本文主要是介绍rhcs群集构建 scsi+iscsi+luci+ricci的web页面配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系统版本:RHEL5.4
<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
将selinux关闭,刷新iptables -F
配置yum仓库
192.168.2.10 target.a.com 宿主机
192.168.2.20 node1.a.com 节点(虚拟机) initiators
192.168.2.30 node2.a.com 节点(虚拟机) initiators
安装scsi, luci和iscsi, ricci套件
宿主机/node1/node2:
vim /etc/hosts
192.168.2.10 target.a.com target
192.168.2.20 node1.a.com node1
192.168.2.30 node2.a.com node2
并修改三台的hostname。
target # yum install scsi* luci -y (luci套件是宿主机集群web接口)
target # luci_admin init 设置密码
target # chkconfig luci --level 35 on (设置开机启动)
target # chkconfig tgtd --level 35 on (设置开机启动)
target # service luci start
target # service tgtd start
fdisk /dev/sda //新建一个分区用来做共享磁盘。
tgtadm --lld iscsi --op new --mode target --tid=1 --targetname iqn.2011-10.com.a.target:disk
tgtadm --lld iscsi --op new --mode=logicalunit --tid=1 --lun=1 --backing-store /dev/sda2
增加一个lun块设备提供给node
tgtadm --lld iscsi --op bind --mode=target --tid=1 --initiator-address=192.168.2.0/24
//创建一个acl访问控制链接 允许192.168.2.0网段的用户可以使用。
并把它们写入/etc/rc.d/rc.local进行开机启动
tgtadm --lld iscsi --op show --mode target //通过show来查看共享快信息。
node1# yum install iscsi ricci –y
service iscsi start
node1# chkconfig iscsi --level 35 on
vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2011-10.com.abc.node1
iscsiadm --mode discovery --type sendtargets --portal 192.168.2.10
发出一个发现指令去连接192.168.2.10
iscsiadm --mode node --targetname iqn.2011-10.com.a.target:disk --portal 192.168.2.10 --login
允许登陆到192.168.2.10上面
node1# service ricci start
node1# chkconfig ricci --level 35 on (设置开机启动)
做完后就可以通过fdisk –l观察到本地磁盘多了一块/dev/sdb硬盘。
node2上边和node1配置一样,就不多说了。
使用web界面生成集群配置文件cluster.conf
在宿主机中访问https://192.168.2.10:8084
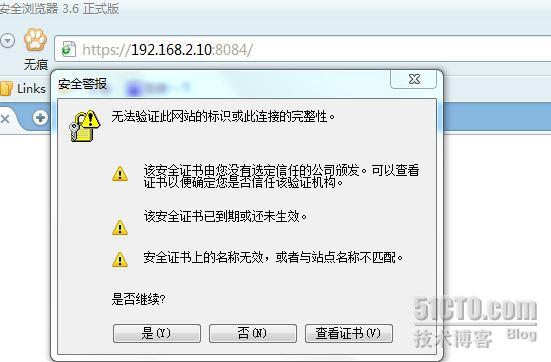
直接是,进入登陆页面
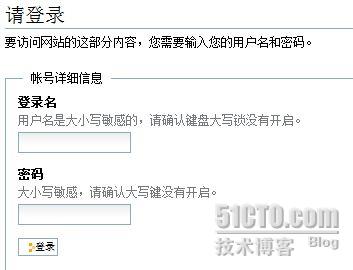
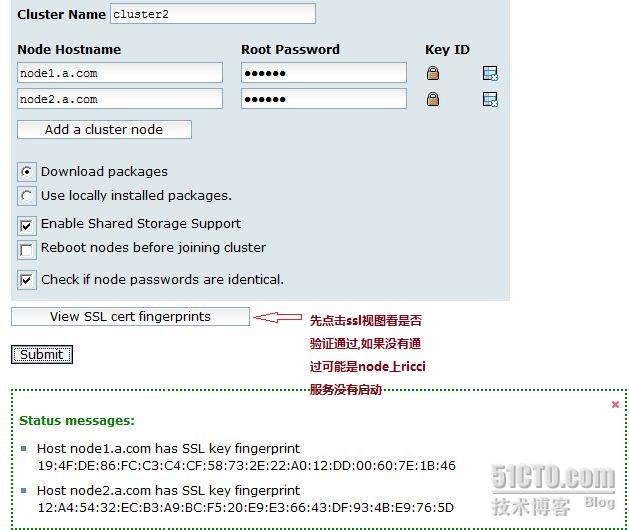
输入luci帐号密码,进入家目录。创建集群cluster2
这个集群的名称无所谓,但是 不能用cluster这个名称.
