本文主要是介绍首发 | FOSS分布式全闪对象存储系统白皮书,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、 产品概述
1. 当前存储的挑战
随着云计算、物联网、5G、大数据、人工智能等新技术的飞速发展,数据呈现爆发式增长,预计到2025年中国数据量将增长到48.6ZB,超过80%为非结构化数据。
同时,数字经济正在成为我国经济发展的新引擎,数据已经成为企业的核心生产要素,数据即价值。新技术新应用不断产生急剧增长的海量数据,数据的价值越来越高,对存储系统的可靠性、安全性、可用性、性能、成本、运维的要求也越来越高,给存储系统提出了巨大的挑战:

以上挑战和刚需说明,新一代存储系统不光要面向传统的数据可靠性、服务可用性、性能等维度,超大存储量、长期存储经济性、系统水平线性扩展性、可交付的运维等维度成为新的重点。
这驱使新一代存储系统必然走向规模化、集成化、存算分离的分布式scale-out云存储架构,提供可交付的简洁易用的运维平台,让客户自己负责运维,安心使用。
2. FOSS的特点
大道云行对象存储FOSS,是采用先进的分布式全闪架构的信创云存储系统,设计为超大规模数据长期、可靠、绿色节能、高性能存取。
FOSS适用于包括广电媒资、备份归档、远程容灾、视频监控、人工智能、大数据分析、数据湖等大规模非结构化数据存取应用场景,特别是数据量大、吞吐高,成本敏感的需求。
| FOSS特点详解 | |
| Share Everything架构 | 存储后端网络share everything架构,支持NVMe-oF,支持分布式无状态微服务安全访问存储。 |
| 信创存储 | 全自主知识产权国产分布式全闪存储软件和国产闪存的结合。 |
| 全闪架构,超高性能,数据量,性能的水平线性扩展 | 亚毫秒级延迟,单zone-百PB级空间,百GB级吞吐,百万级IOPS。 |
| 绿色节能 | 节能调度算法使得多数SSD的大部分时间处于低功耗状态(单片SSD<0.5w)。 |
| 全闪优化设计使得SSD使用时间长,成本低 | 数据按时间聚合,采用全域GC和磨损平衡等设计,极大降低SSD写放大,提高SSD使用寿命。实现大尺度QLC SSD的高密度使用,降低单位成本。 |
