本文主要是介绍系统设计-后台系统的伸缩性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
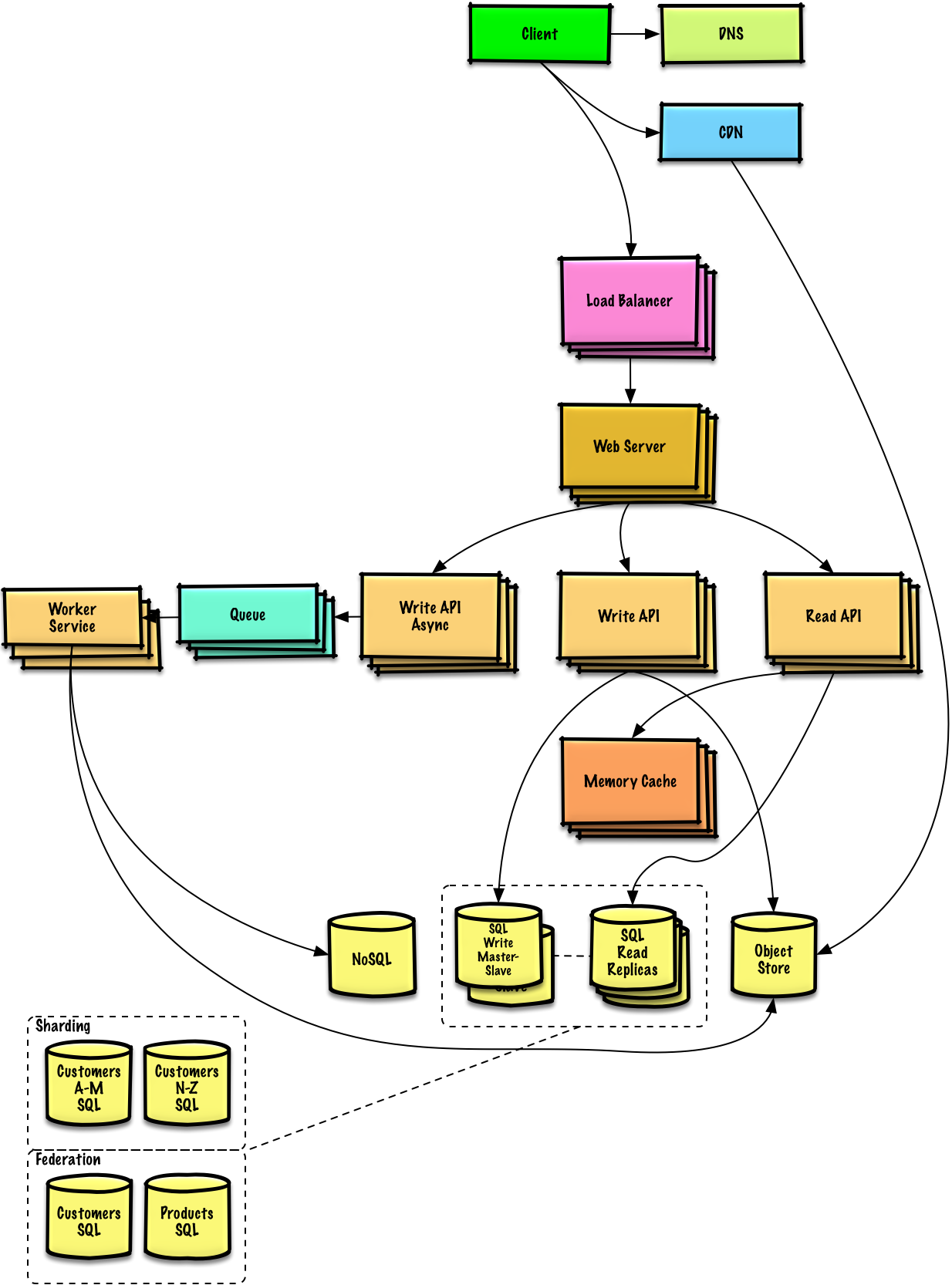
1、软件分层
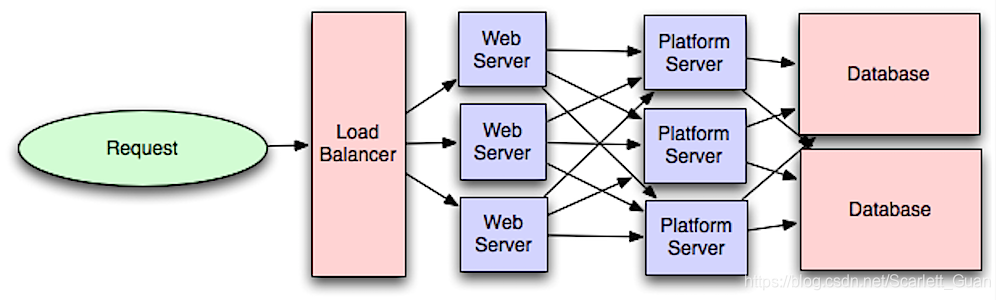
分层思想很普及,把数据流拆成几段,比如接入层(load balancer+webserver),应用服务层(platformserver),数据存储层(数据库database、nosql)。
2、伸缩性定义
一种设计目标,使得系统通过加硬件(堆机器)能够解决各种业务问题,不存在性能瓶颈问题。比如微信红包,接入层、plaform层、数据存储层的数据通道是否够宽,扛得住上亿人同时在线的请求速度?
2.1 接入层(loadbalancer + webserver)
请参考一个客户端请求到后台的流程:tcp-ip 7层网络通信、负载均衡、API层、数据库中负载均衡部分的内容
(loadbalancer≈haproxy) + (webserver≈nginx)
haproxy+nginx 增加带宽容量的对策:加更多域名、更多转发机器
负载均衡在有状态情况下,怎么去堆转发机器?比如用户uid=a的所有请求必须转发到某个服务器b上。请参考一致性hash
2.2 Platform层
单例:某个程序,一个时刻所有请求都打到一台机器上,由于一台机器cpu/内存有限,会导致单例性能瓶颈。比如设计了一个请求计数器,让所有请求都得经过这个机器上这个进程,在内存里+1,最后得到结果。
正确做法如下:
(1)各个机器分别计数,然后查询的时候查各个机器结果相加,尽量做分布式(让请求均匀打在各个分布式机器上),避免单例。
