本文主要是介绍离线安装Cloudera Manager5.3.4与CDH5.3.4(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Cloudera Manager Server和Agent都启动以后,就可以进行CDH5的安装配置了。
这时可以通过浏览器访问主节点的7180端口测试一下了(由于CM Server的启动需要花点时间,这里可能要等待一会才能访问),默认的用户名和密码均为admin。
制作本地源
先下载CDH到本地http://archive-primary.cloudera.com/cdh5/parcels/5.3.4/,
这里需要下载三样东西,
首先是与自己系统版本相对应的parcel包,然后是manifest.json文件。
CDH-5.2.0-1.cdh5.2.0.p0.12-el6.parcel、
CDH-5.2.0-1.cdh5.2.0.p0.12-el6.parcel.sha1、
manifest.json下载完成后,将这两个文件放到master节点的/opt/cloudera/parcel-repo下(目录在安装Cloudera Manager 5时已经生成),注意目录一个字都不能错。
[root@hadoop1 parcel-repo]# pwd
/opt/cloudera/parcel-repo
[root@hadoop1 parcel-repo]# ll
总用量 1533188
-rw-r-----. 1 root root 1569930781 6月 27 11:49 CDH-5.3.4-1.cdh5.3.4.p0.4-el6.parcel
-rw-r--r--. 1 root root 41 6月 27 11:49 CDH-5.3.4-1.cdh5.3.4.p0.4-el6.parcel.sha
-rw-r--r--. 1 root root 42475 6月 27 10:18 manifest.json接下来打开manifest.json文件,里面是json格式的配置,我们需要的就是与我们系统版本相对应的hash码,因为我们用的是Centos6.5,所以找到如下位置:

在这个大括号的最下面找到“hash”所对应的值。

将“hash”的值复制下来,然后,将CDH-5.2.0-1.cdh5.2.0.p0.12-el6.parcel.sha1文件名改为CDH-5.2.0-1.cdh5.2.0.p0.12-el6.parcel.sha,将复制下来的hash值替换掉文本中的hash值,按理说应该是一致的。保存好了,这样,我们的本地源制作完成了。
然后的操作就是控制台按照步骤安装即可。
安装CDH
打开http://hadoop1:7180,登陆控制台,默认账户和密码都是admin,安装时选择免费版,之后由于cm5对中文的支持很强大,按照提示安装即可,如果系统配置有什么问题在安装过程中会有提示,根据提示给系统安装组件就可以了。
