本文主要是介绍使用神卓互联配置内网访问(内网穿透)教程(超详细,简单),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天以web应用,畅捷通作为演示部分。
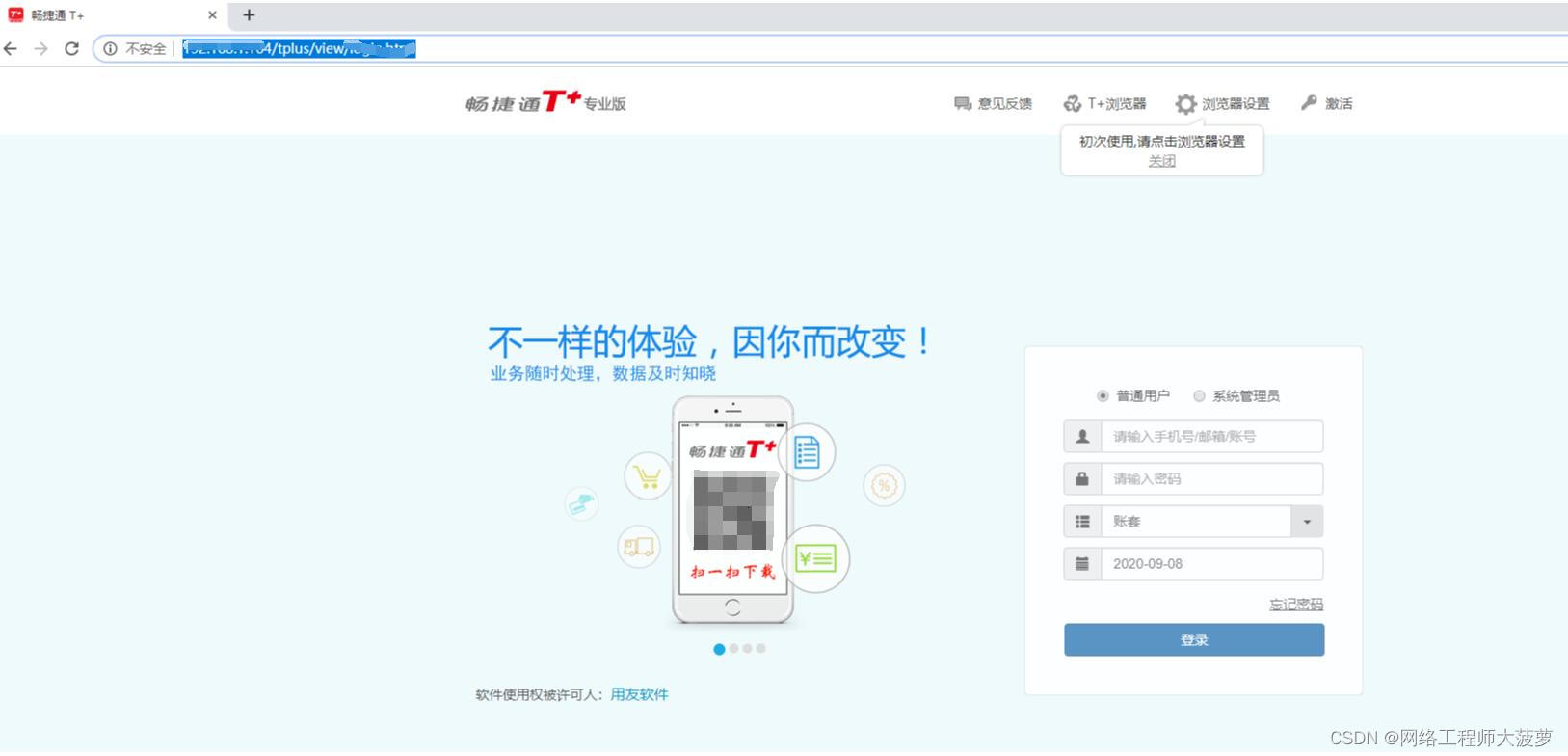
可以使用专业的神卓互联内网穿透,将公司畅捷通T+主机 固定一个访问地址,这样可以通过宽带网络就可以在家或出差随时随地访问畅捷通。
使用神卓互联配置远程访问畅捷通方法。
一、下载神卓互联客户端

二、点击安装包-安装客户端
三、安装完成,需要进行设置
