本文主要是介绍将多个txt文件转换为一个excel文件,xlwt包的基本使用(包含代码)代码都有注解,保姆级别教程。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、首先了解一下xlwt包的一些基本方法和使用:
ps:(如果明白xlwt包基础使用的同学可以直接看第二部分,多个txt输入到一个excel文件当中去。)
Python中使用的是xlwt模块来生成Excel文件,并且可以控制单元格的格式。xlwt.Workbook()返回的xlwt.Workbook类型的save(filepath)方法可以保存excel文件。下面就让我们看看写excel文件的流程及需要使用的函数吧。写excel前也必须先导入该模块(import xlwt)。
基本流程如下:
1.1 安装xlwt包:
打开pycharm,在terminal终端上输入pip install xlwt就行。另外还有个可能要用到的os包也同样可以在这里导入pip install os
 1.2 创建表格和工作表单(sheet)
1.2 创建表格和工作表单(sheet)
用workbook的add_sheet方法添加表单,可以添加多个表单,也就是对应图二下面excel表的sheet
import os
import xlwtworkbook = xlwt.Workbook() # 创建一个Workbook对象
worksheet = workbook.add_sheet('sheet') # 由workbook对象生成一个叫命名为sheet1的表单(sheet) 
1.3 接下来就可以在excel表单的单元格中添加数据:
使用worksheet的write方法写入,对应参数如:worksheet.write(row,col,value)行,列,值(行列下标都是从0开始)。例如我在表单(0,0)中添加内容:并且保存excel文件为shuaige.xsl
import os
import xlwtworkbook = xlwt.Workbook() # 创建一个Workbook对象
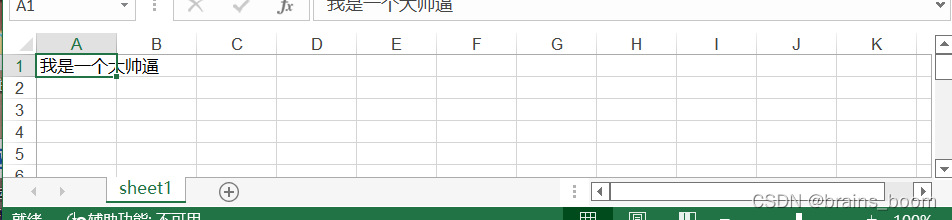
worksheet = workbook.add_sheet('sheet1') # 由workbook对象生成一个叫命名为vi的表单(sheet)worksheet.write(0, 0, '我是一个大帅逼')
workbook.save('shuaige.xls')接着项目中就会出现这个文档:
打开看看
好了这就是xlwt包的基础使用,接下来我们用它来完成多个txt文件转到一个excel文件当中去。
二、多个txt文件输入到一个excel文件中去:
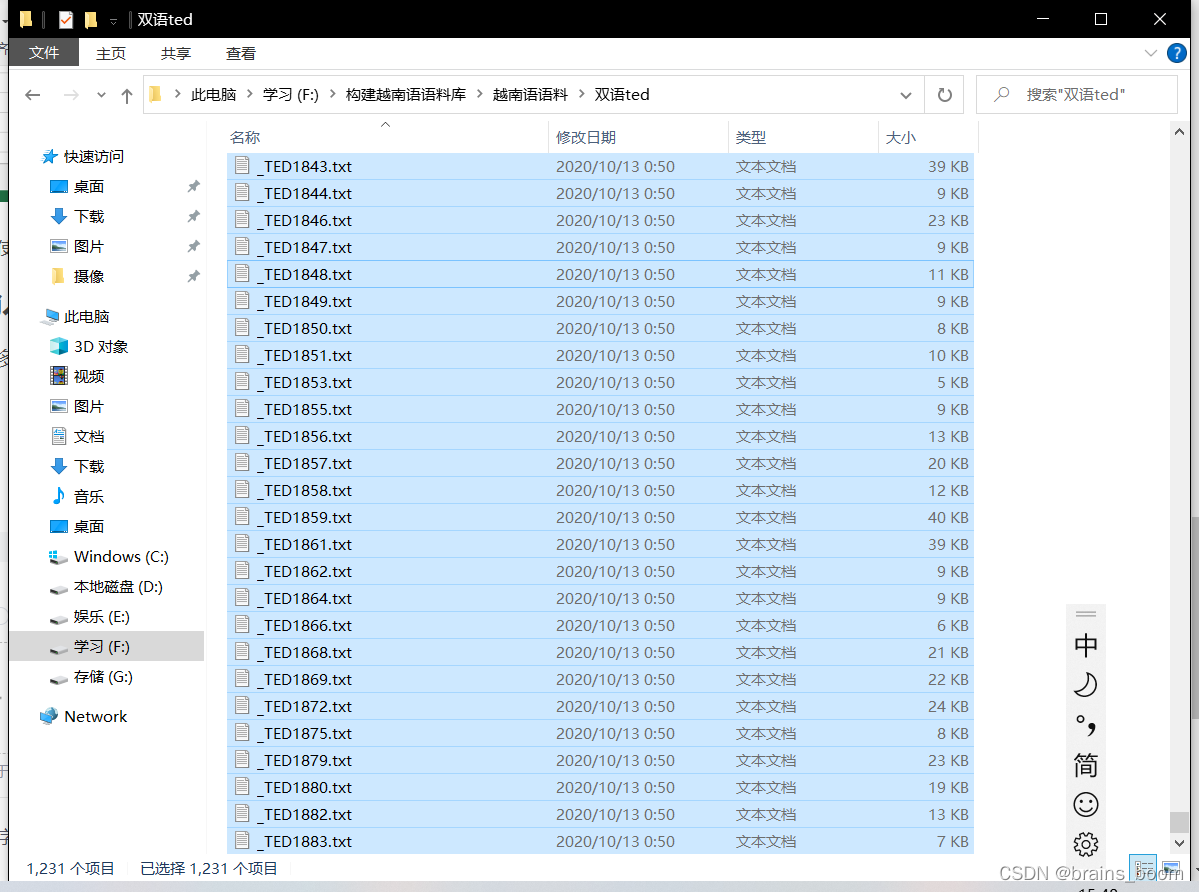
我们有一个文件夹有这么多txt文件,并且每个文件中还有两个不同种的语言,想要将其分开并且得到一个excel表。如图:
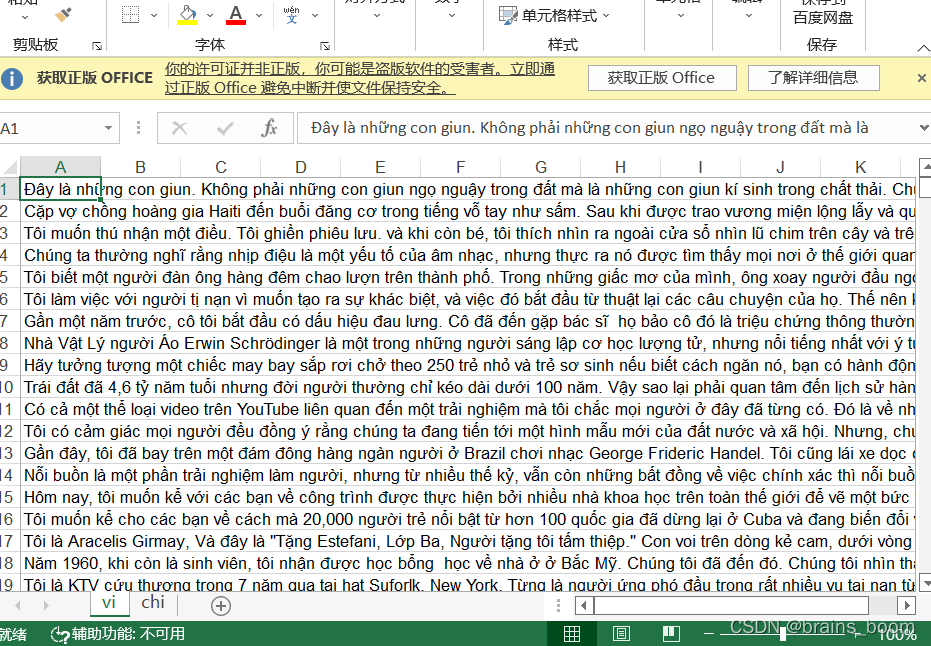
txt文件是这样的:一行越南语,一行中文。

我们想要得到的样子:(这里我已经编程实现了所以才有结果图,不然我还处理干啥是吧😀)
一个表单页面的第一列,顺序下去的每一行放一个txt文件的越南语,对应一页放对应的中文翻译。
-------------------------------------------------------------------------------------------------------------------------分割

好,让我们看怎么实现:
我直接放代码,然后再一步一步解析:
import xlwt
import os# 一个txt文件转excel文件的封装对象
