本文主要是介绍Python正则表达式进阶-零宽断言,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python正则表达式进阶-零宽断言
1. 什么是零宽断言
有时候在使用正则表达式做匹配的时候,我们希望匹配一个字符串,这个字符串的前面或后面需要是特定的内容,但我们又不想要前面或后面的这个特定的内容,这时候就需要零宽断言的帮助了。所谓零宽断言,简单来说就是匹配一个位置,这个位置满足某个正则,但是不纳入匹配结果的,所以叫“零宽”,而且这个位置的前面或后面需要满足某种正则。
2、不同的零宽断言
零宽断言:正向和反向两类,每类又分为:预测先行和回顾后发;

正预测先行:简称正向先行断言,语法:(?=exp),它断言此位置的后面能匹配表达式exp,但不包含此位置;
如:a(?=\d),返回匹配字符串中以数字为结尾的a字符。
正回顾后发:简称正向后发断言,语法:(?<=exp),它断言此位置的前面能匹配表达式exp;
如:(?<=\d)a,返回匹配字符串中以数字为开头的a字符。
负预测先行:简称反向先行断言,语法:(?!exp),它断言此位置的后面不能匹配表达式exp;
如:a(?!\d),返回不匹配字符串中以数字结尾的a字符。
负回顾后发:简称反向后发断言,语法:(?<!exp),它断言此位置的前面不能匹配表达式exp;
如:a(?<!exp)a,返回不匹配字符串中以数字开头的a字符。
3、零宽断言的实践与总结
示例:提取<div>Hello World</div>中Hello World
目标字符串:Hello World
根据以上所说,当我们需要提取字符串的时候,可以用断言,思路如下:
首先,目标字符串是hello world,那么它可以归纳为 .* ;
其次,目标字符串前面有<div>,既然是前面有,那么根据四种断言的含义,容易得出用正向后发断言(?<=exp),将它放在目标字符串前面,得到(?<=<div>).*,进一步可以将div归纳为[a-zA-Z]+,从而得到(?<=<[a-zA-Z]+>).*;
最后,目标字符串后面有</div>,既然是后面有,那么根据四种断言的含义,容易得出用正向先行断言(?=exp),将它放在目标字符串后面,从而得到(?<=<[a-zA-Z]+>).*(?=</[a-zA-Z]+>);
进一步的,我们发现前后两个断言中都有[a-zA-Z]+,可以使用分组来避免书写重复的内容:(?<=<([a-zA-Z]+)>).*(?=</\1>),当然也可以使用命名分组,这里就不展开了。
说到这里,我归纳出了几句书写断言的口诀:
前面有,正向后发(?<=exp),放前面;
后面有,正向先行(?=exp),放后面;
前面无,反向后发(?<!exp),放前面;
后面无,反向先行(?!exp),放后面。
请记住,这个前面和后面是针对目标字符串,也就是你要提取出来的字符串而言的。
4、实战:
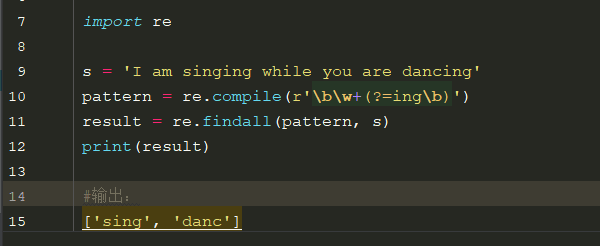
4.1、正向先行(?=exp):获取字符串中以ing结尾的字符:
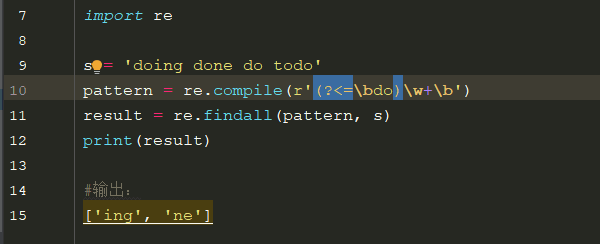
4.2、正向后发(?<=exp):获取字符串中以do开头的单词后半部分:
4.3、反向先行(?!exp):匹配出字符串中不是以ing结尾的单词:

此处有雷,如果字符串变成“do run going hing”你再试试看,此处有待解决。
4.4、反向后发(?<!exp):匹配字符串中不以do开头的单词:

此处有雷,同上
总结:主要原因是因为反向断言不支持匹配不定长的表达式;
4.5、正向先行后发断言结合应用:字符串时ip地址,获取整数部分

这篇关于Python正则表达式进阶-零宽断言的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





