本文主要是介绍GDS-enabled BeeGFS 人工智能并行存储解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目背景
HPC 和 AI 的融合正在颠覆一切。在这样的新时代,企业需要全新的存储解决方案,才能以高效且经济的方式从容应对来势汹汹的数据洪流。独立分析公司 Intersect360 开展的一项研究发现,多达 66% 的 HPC 用户目前已在执行机器学习计划。Hyperion Research 预测,按照当前的进程和速度,未来三年内公共部门组织和企业的 HPC 存储支出将比 HPC 计算支出的增长速度快 57%。日本的HPC业界更认为未来的HPC应用都是基于深度学习算法的。CPU+GPU异构计算成为当前超算中心建设的标准方案,GPU的功能显得愈发重要,不仅仅渲染显示,更有助于加速科学计算效率,尤其是随着深度学习算法融入传统HPC应用软件的工作流程中。
| 传统 HPC 群集 | 新融合时代 | 传统 AI 堆栈 (POD) | |
| 主要工作负载 | 建模与仿真 | 两者 | 机器学习/深度学习 |
| 计算节点类型 | CPU 节点 | CPU + GPU节点 | GPU 节点 |
| 计算节点数量 | 数百到数千 | 数百到数千 | 几个 |
| 典型互连 | InfiniBand | 两者 | 千兆以太网 |
| 主要输入/输出模式 | 写入密集型 | 两者 | 读取密集型 |
| 存储容量计量单位 | PB | PB | TB |
| 单一命名空间中的存储可扩展性 | 最多 EB 级 | 容量高至 EB 级 | 容量低至几十 PB |
| 典型存储 | 基于 HDD 的并行文件系统存储 | Cray ClusterStor E1000 (Lustre)HPC并行文件系统存储 | 全闪存企业的 NAS 存储 |
| 存储的用途 | 以每秒高达 TB 的速度按顺序处理大文件 | 以每秒高达 TB 的速度按顺序和随机顺序提供规模不一的文件 | 以每秒高达几十 GB 的速度按顺序和随机顺序提供规模不一的文件 |
| 每 TB 价格 | $ | $$ | $$$$$ |
可视化是分析大量科学模拟数据的有效方式,科学可视化是将数值计算数据以图像形式显示来观察科学现象的过程。常用的科学可视化工具包括:
- 体渲染。例如,医学设备MRI、CT得到的序列2D图像合成3D渲染效果图。
- 面渲染。例如,蛋白质分子结构,需要在3D结构上计算出等值面。
科学可视化常用工具包括:
- Paraview
Paraview是一个开源的,跨平台的数据处理和可视化程序,使用分布式的内存计算资源,能够实现对非常大的数据集的分析与处理。可以处理数十亿个非结构化单元格和超过1万亿个结构化单元格。ParaView的并行框架已经在超过10万个处理核心上运行。
- Visualization Toolkit (VTK)
VTK提供了基本的可视化和渲染算法,如渲染、并行处理、文件I/O和并行渲染,用于三维计算机图形学、图像处理和可视化。支持并行处理(VTK曾用于处理大小近乎1个Petabyte的数据集,其平台为美国Los Alamos国家实验室所有的具1024个处理器的超算集群)的图形应用函式库。2005年时曾被美国陆军研究实验室用于即时模拟俄罗斯制反导弹战车ZSU23-4受到平面波攻击的情形。
- VisIt
VisIt是一种免费、开放源代码、跨平台、分布式、并行的可视化工具,用于可视化在二维和三维结构化和非结构化网格上定义的数据。VisIt的分布式体系结构使其可以利用超算平台进行计算和本地计算机进行绘图。支持PB级数据的可视化。
在模拟数据的规模急剧增加的情况下,一次性加载到内存供GPU显示变得异常困难。当大规模数据集要加载到内存来可视化时,GPU训练性能会急剧下降。NVIDIA GPUDirect Storage® (GDS) 提供了一种以持续IO、低时延的性能从分布式存储系统直接读取数据到GPU显存中的方案,DGX SuperPOD 使能GDS的应用直接读取到GPU显存的带宽可以达到 20 GBps。
解决方案总体介绍
- GDS加速数据读取技术原理
GDS 重点在于优化数据在 GPU 卡和存储系统之间的搬运效率,使用 RDMA 技术来减少时间延迟和 CPU 消耗。 传统架构上,RDMA IO 主要使用在存储系统和CPU主存之间,但是,这对于GPU的计算效率不高,主要在于需要从CPU RAM 复制到 GPU RAM中,多走了一步。GDS 使用相同的 GPUDirect RDMA 技术允许远端存储系统数据直接搬运到GPU RAM上。如下图所示, 通过在VFS层嵌入内核模块 nvidia-fs.ko 和 nvidia.ko 来管理GPU 内存地址和CPU RAM及GPU RAM的IO操作,这扩展到了PCI总线允许数据在GPU和网卡之间搬运,元数据仍然存储在CPU RAM,而数据块则允许直接读取到GPU RAM。