然后在 node1 主机上面把存储设备的文件系统创建为 gfs 文件系统 .
步骤 :
· 在其中一个 node 上把共享磁盘分区
· partprobe /dev/sdb // 重新读取分区表,这一步需要在两个 node 节点上都做
· pvcreate /dev/sdb1 建立物理卷
· vgcreate vg01 /dev/sdb1 建立卷组
· lvcreate -L 2000m -n lv01 vg01 建立逻辑卷
· 把逻辑卷格式化为 gfs 文件系统。
· gfs_mkfs -p lock_dlm -t cluster1:lv01 -j 3 /dev/vg01/lv01 //cluster1 必须是你创建的集群名
· 重启逻辑卷守护进程 service clvmd restart
测试:
1 ,在俩个 node 上都建立挂在点 mkdir /mnt/cluster
2, 并把逻辑卷都挂载上 mount /dev/vg01/lv01 /mnt/cluster
3, 在其中一个 node 上的挂在点内创建文件和 http 页面,切换到另一个 node ,可以看到共享的信息。从而实现共享存储。
测试完成后,建立 fence 设备
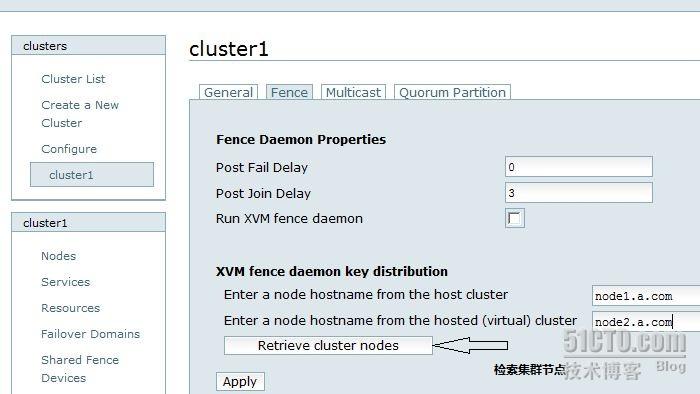
进入检索页面后,创建集群钥匙
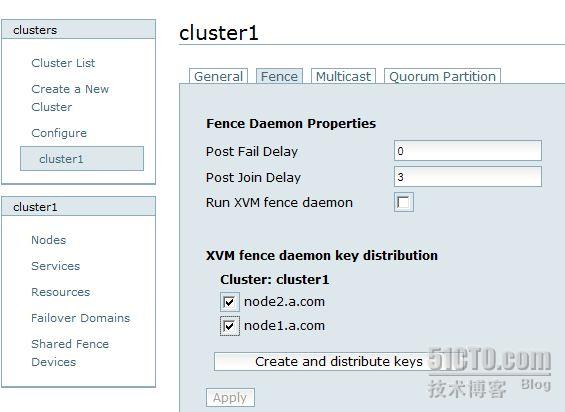
然后直接提交
创建失败恢复域,修改某一个 node 的优先级,越小越优先:

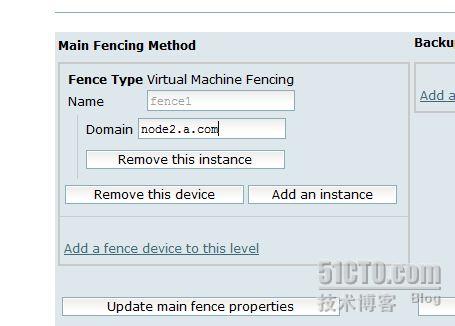
添加一个 fence 设备
我们用的虚拟机做的宿主机,所以fence设备要选 virtual machine fencing
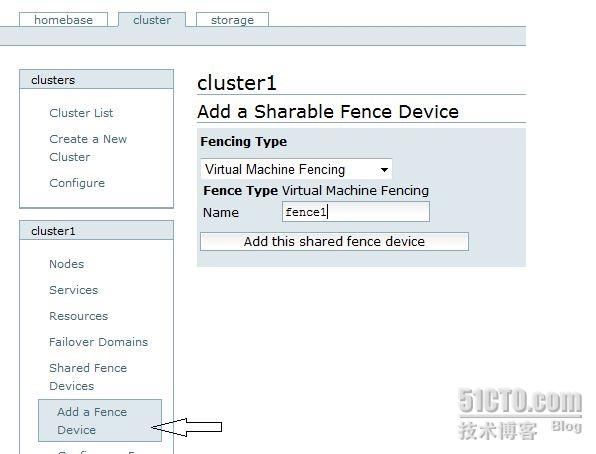
把这个 fence1 应用到各个 node 上边,两个node主机都应用.