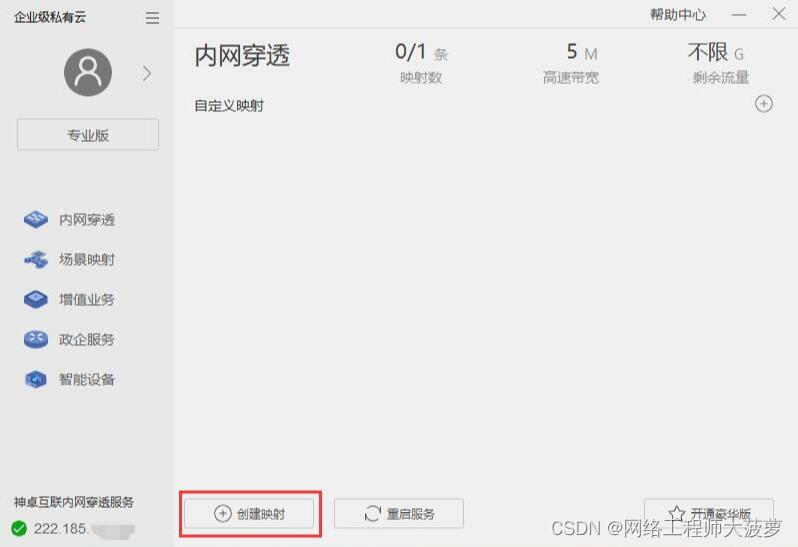
1.点击创建映射
2. 填写应用名称:畅捷通
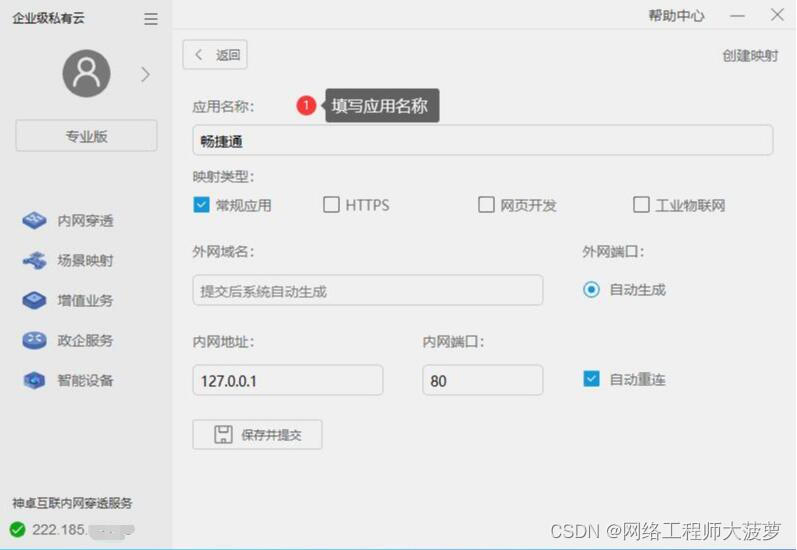
3. 是和畅捷通 主机安装在同一台电脑上,其他选择选择默认
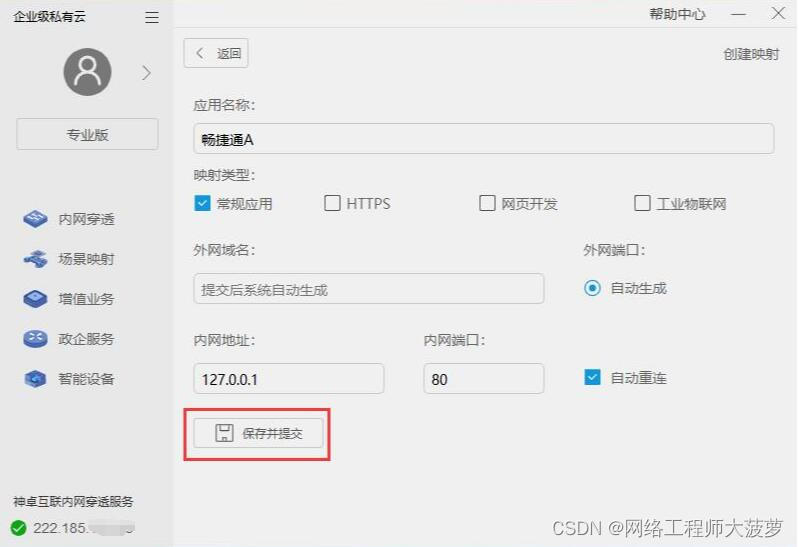
4.点击保存提交
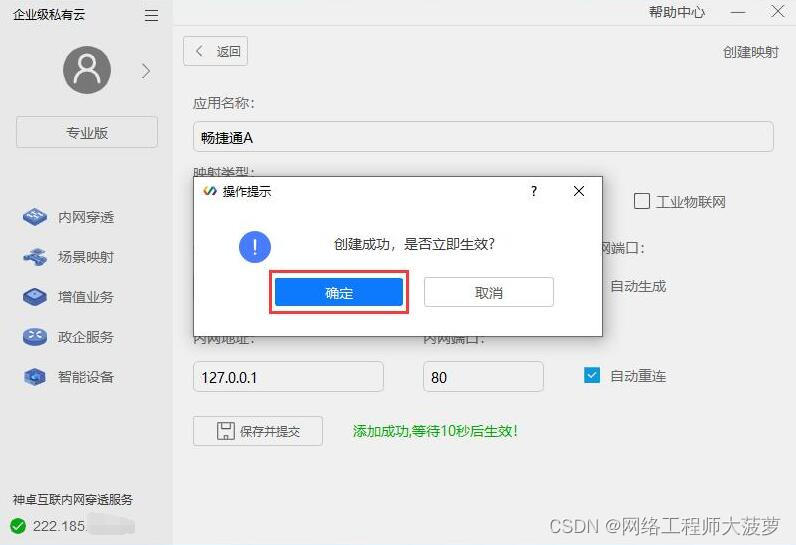
5. 创建完成后,我们得到一个由神卓互联系统自动生成的一个 固定外网访问地址。