(2)尽量只用这一层算,不要用这一层来存具体的数据结果,存数据的话,送到下一层的专门的数据存储层。原因是:业务层的处理逻辑比较多,如果要是再用来维护数据的话,一方面很累,另一方面是数据存储层会有通用的数据接口来存各种各样的数据,没必要用这层来存。存储计算分离,存储统一,计算多样。
2.3 数据存储层
做后台一般不会专门让设计存储层,有很多现成的模型。请参考一个客户端请求到后台的流程:tcp-ip 7层网络通信、负载均衡、API层、数据库中数据库部分的内容。
(1)读写分离,增加读实例。
读写分离来确保写和读效率都很高。写数据因为要确保数据不丢失,所以要写入硬盘,机械硬盘有一个摆臂,只适合采用log(尾部能添加的文件)的方式顺序写,摆臂不需要来回移动,速度最快。读数据需要随机读,硬盘访问数据比较慢,摆臂来回移动效率低。实际上这里面有三个进程:log方式顺序写,key-value方式随机读,把顺序写转化为随机读(log格式转为key-value格式)。
增加读实例:实际应用中,往往有很多场景,写数据次数很少,读数据次数很多。比如说写博客只需要写一次,但有可能同时有很多人在读博客。

redis这种非关系型数据库相对来说好做伸缩,可以对key做哈希,分片到某一台机器上。
关系型就比较难做伸缩,俗称分库(竖直拆分)分表(水平拆分):
-
把库拆成多个库(每个库有自己的master/slaves机器集群),一个库里面有很多细小的业务,按照每个小业务来拆。
-
把表拆成多个表,原本只需要查一张表,现在需要查10张表,而且有的表是不能拆的。
每个库里的小业务可以拆到不同机器上。但是一个表拆开的不同表必须放在同一台机器上,因此拆库比拆表性能好点。
这篇关于系统设计-后台系统的伸缩性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







