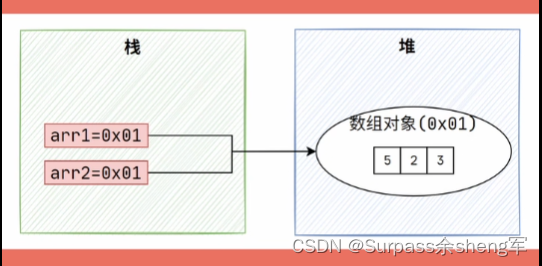
package com.gch.array;public class Demo {public static void main(String[] args) {int[] arr1 = new int[]{1,2,3};// 引用传递 => 传递的是数组的地址值int[] arr2 = arr1;arr2[0] = 5;// 5System.out.println(arr1[0]);}
}
注意:
- 数组对象是由JVM直接创建的,并不是通过某个类来实例化,除了Object外,数组并不是类体系树中任何类的实例,这是数组区别于普通对象的一个点。
- 在reflect包下有一个Array类,这只是一个数组相关的工具类,并不是数组类型。
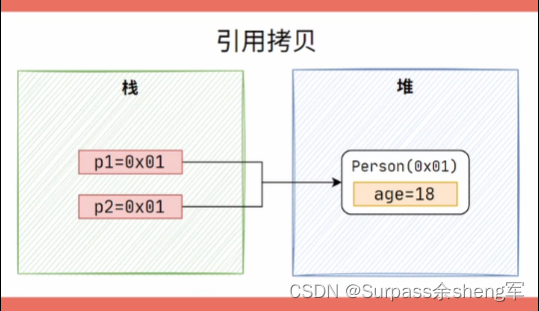
二十二. 引用拷贝/浅拷贝/深拷贝
- 当我们想复制一个对象时,最自然的操作就是直接赋值给另一个变量,这种做法只是复制了对象的地址,即两个变量指向了同一个对象,任意一个变量操作了对象的属性,都会影响到另一个变量。
- 这种对同一个对象的操作,当然算不上真正的复制,所以引用拷贝并不算对象拷贝,我们聊的对象拷贝一般就是指浅拷贝和深拷贝。
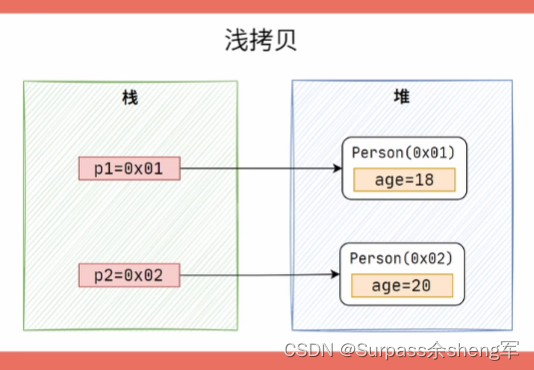
- 在Java中,Object提供了一个clone()方法,该方法的访问修饰符为protected,它是native方法,底层已经实现了拷贝对象的逻辑。

注意:子类一定得实现Cloneable接口,否则调用clone()方法时,就会抛出异常,这是Java的规 定。
- 现在我们就可以调用clone()来复制对象了,此时会发现,两个变量指向的已经是不同的对象
- 在浅拷贝中,如果拷贝的对象中有属性是引用类型,那这种浅拷贝的方式只会复制该属性的引用地址,即拷贝对象和原对象的属性都指向了同一个对象。如果对这个属性进行一些操作,则会影响到另一个对象的属性,若想将对象中的引用类型属性也进行拷贝,那就得用深拷贝了。
- Object类默认的是浅拷贝!
深拷贝:将clone()方法稍微修改一下,clone克隆出对象之后,我们再对对象的引用类型属性进行一次拷贝,这样就完成了引用类型属性的复制,此时对象中的引用属性也就指向了不同的对象实例