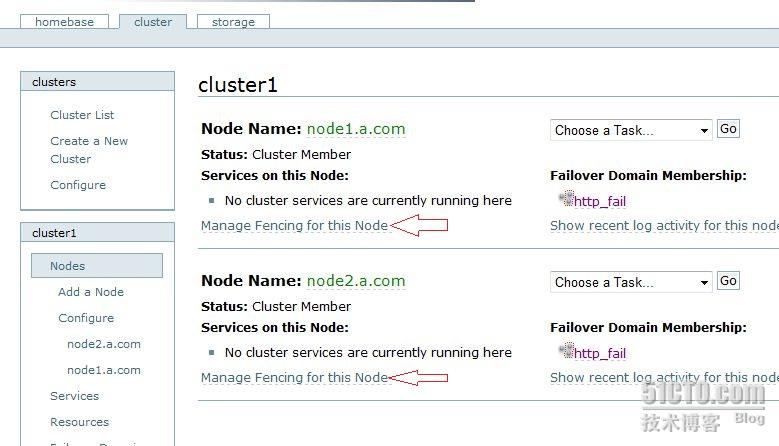
点击进入 node1.a.com, 添加 fence 设备
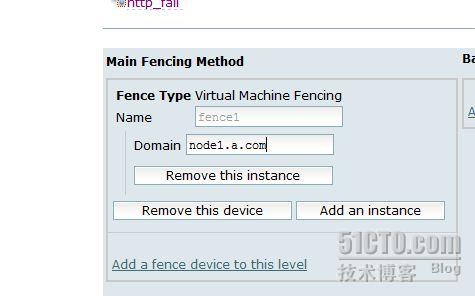
同样,点击node2,添加fence设备.
应用之后需要添加群集资源:
资源有:
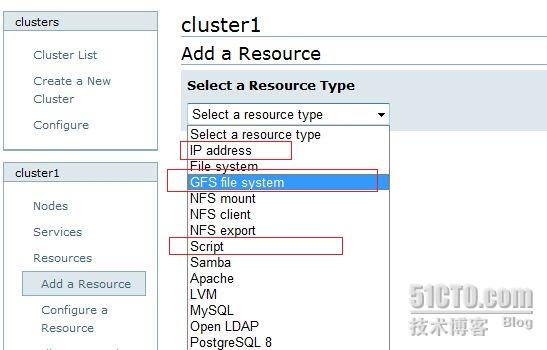
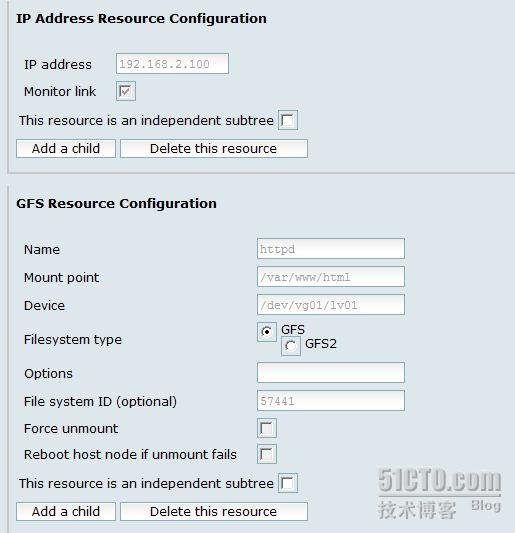
1 : 群集 ip
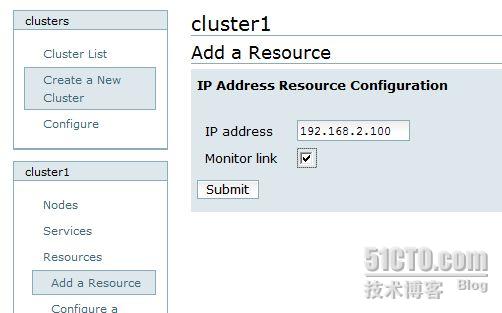
2 :群集 gfs 文件系统
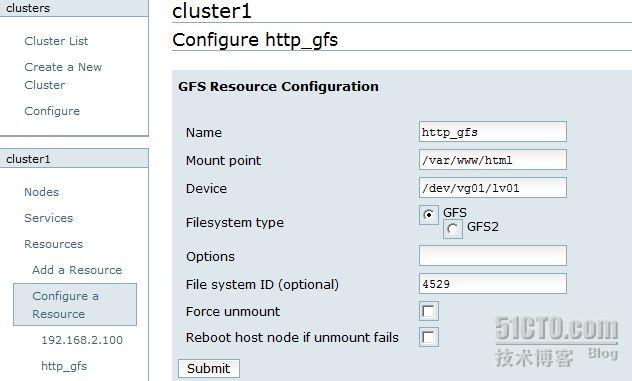
3 , script
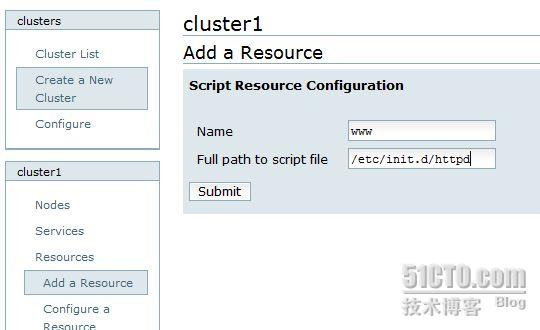
然后添加集群服务 service:

把存在的 3 个资源都添加到服务中:
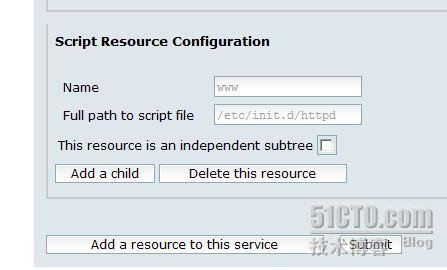