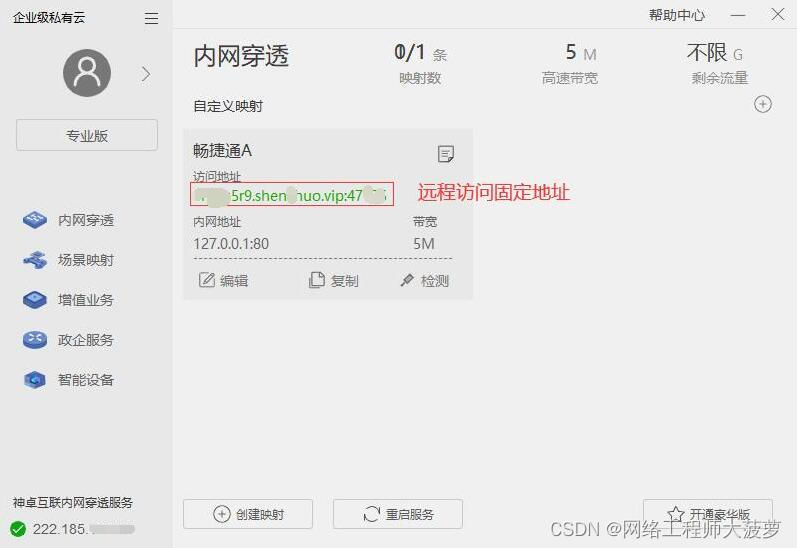
6. 可以选择复制这个 固定访问地址,将这个地址放入浏览器搜索框里。
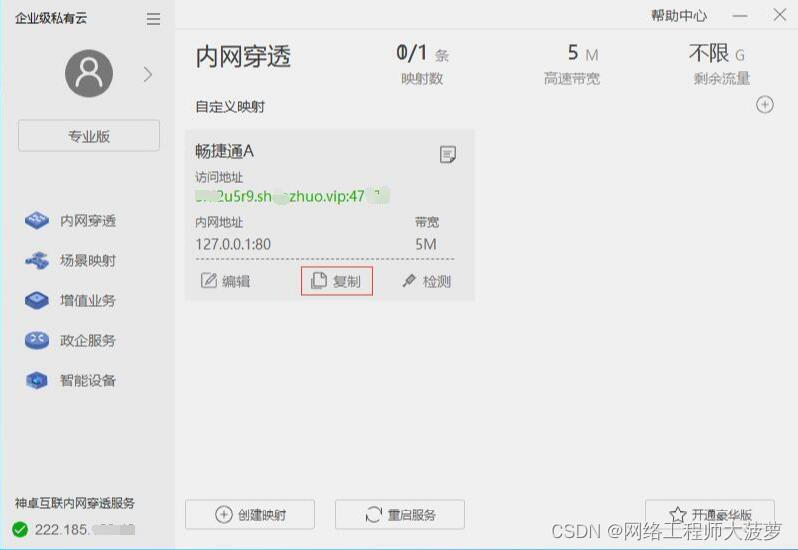
7. 这样就可以使用浏览器远程访问畅捷通了。
使用神卓互联内网穿透系统自动生成的固定公网访问地址,就可以实现远程发问了。
这篇关于使用神卓互联配置内网访问(内网穿透)教程(超详细,简单)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