class TxtToExcel(object):def __init__(self, path):self.path = path # txt文件路径self.workbook = xlwt.Workbook(encoding='UTF-8') # 创建工作表''' add_sheet(sheet_name): 添加sheetget_sheet(Sheet_name): 选择sheetsave(file_name): 保存'''self.worksheet1 = self.workbook.add_sheet('vi', cell_overwrite_ok=True) # 工作表里面添加一个sheet表self.worksheet2 = self.workbook.add_sheet('chi', cell_overwrite_ok=True)# 读取txt文件内容def read_content(self, file):with open(self.path + r'\\' + file, 'r', encoding='utf-8') as f:print('读取txt内容')return f.readlines() # 将读取到的 行s 返回出 返回的是一个list 带有\n# 文件列表def file_list(self):print('返回文件list')return os.listdir(self.path) # 返回一个list,是当前文档里面所有文件的名称def write_to_excel_sheet1(self, row, param, c):print('写入sheet1')self.worksheet1 = self.workbook.get_sheet('vi')self.worksheet1.write(row, param, c)def write_to_excel_sheet2(self, row, param, c):print('写入sheet2')self.worksheet2 = self.workbook.get_sheet('chi')self.worksheet2.write(row, param, c)# 得到文件列表def get_file_path_list(self):print('运行get_file')file_path_list = self.file_list()print(file_path_list)for j, file in enumerate(file_path_list): # 遍历文档的文件# with open(self.path + r'\\' + file, 'r', encoding='utf-8') as f:# content = f.readlines()content = self.read_content(file)print('读取内容', content)sheet1_content = '' # 用于存储越南语sheet2_content = '' # 用于存储汉语for i, c in enumerate(content): # enumerate函数是将list分为下标和值对应,也就是i为对应下标遍历,c为i位置上的内容。if i % 2 == 0:sheet1_content += celse:sheet2_content += cself.write_to_excel_sheet1(j, 0, sheet1_content)self.write_to_excel_sheet2(j, 0, sheet2_content)self.workbook.save('test.xls')if __name__ == '__main__':path = r"F:\test" # txt文件夹位置TxtToExcel(path).get_file_path_list()
先理顺逻辑,我们想要将txt文件输入到excel中去,步骤1.先要批量打开txt文件,步骤2.然后再创建一个excel表,输入到excel表当中去:
想实现步骤1得先获取到txt文件位置:用
def file_list(self):print('返回文件list')return os.listdir(self.path) # 返回一个list,是当前文档里面所有文件的名称
得到所有文件名称,一个list[]。
再打开txt文件读取内容,读取内容的同时将想要的越南语和汉语分开:
def read_content(self, file):with open(self.path + r'\\' + file, 'r', encoding='utf-8') as f:print('读取txt内容')return f.readlines() # 将读取到的 行s 返回出 返回的是一个list 带有\n
