本文主要是介绍dpdk/vpp中的memif使用方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
同一主机上的不同DPDK进程可以采用内存交换的方式进行报文传输,这一传输接口叫做memif(shared memory packet interface)。传输的报文是原始报文格式,可以配置为Ethernet模式,IP模式,Punt/Inject模式。目前DPDK memif只支持Ethernet模式。memif接口有两种身份,master和slave,也可以称为server和client,两者通过socket传递控制消息。master和slave是一一对应的关系,一个master只能和一个slave连接,两者拥有相同的id。master负责创建socket并监听slave的连接请求。slave负责创建共享内存文件和初始化共享内存,并且会主动发起socket连接请求。
memif采用unix域套接字来传递控制消息,每组memif在socket里面都有一个唯一的id,这个id也是用来识别对端接口的标识。slave接口在创建的时候,会在指定的socket上尝试连接。socket的监听进程即master接口所在的进程会提取连接请求,并创建一个连接控制信道,并通过此信道发送hello消息,这条消息包含了一些配置信息。slave收到hello消息之后,会根据消息所带的配置来调整自己的配置,随后回复init消息。init消息包含了接口id,监听进程提取接口id,并将控制信道绑定到对应的接口上,之后回复ack。slave收到ack之后就开始创建内存区域(region)和环形队列(ring),并针对每个region和ring都发送一条add消息,master收到后需要逐一回复ack。待slave收到最后一条add ring的ack回复之后,就会发送connect消息,表示slave已经准备就绪。master收到此消息之后,会将region映射到自己的地址空间,初始化ring并回复connected消息,之后就能进行数据报文传输。如果接口状态出现异常,无论是master还是slave,都可以随时发送断开连接请求。
master和slave的协商过程如下:

共享内存
slave是共享内存的生产者,而master是消费者。内存区域(region)是映射的共享内存文件,由 memif slave创建并在连接建立时提供给master。内存区域包含了ring和buffer。ring和buffer可以被分配在多个不同的内存区域。对于非零拷贝模式,ring和buffer只能开辟在同一个内存区域以减少需要打开的文件数量。
slave 非零拷贝内存区域结构 region n (no-zero-copy):
| Rings | Buffers | |||
| S2M rings | M2S rings | packet buffer 0 | ... | packet buffer n |
buffer的总数量为 (ring的数量) x (ring size)。
ring 数据结构:
typedef struct {
MEMIF_CACHELINE_ALIGN_MARK(cacheline0);
uint32_t cookie; /**< MEMIF_COOKIE */
uint16_t flags; /**< flags */
#define MEMIF_RING_FLAG_MASK_INT 1 /**< disable interrupt mode */
uint16_t head; /**< pointer to ring buffer head */
MEMIF_CACHELINE_ALIGN_MARK(cacheline1);
uint16_t tail; /**< pointer to ring buffer tail */
MEMIF_CACHELINE_ALIGN_MARK(cacheline2);
memif_desc_t desc[0]; /**< buffer descriptors */
} memif_ring_t;
描述符数据结构:
typedef struct __rte_packed {
uint16_t flags; /**< flags */
#define MEMIF_DESC_FLAG_NEXT 1 /**< is chained buffer */
memif_region_index_t region; /**< region index on which the buffer is located */
uint32_t length; /**< buffer length */
memif_region_offset_t offset; /**< buffer offset */
uint32_t metadata;
} memif_desc_t;
描述符中有个MEMIF_DESC_FLAG_NEXT标志,如果这个标志被置上了,就代表当前的报文长度大于buffer长度,报文会被分成多个buffer存储,并且buffer有可能不连续的。
slave零拷贝客户端:
在进行memif接口配置的时候,可以将slave配置成零拷贝模式。配置成这种模式时,所有的buffer都是从slave进程的memseg中分配出来并暴露给master。DPDK必须使能 ‘–single-file-segments’,保证所有的buffer都在同一块memseg,可以很容易从内存文件的起始位置偏移出buffer的地址,并且buffer的地址是连续的。
slave非零拷贝 vs slave零拷贝
slave配置成非零拷贝模式时,需要在slave内存空间中单独开辟一块内存区域,slave轮询读取从master发送过来的报文时,需要将报文从region的buffer中拷到memseg当中,slave往master发送报文时,需要先将报文拷贝到region当中,然后由master轮询读取。master去读写报文时,始终都需要内存拷贝。
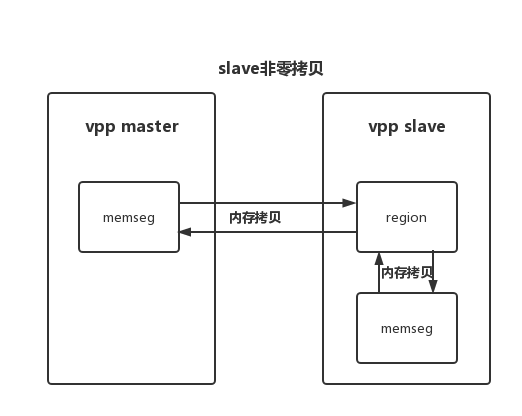
slave配置成零拷贝模式时,buffers直接在slave的memseg上分配,slave进程直接操作buffer描述符即可,无需额外内存拷贝,只需要master进程读写报文时进行内存拷贝。

组网测试
下面使用vpp配置memif接口,对比验证下memif的性能。
在服务器上分别起两个vpp进程,vpp1和vpp2。vpp1和vpp2各配置了1个main core和1个work core。在vpp1上创建memif1/1并配置成master,在vpp2上创建memif1/1并配置成slave。vpp1和vpp2各绑定一个10G以太网卡,网口连接交换机,同时Test Center上也有两个10G以太网接口连接交换机。测试流从Test Center一个端口经过vpp1和vpp2两次L3转发至Test Center另外一个端口。测试拓扑图如下:
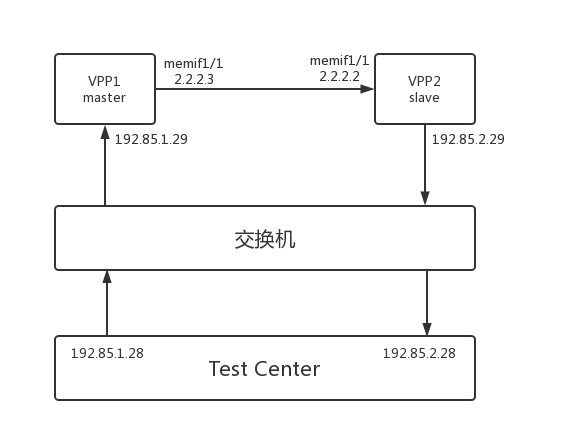
分别测试以下4中情况的报文转发性能:
1. vpp1和vpp2的core以及绑定的网卡在同一个numa node,vpp2的memif slave配置成零拷贝模式。
2. vpp1和vpp2的core以及绑定的网卡在同一个numa node,vpp2的memif slave配置成非零拷贝模式。
3. vpp1和vpp2的core以及绑定的网卡在不同的numa node,vpp2的memif slave配置成零拷贝模式。
4. vpp1和vpp2的core以及绑定的网卡在不同的numa node,vpp2的memif slave配置成非零拷贝模式。
vpp1和vpp2上配置命令如下:
创建memif的时候加上no-zero-copy可以配置成非零拷贝模式。另外配置的时候需注意绑定的网卡和core与numa的关系是否和设想的一致。
##### vpp1 配置
set int state TenGigabitEthernetc2/0/0 up
create sub-interfaces TenGigabitEthernetc2/0/0 1 dot1q 1019 exact-match