总结:
- 引用拷贝只是复制对象的地址,并不会创建一个新对象
- 浅拷贝会创建一个新对象,并进行属性复制,不过对引用类型的属性只会复制其对象地址
- 深拷贝则是完全复制整个对象,包括引用类型的属性
在实际开发中不建议使用clone()方法,因为它有抛出异常的风险。
浅拷贝:
package com.gch.clone;public class Person implements Cloneable {private int age;@Overridepublic Person clone() {try{return (Person) super.clone();}catch(CloneNotSupportedException e){return null;}}public Person() {}public Person(int age) {this.age = age;}/* 省略Setter,Getter,toString **/
}
package com.gch.clone;public class Main {public static void main(String[] args) {Person p1 = new Person(55);Person p2 = p1.clone();p2.setAge(20);// falseSystem.out.println(p1 == p2);// 55System.out.println(p1.getAge());}
}
深拷贝:
package com.gch.clone;/**深拷贝的代码实现*/
public class Person implements Cloneable {private int age;private int[] arr = new int[3];public Person() {}public Person(int age, int[] arr) {this.age = age;this.arr = arr;}@Overridepublic Person clone() {try{Person person = (Person) super.clone();// 调用引用类型的clone方法person.setArr(this.getArr().clone());return person;}catch(CloneNotSupportedException e){return null;}}/*** 获取* @return age*/public int getAge() {return age;}/*** 设置* @param age*/public void setAge(int age) {this.age = age;}/*** 获取* @return arr*/public int[] getArr() {return arr;}/*** 设置* @param arr*/public void setArr(int[] arr) {this.arr = arr;}@Overridepublic String toString() {return "Person{age = " + age + ", arr = " + arr + "}";}
}
package com.gch.clone;public class Main {public static void main(String[] args) {Person p1 = new Person(55,new int[]{1,2,3});Person p2 = p1.clone();// falseSystem.out.println(p2.getArr() == p1.getArr());}
}
二十三. 为什么要有字符串常量池
我们在开发中用的最多的对象应该就是String了,作为使用率最高的对象,Java对其做了不少优化,优化分两方面:一面是使用方式的优化,一面是性能优化。
- 使用方式的优化体现在:虽然String是对象,但可以不用new来创建,我们可以直接使用双引号来创建String对象,这种直接声明的方式称之为字面量。
注意:这并不算语法糖,两种对象创建方式是有区别的。
语法糖:语法糖就是底层原理相同,功能相同,但语法更简单。

- Java对String做的性能优化:当我们按照常规方式创建对象时,即使对象属性完全一致,也会创建多个对象,如果我们不想浪费资源,可以将其复用,比如声明为静态常量,那现在问题来了,如果我要复用一万个无规律的对象,我们不可能声明一万个静态常量。
- 这时可以将这些对象都放到一个容器中,要用的时候再获取,这就是对象池,对象池就像一个缓存,可以有效避免资源的重复创建。
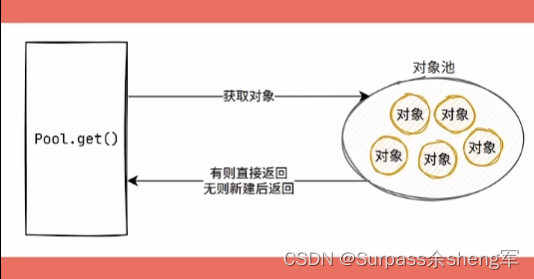
字符串常量池:JVM提供了字符串常量池,当我们用字面量创建字符串时,字符串常量池会将其对象引用进行保存,后面如果创建重复的字面量,就会直接将字符串常量池中的引用进行返回,可以有效避免资源的重复创建。
后面我们还会看到其它池类技术,比如线程池、连接池,池类技术都是为了节省资源和提高性能。
二十四. String为什么不可变,有什么好处吗?
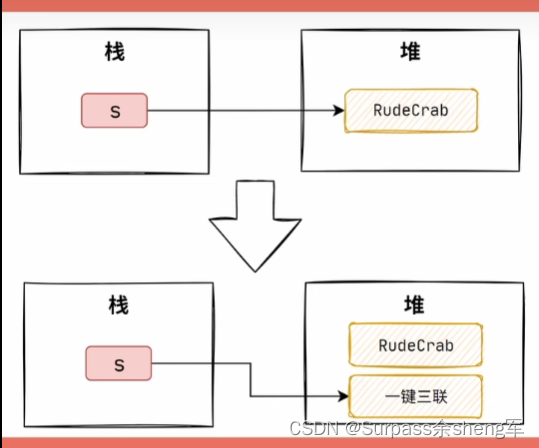
字符串,顾名思义就是一串连续的字符,也就是一串连续的char,在Java的一切皆对象世界中,将char数组进行了封装,用String类型来表示/表达字符串。
点开String的源码,就会发现char数组的身影,可以看到char数组被final关键字修饰,并且是私有成员变量 => 这就是为什么String的不可变性