登录界面
选取安装版本
指定安装主机
选取本地Parcel包
接下来,出现以下包名,说明本地Parcel包配置无误,直接点继续就可以了。
集群安装
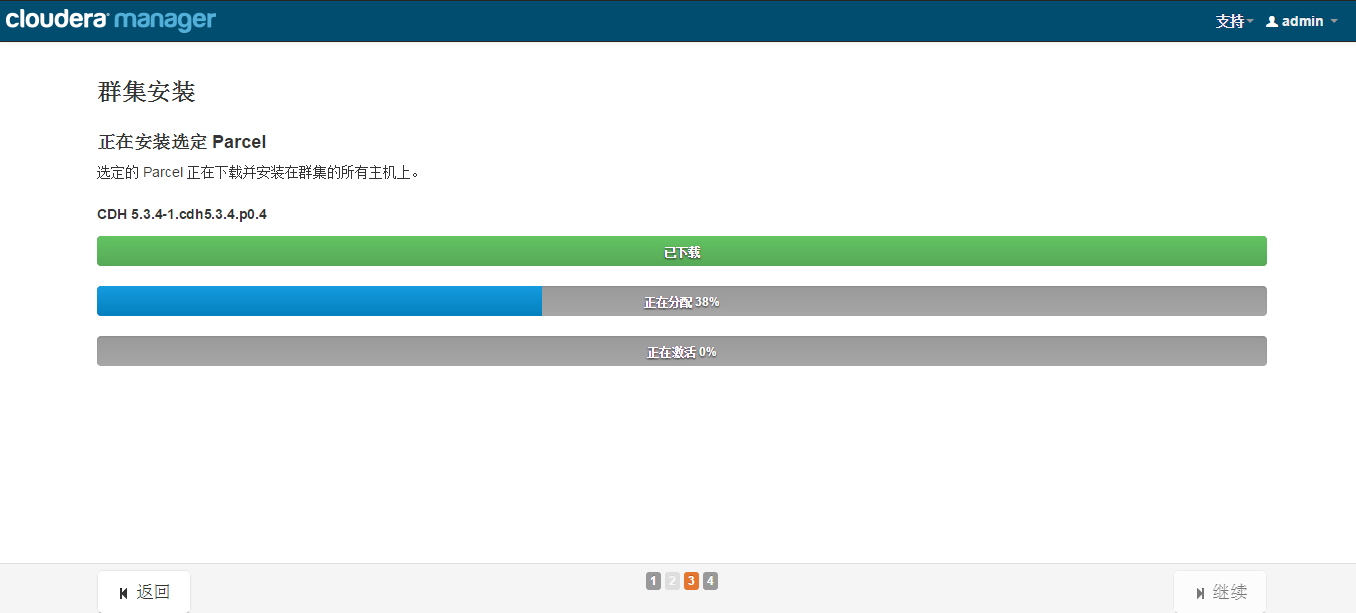
检查主机正确性
接下来是服务器检查,可能会遇到以下问题:
Cloudera 建议将 /proc/sys/vm/swappiness 设置为 0。当前设置为 60。
使用 sysctl 命令在运行时更改该设置并编辑 /etc/sysctl.conf 以在重启后保存该设置。
您可以继续进行安装,但可能会遇到问题,Cloudera Manager 报告您的主机由于交换运行状况不佳。
以下主机受到影响:
···在会受到影响的主机上执行echo 0 > /proc/sys/vm/swappiness命令即可解决。
选择安装服务
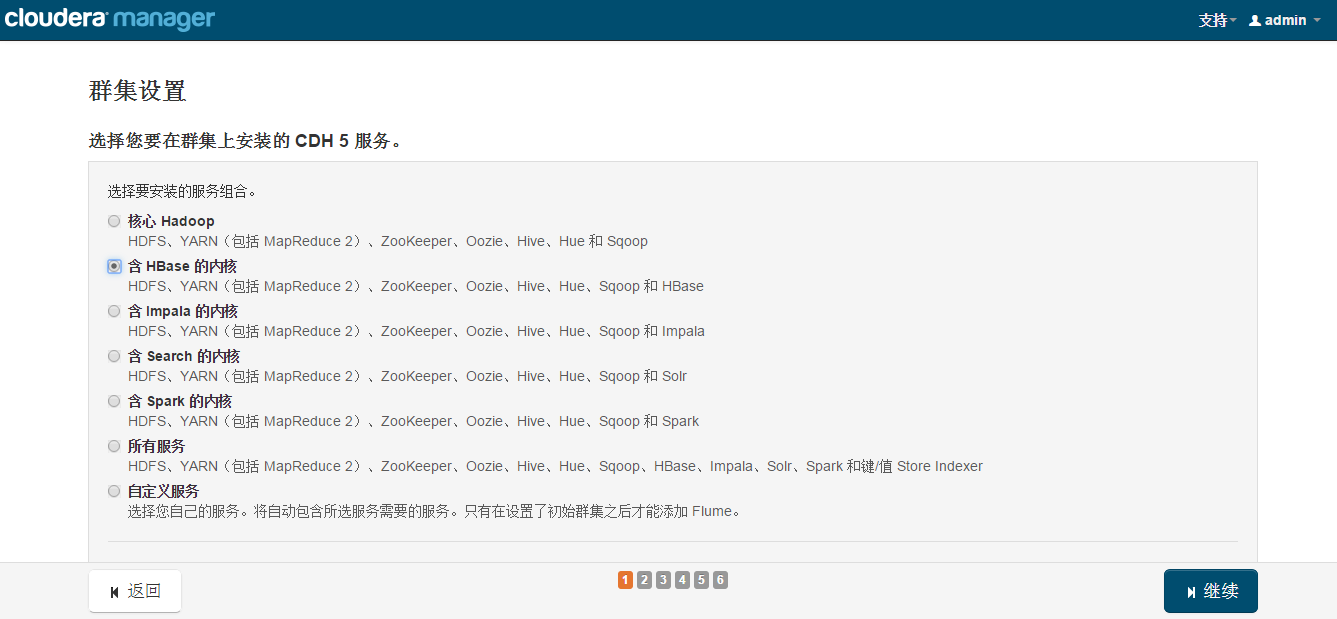
集群角色分配
一般情况下保持默认就可以了(Cloudera Manager会根据机器的配置自动进行配置,如果需要特殊调整,自行进行设置就可以了)。
集群数据库设置

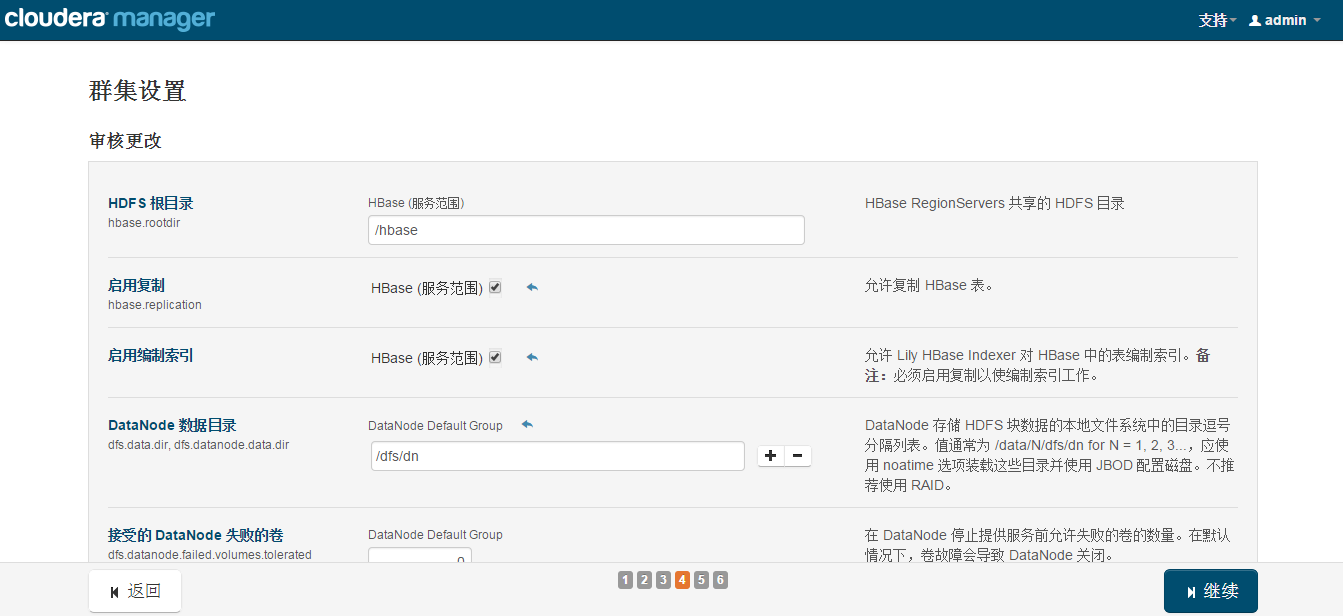
集群审查更改
如果没有其他需求保持默认配置。