打开的同时分开越南语和汉语:
for j, file in enumerate(file_path_list): # 遍历文档的文件# with open(self.path + r'\\' + file, 'r', encoding='utf-8') as f:# content = f.readlines()content = self.read_content(file)print('读取内容', content)sheet1_content = ''sheet2_content = ''for i, c in enumerate(content):if i % 2 == 0: # 奇数行为越南语 sheet1_content += celse: # 偶数行为汉语sheet2_content += c
接下来步骤2:要将内容给输入到excel文件当中去 , 要先创建excel表单:
def __init__(self, path):self.path = path # txt文件路径self.workbook = xlwt.Workbook(encoding='UTF-8') # 创建工作表''' add_sheet(sheet_name): 添加sheetget_sheet(Sheet_name): 选择sheetsave(file_name): 保存'''self.worksheet1 = self.workbook.add_sheet('vi', cell_overwrite_ok=True) # 工作表里面添加一个vi表self.worksheet2 = self.workbook.add_sheet('chi', cell_overwrite_ok=True) #工作表里添加一个chi表
保存到表单的方法:
def write_to_excel_sheet1(self, row, param, c):print('写入sheet1')self.worksheet1 = self.workbook.get_sheet('vi')self.worksheet1.write(row, param, c)def write_to_excel_sheet2(self, row, param, c):print('写入sheet2')self.worksheet2 = self.workbook.get_sheet('chi')self.worksheet2.write(row, param, c)
然后再是将内容一行一行写入excel中去:
for j, file in enumerate(file_path_list): # 遍历文档的文件# with open(self.path + r'\\' + file, 'r', encoding='utf-8') as f:# content = f.readlines()content = self.read_content(file)print('读取内容', content)sheet1_content = ''sheet2_content = ''for i, c in enumerate(content):if i % 2 == 0:sheet1_content += celse:sheet2_content += cself.write_to_excel_sheet1(j, 0, sheet1_content)self.write_to_excel_sheet2(j, 0, sheet2_content)self.workbook.save('test.xls')
好了 代码就带你读到这,在main方法中将文件夹路径放进去就好:
if __name__ == '__main__':path = r"F:\test"TxtToExcel(path).get_file_path_list()
搬运请告知。
这篇关于将多个txt文件转换为一个excel文件,xlwt包的基本使用(包含代码)代码都有注解,保姆级别教程。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