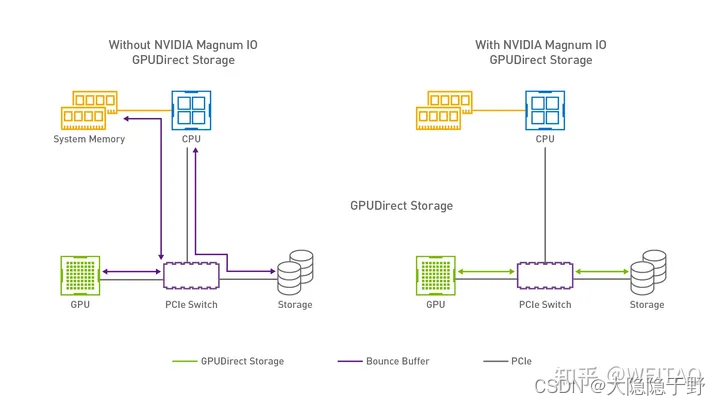
- 开源并行文件系统BeeGFS已支持GDS特性
BeeGFS 服务端和客户端均已支持GDS特性,满足了AI和HPC工作负载同时应用的场景。BeeGFS 跟其他文件系统类似,通过Linux VFS提供抽象层给上层应用提供标准接口。因此,VFS 收到数据 I/O 读写请求都会调用 BeeGFS I/O函数。
GDS-enabled BeeGFS 驱动模块 nvidia-fs 会主动区别传统 POSIX I/O 请求. 尽管BeeGFS支持通过RDMA传递数据,但是这两者之间的缓存传输机制大不相同。传统的 POSIX I/O 源自用户空间,通常由非 RDMA 感知的应用程序发出。因此,需要将保存要传输的数据的pages复制到内核空间缓冲区中,然后可以通过 RDMA 发送将其发送到存储服务器。如果用户空间应用程序想要从 BeeGFS 读取数据并在 GPU 上处理它,则需要将数据从内核空间中的 RDMA 缓冲区复制到用户空间缓冲区,然后需要再次复制到 GPU 内存。
另一方面,对于GDS,我们希望存储服务器能够直接读取或写入GPU内存中的缓冲区,该缓冲区通过网络接口上的DMA引擎开放。为了实现这一点,BeeGFS向客户端和服务器端代码添加了 RDMA 读写功能。现在可以使用客户端到服务器消息设置 RDMA 传输,该消息包含存储服务器要访问的内存区域的地址和密钥等必要信息。设置完成后,存储服务器可以读取和写入这些内存区域,而无需在 BeeGFS 客户端任何CPU参与。由于公开的缓冲区位于 GPU 内存中,因此在 GPU 上运行的应用程序可以在传输数据之前或之后立即访问数据。客户端不需要任何副本。
另一个重要先决条件,在 BeeGFS 中使用 GDS 实现最佳性能需要支持multirail网络。这意味着现在可以将 BeeGFS 客户端配置为在同一网络上使用多个支持 RDMA 的网络接口,并可以根据可用接口及活动状态的连接数自动平衡这些接口之间的流量。multirail的核心功能独立于GDS和nvidia-fs,因此即使不使用GDS也可以收益于multirail网络。启用GDS后,BeeGFS客户端可以调用nvidia-fs中的函数,以确定哪个网络设备将为特定GPU提供最快的路径,同时考虑到节点中的PCIe拓扑。
解决方案优势
GDS supported BeeGFS 实施部署参考:https://doc.beegfs.io/latest/advanced_topics/gds_support.html
本文的基准测试结果是使用两个 NVIDIA DGX A100 系统收集的,这些系统使用 NVIDIA Quantum 200Gb/s InfiniBand 交换机连接到单个 BeeGFS 集群中。在此构建块中,两台2U 服务器用于运行在 Linux HA 中配置的 BeeGFS 管理、元数据和存储服务,磁盘阵列 NetApp EF600 存储系统提供块存储。

我们关注GDS提供的相对性能提升,并没有试图展示一些性能提升是因为部署了大型BeeGFS文件系统或使用了许多GPU服务器。另外,此配置也没有利用 BeeGFS 中新的 multirail 网络,这将通过只部署一个来简化将所需的 IPoIB 子网数量。以下测试数据显示各种 GPU 计数和 I/O 大小的读取性能,没有 GDS(蓝条)和 GDS(橙色条):

GDS-enabled BeeGFS POC测试数据
原文链接:https://www.beegfs.io/c/beegfs-now-supports-nvidia-magnum-io-gpu/
常规HPC项目中基于BeeGFS并行存储系统项目建设参考架构与性能评估

根据 P5600 NVMe SSDs 技术指标,单块硬盘可以提供 1.7 GB/s 带宽,40块硬盘聚合带宽可以达到理论峰值 68GB/s,通过实际测试顺序写带宽达到 62GB/s,即理论数值的 92%。以下测试结果来自2U服务器配置2路HDR网络聚合带宽下的POC测试数据:
总结
无论作为普通HPC集群的并行文件系统,还是融合AI的存储系统,BeeGFS都表现出了极佳的性能优势。此外,极简的部署方案获得了广泛用户量,这体现在IO500列表里面。借助 NVIDIA GPU 渲染、模拟和加速技术,科学计算更加趋于可交互模式,例如,气候模拟本质上会产生大量的 3D 数据,但分析通常受限于 2D 预测。借助 NVIDIA Omniverse,大规模科学数据能够与电影级渲染功能融合,从而实现复杂气候现象的交互式探索。大规模科学数据的显示也离不开先进并行文件系统的支持,GDS-enabled BeeGFS恰恰解决了AI和HPC融合计算趋势下对科学计算和科学可视化共存所遇到的难题。
这篇关于GDS-enabled BeeGFS 人工智能并行存储解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