set interface state TenGigabitEthernetc2/0/0.1 up
set interface ip address TenGigabitEthernetc2/0/0.1 192.85.1.29/24
create memif socket id 111 filename /run/vpp/contiv/memif111.sock
create interface memif id 1 socket-id 111 master ring-size 8192 tx-queues 2 rx-queues 2
# create interface memif id 1 socket-id 111 master ring-size 8192 tx-queues 2 rx-queues 2 no-zero-copy
set interface state memif111/1 up
set interface ip address memif111/1 2.2.2.3/24
ip route add 192.85.2.0/24 via 2.2.2.2##### vpp2 配置
set int state TenGigabitEthernet1/0/1 up
create sub-interfaces TenGigabitEthernet1/0/1 1 dot1q 1020 exact-match
set interface state TenGigabitEthernet1/0/1.1 up
set interface ip address TenGigabitEthernet1/0/1.1 192.85.2.29/24
create memif socket id 111 filename /run/vpp/contiv/memif111.sock
create interface memif id 1 socket-id 111 slave ring-size 8192 tx-queues 2 rx-queues 2
# create interface memif id 1 socket-id 111 slave ring-size 8192 tx-queues 2 rx-queues 2 no-zero-copy
set interface state memif111/1 up
set interface ip address memif111/1 2.2.2.2/24
ip route add 192.85.1.0/24 via 2.2.2.3vpp配置完成之后,从TC上分别ping 192.85.1.28和192.85.2.28以完成mac地址的学习。
##### vpp1
vpp# show ip neighborTime IP Flags Ethernet Interface 69.9117 192.85.1.28 D 00:10:94:00:00:02 TenGigabitEthernetc2/0/0.131.1328 2.2.2.2 D 02:fe:64:40:98:8d memif111/1##### vpp2
vpp# show ip neighborTime IP Flags Ethernet Interface 186.6420 192.85.2.28 D 00:10:94:00:00:19 TenGigabitEthernet1/0/1.127.8395 2.2.2.3 D 02:fe:48:42:a7:89 memif111/1从Test Center 端口发送报文长度为1024字节的udp报文,测试vpp三层转发以及memif性能。报文格式如下:

测试结果如下:
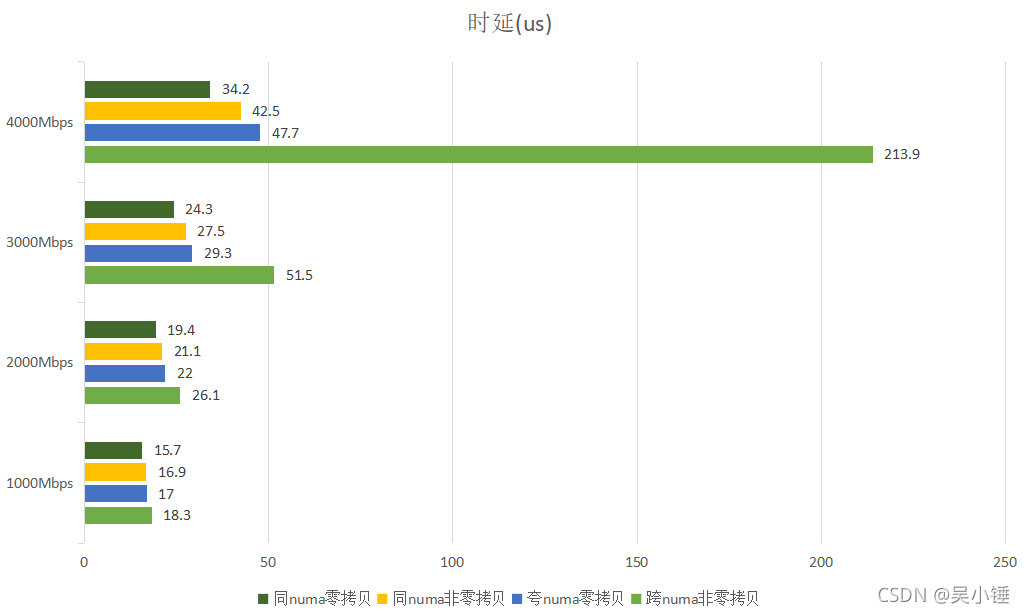

从时延和vpp矢量数据可以看出,采取零拷贝模式,在基于dpdk的不同应用间进行高性能流量转发,也有着不错的性能,不失为一个较好的解决方法。
这篇关于dpdk/vpp中的memif使用方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