提交后完成集群的配置。
然后在 node 主机上配置 web 服务器,可以通过手动切换 node
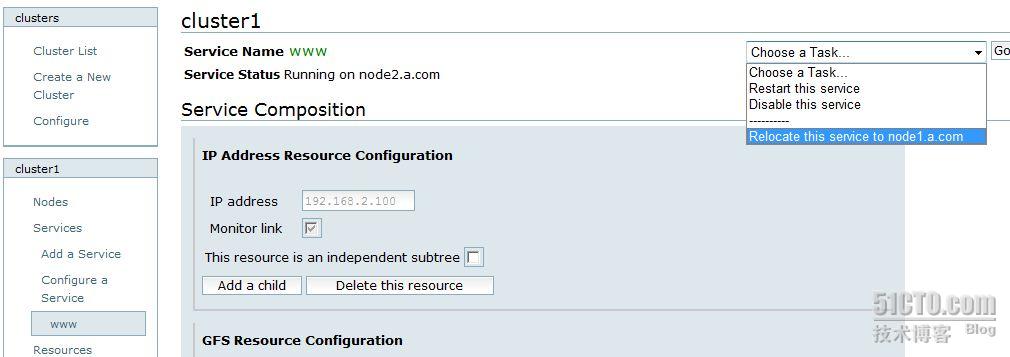
也可以通过模拟服务器系统坏掉,另一个 node 自动启动 http 服务。
yum install -y httpd
安装完后不需要启动就行。
在 node 主机上可以通过
clustat 静态察看集群节点的状态
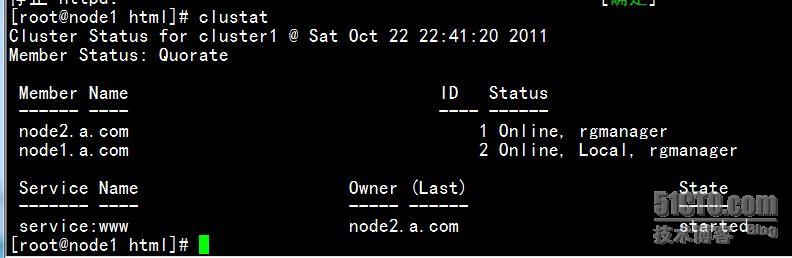
也可以 clustat -i 1 动态观看
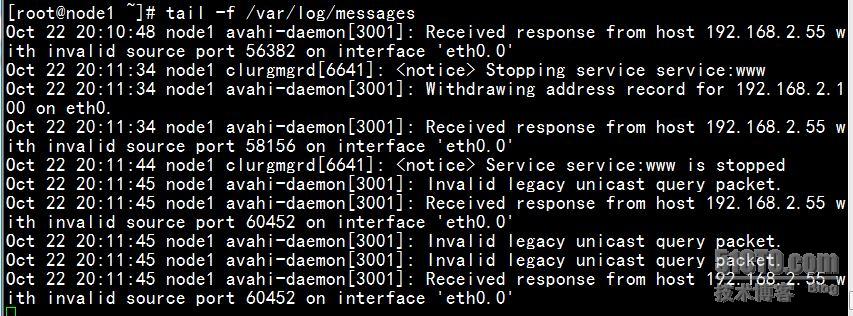
也可以通过日志察看
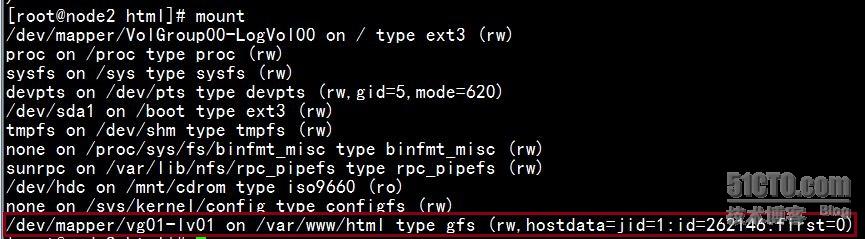
也要注意观察宿主机上的共享磁盘挂载各个 node 上的情况
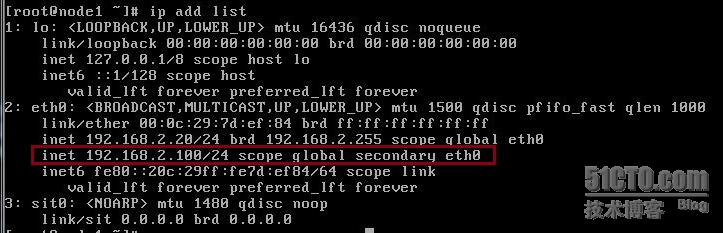
通过 ip add list 可以看到群集地址
顺便说一下 fence 设备的用处:
配置 fence device, 这里使用的是虚拟机,所以类型是 Virtual Machine Fencing, 将名字取名为 vmfence. 如果使用的是真机,可选择对应的类型
( 核心在于解决高可用集群在出现极端问题情况下的运行保障问题,在高可用集群的运行过程中,有时候会检测到某个节点功能不正常,比如在两台高可用服务器间的心跳线突然出现故障,这时一般高可用集群技术将由于链接故障而导致系统错判服务器宕机从而导致资源的抢夺,为解决这一问题就必须通过集群主动判断及检测发现问题并将其从集群中删除以保证集群的稳定运行, Fence 技术的应用可以有效的实现这一功能
总结的可能不全,大家不懂得都可以来一起讨论。热烈欢迎,其实本人也才学linux不久。。。。
转载于:https://blog.51cto.com/anming/696831
这篇关于rhcs群集构建 scsi+iscsi+luci+ricci的web页面配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






