本文主要是介绍TUI移植到Linux系统上使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
描述TUISYS (tuisys) - Gitee.com
下面主要讲述TUI在Ubuntu上移植运行,模拟在各种linux嵌入系统上的移植。
第一步:
阅读TUI快速上手<一>,安装好环境,把创建的demo工程放到Ubuntu home目录下面,修改.\home\demo\platform\linux\main.c文件如下:
#ifdef LINUX_GCC#include "tui.h"tui_obj_t * home_main_view_view_create(void);int main(int argc, char** argv)
{tui_start_init("/home/user/linux/demo/res.disk");//注意:使用自己的工程路径home_main_view_view_create();while (1) {tui_run_loop();}tui_end_uninit();return 0;
}
#endif
第二步:
make clean;make编译对应的linux平台:

第三步:
将得到可执行的生成的文件,sudo ./app_tui执行(由于使用了framebuffer需要管理员权限运行)
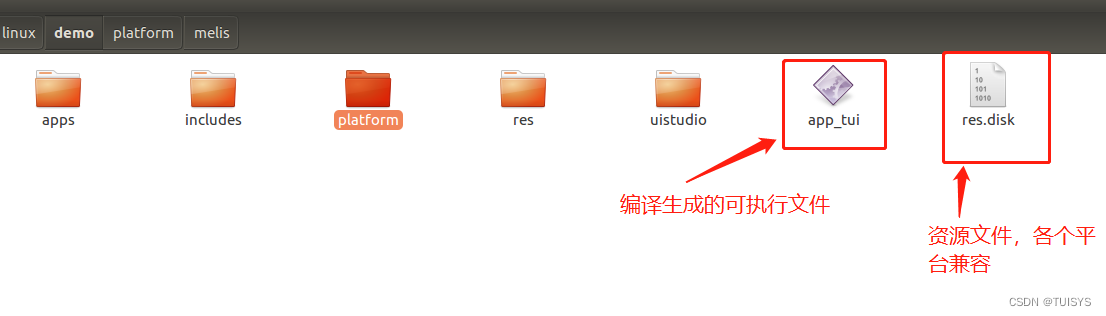
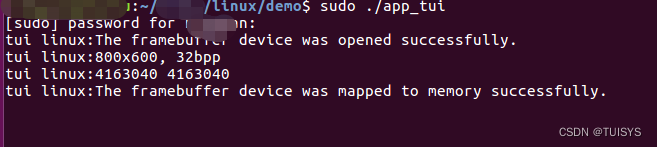
这时候要看到UI图,需要使用ctrl+alt+F1切换到命令行显示模式(恢复ctrl+alt+F7);
(新版本ubuntu20,更改为ctrl+alt+F6进入命令行,ctrl+alt+F1恢复)
注意:
在虚拟机Ubuntu下面使用framebuffer,运行需要管理员权限:sudo ./app_tui(一定要使用ctrl+alt+F1切换命令行显示模式)
这篇关于TUI移植到Linux系统上使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