一个对象创建后,如果我们可以修改对象的属性,那我们就会说这个对象是可变的,反之,则是不可变的。
注意:对象的不可变性,是指对象本身的属性或者说本身的数据不会改变,将变量重新赋值那是 创建了一个新对象,然后将新对象的引用赋值给了变量,之前的对象是没有受到影响的。
- 字符串不可变的原因不主要是字符数组被final关键字修饰。
- 字符数组被final关键字修饰,只能代表它不可指向新的数组,又不能代表数组本身的数据不会被修改。
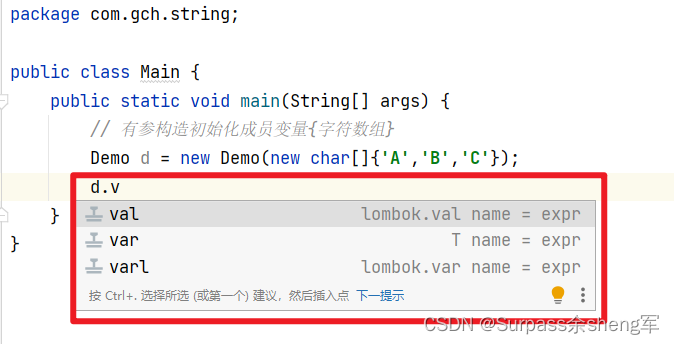
package com.gch.string;import java.util.Arrays;public final class Demo {/** 字符数组被final关键字修饰,只能代表它不可指向新的数组,但是数组本身的数据是可以被修改的 */public final char[] value;public Demo(char[] value) {this.value = value;}public static void main(String[] args) {// 有参构造初始化成员变量{字符数组}Demo d = new Demo(new char[]{'A','B','C'});// ABCSystem.out.println(d.value);// 修改字符数组本身的数据d.value[0] = '4';// 4BCSystem.out.println(d.value);// [4, B, C]System.out.println(Arrays.toString(d.value));// 直接报错,字符数组被final关键字修饰,因此不可指向新的数组// d.value = new char[]{};}
}
- 字符串真正不可变的原因是因为字符数组还被private修饰了,并且String没有暴露和提供任何修改字符数组的方法,一些字符操作都是返回新的String对象,绝对不会影响原数据。
- 获取其底层字符数组时{ toCharArray() },都是复制一个新数组进行返回,原数组也不会受到影响。

- 并且String类型还被final修饰了,代表其不可被继承,从而杜绝了子类覆盖父类行为的可能。
package com.gch.string;/**字符串真正不可被修改的原因*/
public final class Demo {/** 字符数组被final关键字修饰,只能代表它不可指向新的数组,但是数组本身的数据是可以被修改的 */private final char[] value;/** 有参构造 */public Demo(char[] value) {this.value = value;}
}
 为什么为为什么Java要这样设计呢?这样设计有什么好处呢?
为什么为为什么Java要这样设计呢?这样设计有什么好处呢?
- 首先,只有String不可变了,字符串常量池才能发挥作用,我们说过用字面量创建字符串时,字符串常量池会返回已有对象的引用,如果字符串可变,那引用的值就可以随时修改,并能随时影响到其它的引用,从而数据会发生各种的错误。
- 然后,String不可变可以保证它的哈希码也不会变,因此计算一次哈希码后就可以将其缓存,再用到时就无需计算了,性能更高。
- 不可变对象都是线程安全的,因为你不用担心当前线程使用的对象会被其它线程修改。可以发现,不可变对象有诸多优点,所以Java中有许多对象都设计成了不可变,比如BigDecimal。