终于到安装各个服务的地方了。
注意,这里安装Hive的时候可能会报错,因为我们使用了MySql作为hive的元数据存储,hive默认没有带mysql的驱动,通过以下命令拷贝一个就行了:
cp /opt/cm-5.3.4/share/cmf/lib/mysql-connector-java-5.1.25-bin.jar
/opt/cloudera/parcels/CDH-5.3.4-1.cdh5.3.4.p0.12/lib/hive/lib/之后再继续安装就不会遇到问题了。
经过漫长的等待后,服务的安装完成:
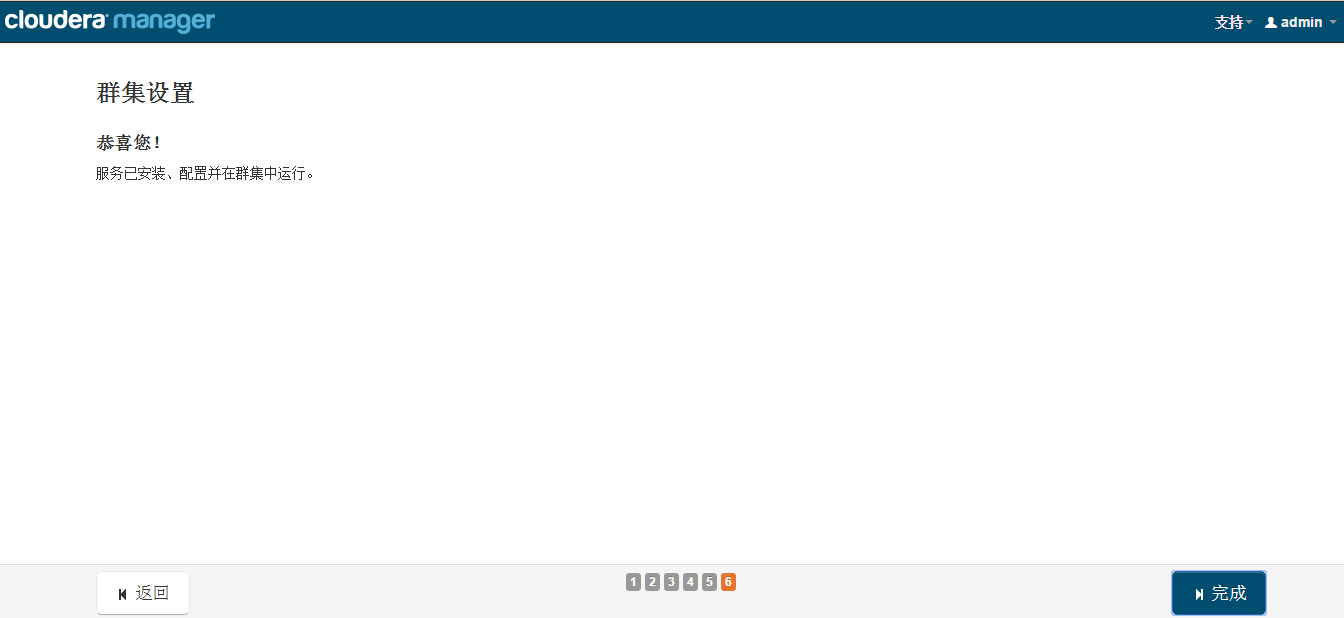
安装完成后,就可以进入集群界面看一下集群的当前状况了。
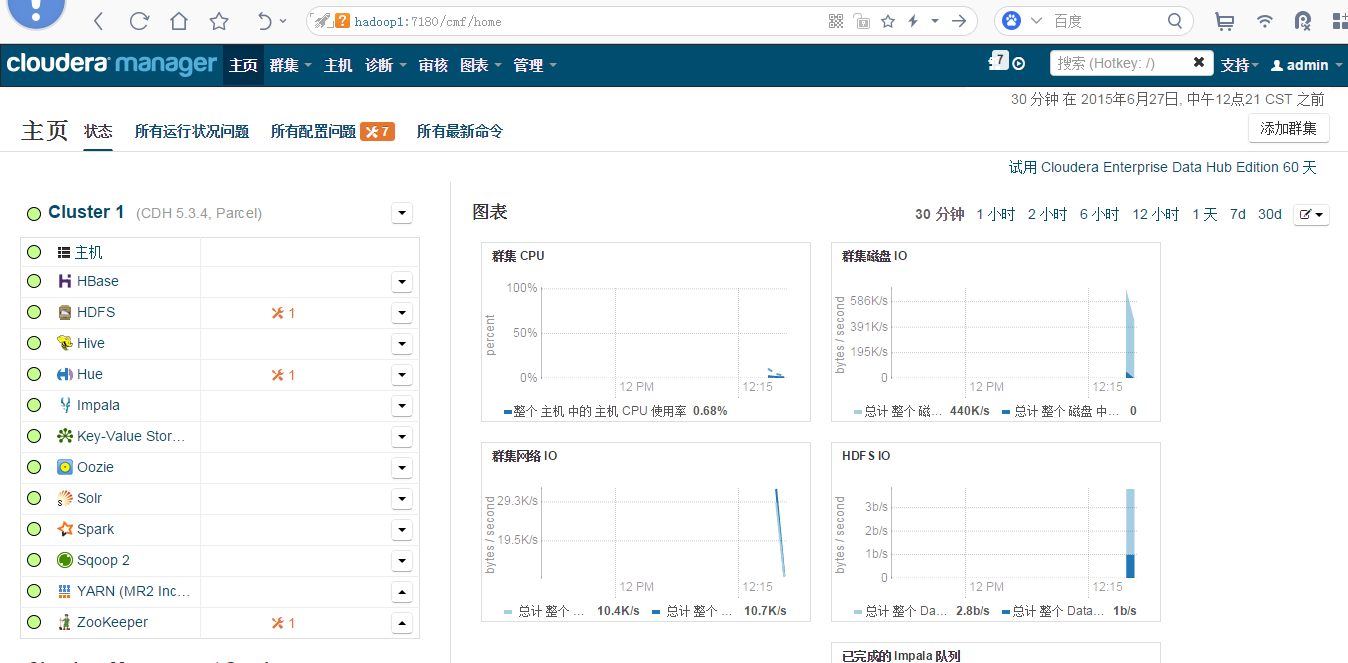
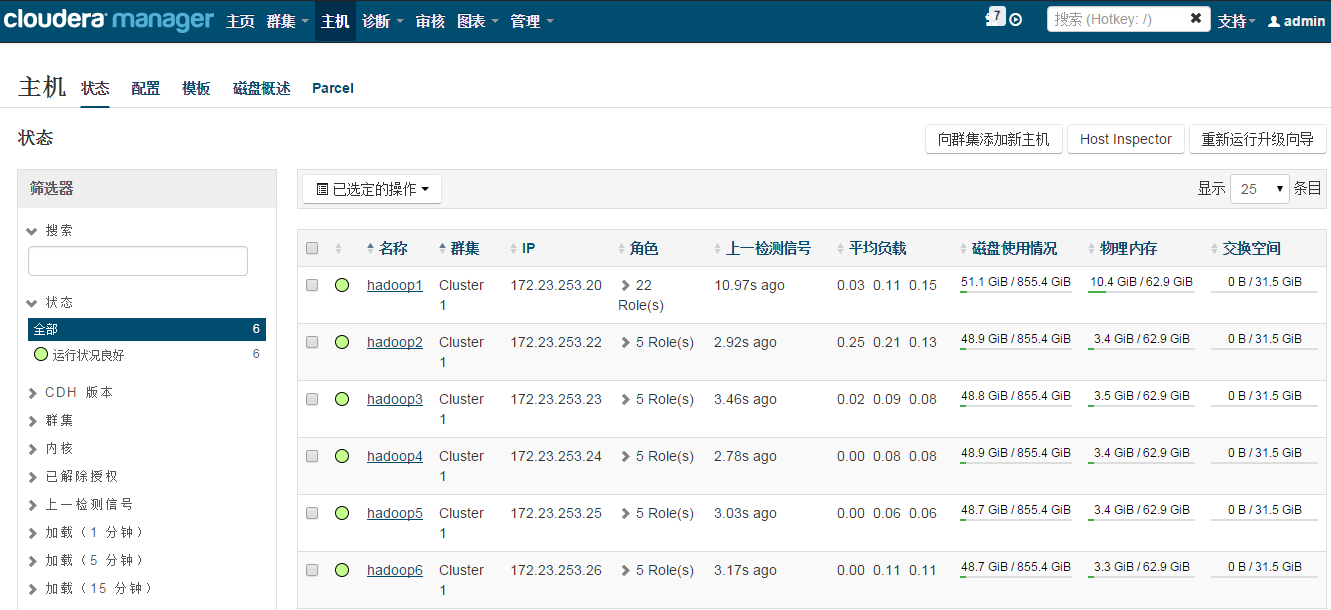
测试
[root@hadoop1 /]# su hdfs
[hdfs@hadoop1 /]$ yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 100 1000
Number of Maps = 100
Samples per Map = 1000
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Wrote input for Map #10····15/06/27 22:45:55 INFO mapreduce.Job: map 100% reduce 0%
15/06/27 22:46:00 INFO mapreduce.Job: map 100% reduce 100%
15/06/27 22:46:01 INFO mapreduce.Job: Job job_1435378145639_0001 completed successfully
15/06/27 22:46:01 INFO mapreduce.Job: Counters: 49Map-Reduce FrameworkMap input records=100Map output records=200Map output bytes=1800Map output materialized bytes=3400Input split bytes=14490Combine input records=0Combine output records=0Reduce input groups=2Reduce shuffle bytes=3400Reduce input records=200Reduce output records=0Spilled Records=400Shuffled Maps =100Failed Shuffles=0Merged Map outputs=100GC time elapsed (ms)=3791CPU time spent (ms)=134370Physical memory (bytes) snapshot=57824903168Virtual memory (bytes) snapshot=160584515584Total committed heap usage (bytes)=80012115968Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=11800File Output Format CountersBytes Written=97
Job Finished in 50.543 seconds
Estimated value of Pi is 3.14120000000000000000
查看mapreduce作业
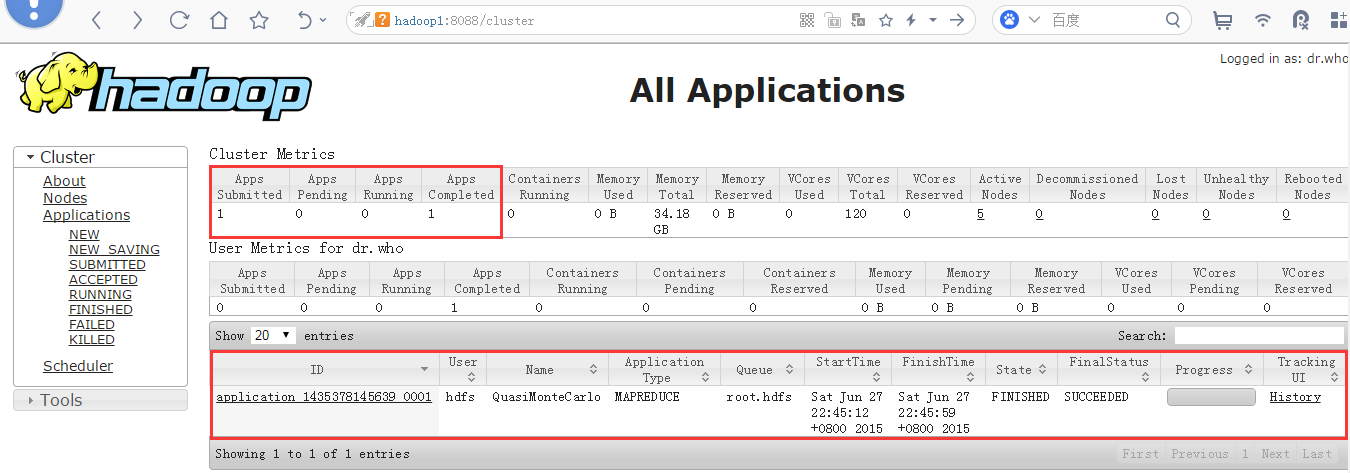
检查Hue
首次登陆Hue会让设置一个初试的用户名和密码,设置好,登陆到后台,会做一次检查,一切正常后会提示。

到这里表明我们的集群可以使用了。
这篇关于离线安装Cloudera Manager5.3.4与CDH5.3.4(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