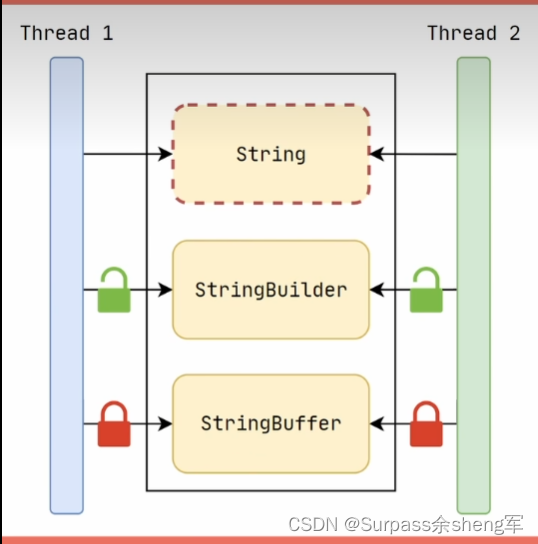
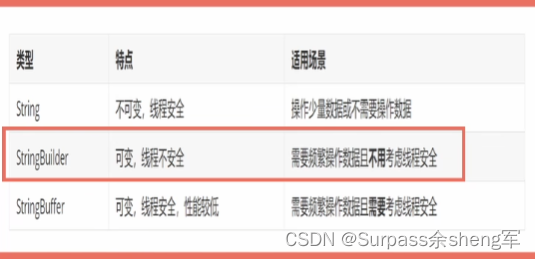
二十五. String不可变的弊端?StringBuilder、StringBuffer
- 当我们操作String时,不会改变原对象,只会创建新的String对象,因此当我们需要对字符串进行大量操作时,就必然会产生许多新对象,从而导致性能低下,为了解决这一问题,Java推出了StringBuilder这个可变的字符串类型。
StringBuilder:
- 并且StringBuilder还提供了许多方法供我们修改字符串,比如append()就可以用来在原字符串后面添加字符。
- 注意:StringBuilder这些方法修改的都是自身数据,返回的StringBuilder对象也都是它自己本身,以方便链式调用,不像String一样返回的都是新对象,这样一来我们频繁修改字符串就方便了很多。
- StringBuilder的缺点:由于它是一个可变对象,那它自然就线程不安全,为了解决这个线程安全问题,Java推出了StringBuffer。
- 在单线程环境下使用StringBuilder客户以获得更好的性能。
StringBuffer:
- StringBuffer的优点:StringBuffer内部使用了synchronized关键字修饰了字符串的操作方法,从而保证了线程安全。
- StringBuffer的缺点:由于它每次操作字符出时都会加锁,所以性能会比较低下。
二十六. Java中的char为啥占用两个字节?
- 在计算机内部,所有信息最终都是由二进制表示的。
- 为了表示字符与二进制之间的关系,诞生了许多字符集,比如被人熟知的ASCII码, ASCII用8位bit,也就是一个字节的容量来表示字符,最多可以表示256个字符,ASCII只定义了128个。
- 乱码:不同字符集不兼容的体现。
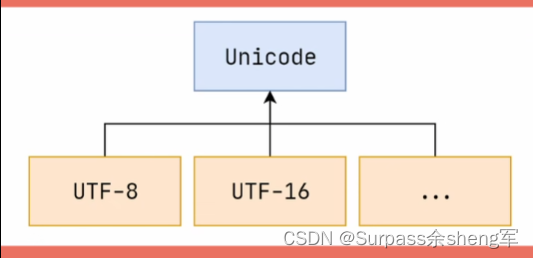
Unicode字符集只是一套标准,它只规定了二进制和字符的映射,并没有规定这些二进制该如何存储和传输。

Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format),缩写为UTF,UTF-8和UTF-16都是Unicode字符集的实现方式。
二十七. 都有数组了,为啥要用集合{容器}?
- 集合会根据实际存储的元素动态的扩容或缩容,而数组被创建之后就不能改变它的长度了。
- 集合创建时不需要指定大小,而数组创建时必须指定大小。
- 集合允许你使用泛型来确保类型安全,而数组则不可以。
- 集合中只能存储对象,对于基本数据类型,需要使用其对应的包装类。数组可以直接存储基本类型数据,也可以存储对象。
- 集合支持插入、删除、遍历等常见操作,并且提供了丰富的API操作方法。数组只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。
二十八. 如何选用集合?
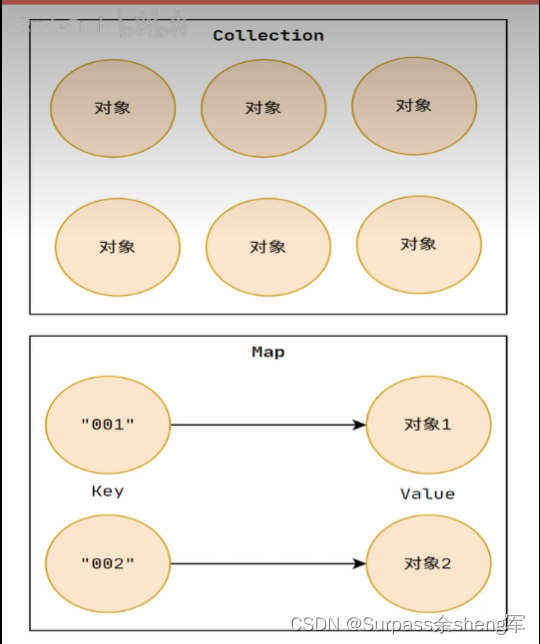
Java中的集合就两种,一种是Collection,一种是Map。
- Collection主要用于存放单一类型的元素,Map则用来存放映射关系,存放键值对元素。
比如:
- 如果你的需求只是存储一些学生对象,那就可以用Collection。
- 可如果你想通过学号或某个其它的唯一标识来快速找到指定的学生对象,那就要用Map,此时Map不光存储了学生这一类的元素,还存储了学号和学生的映射关系,这个映射关系我们称之为键值对,也就是我们常说的Key-Value,通过唯一的Key就可以快速定位到Value。
Collection和Map都是接口,各自都有诸多实现类,Map下的实现类相对要少很多。
- 其中用的最多的就是HashMap,万变不离其宗,Map集合最核心的永远是键值对映射关系。
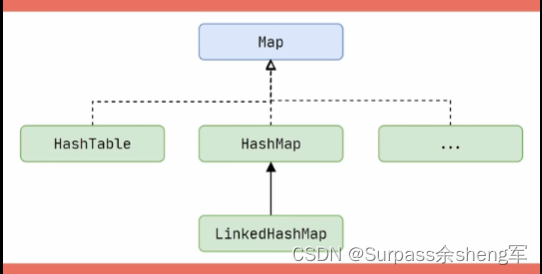
Collection下的实现就比较多了,它根据特性还细分了三大接口:List、Set和Queue。
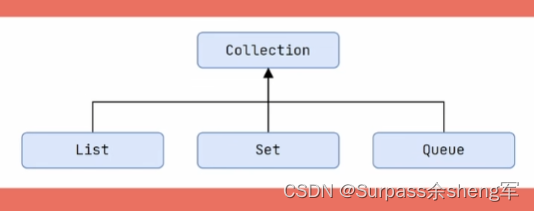
List系列集合:添加元素是有序、可重复、有索引。最常用是ArrayList
Set系列集合:添加元素是无序、不重复、无索引。最常用是HashSet
Queue系列集合:
- Queue和List很像,存储的元素是有序的,且可以重复,不过Queue的有序不是指插入元素时的顺序,而是指特定规则下的顺序。
- 它最大的特性就是可以按照特性规则去操作元素。
- 比如:先进先出的规则,就像排队一样 ,常用的类有ArrayDeque和LinkedList

Collection和Map作为顶级接口,自然定义了一些抽象方法去规范子类行为。

二十九. 形参和实参的区别?
- 形参是方法定义时声明的参数,用于接收方法调用时传递的实参,它只存在于方法的定义中,不占用实际的内存空间。
- 实参是方法调用时传递的参数,用于向方法传递数据,它存在方法的调用中,占用实际的内存空间。
- 形参和实参的数量、类型、顺序必须一一对应,否则会导致编译错误或运行时时错误。
这篇关于「奇思妙想」的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!