| 长期可靠 | 数据静默错误保护;智能化的介质和数据的巡检、健康扫描、Rebuild恢复。 对数据和介质长期可靠做了慎密的数据保护、监测、扫描、恢复、迁移等运维规划。 |
3. FOSS的核心能力
在线数据的性能和延迟,离线数据的规模和成本。
使用FOSS,意味着客户可以将大部分数据以离线数据的成本保存到在线系统,数据长久在线。
二、 产品架构
1. 网络架构
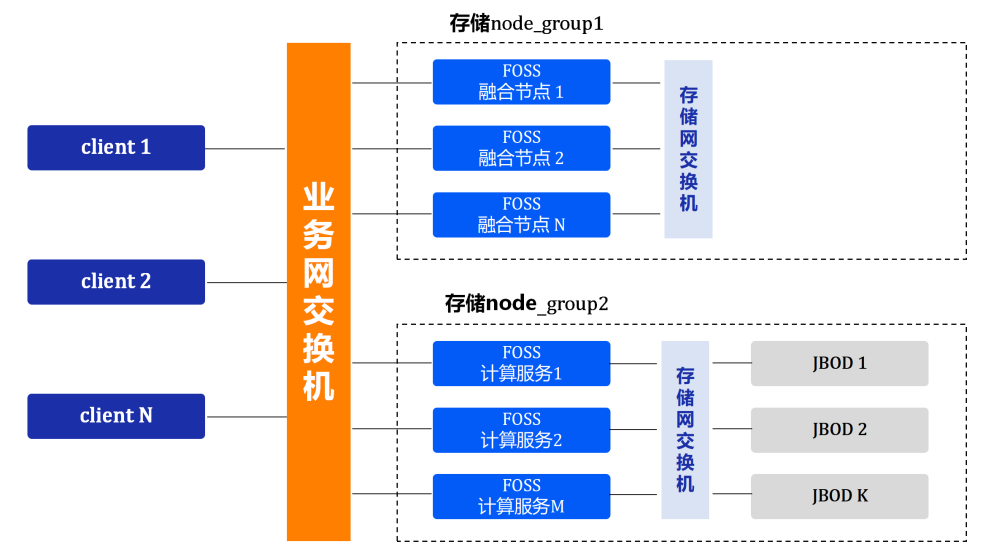
系统采用扁平的二层网络,易于部署和管理,支持对存储集群节点进行分组,支持跨组数据互访。
- 业务网
业务网可以是IP/IB/RoCE;
每组业务网的计算节点都互通。
- 存储后端网
存储后端网可以是IP/IB/RoCE;
存储后端网支持按分组进行扩展,不同分组之间存储网不通,可以通过业务网进行转发;
分组设计有利于存储网络简单的水平扩展,而不增加组网的复杂度。
一个zone规模的上限,取决于业务网的规模,即计算节点总数;存储网可任意水平扩展,但总规模会受限于连接存储网的计算节点总数。
一般的,一个zone支持100GB的业务网,200个计算节点,20个存储网分组(每分组10P存储空间);则整个zone支持100GB带宽,200PB存储空间。
2. 软件架构
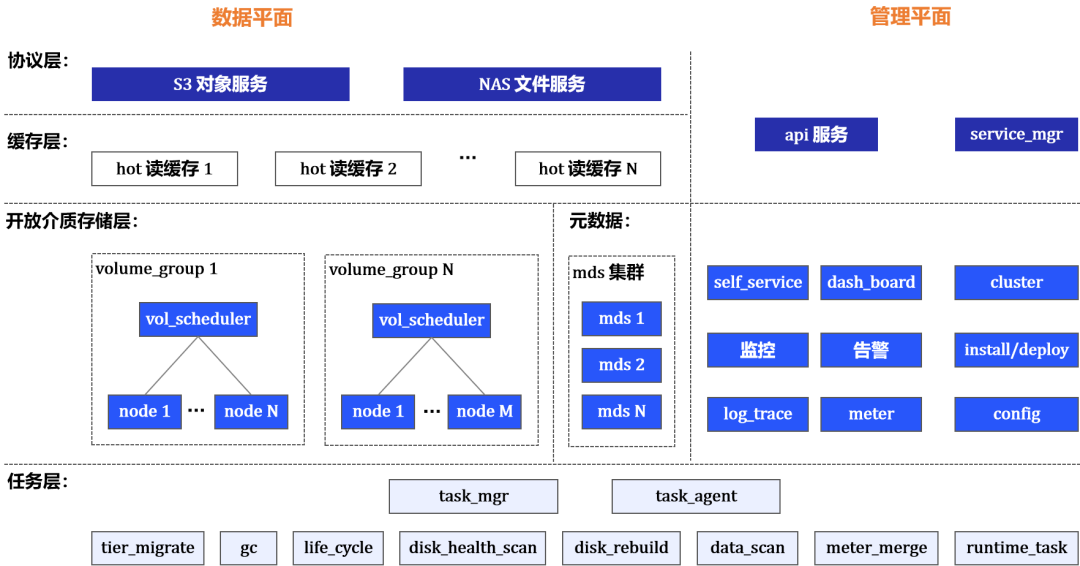
协议层
对外提供s3服务和nas服务。
缓存层
数据分片通过读缓存层降低延迟,满足低读延迟的场景需求。
开放介质存储层
-- volume
开放介质存储(OpenMediaStorage - OMS)层将块设备(disk)的trunk封装为跨节点的、冗余算法(纠删/副本)保护的volume,提供volume的装配、分配和读写接口。
OMS层开放式的直接存取disk,支持:主机Local_disk、SAS/NVMe-oF enclosure disk、块存储系统的LUN(FC/iSCSI/NVMe-oF)。
-- volume_group
volume按分组进行管理、调度和使用。分组用于支持多租户。
volume_group由调度器和node集群组成。
-- node
node代表了挂载的disk的集合,对应实体存储节点主机disk组,或NVMe-oF 盘柜disk组,或块存储划分的Lun组。
node作为disk的IO控制器,提供发现、挂载、访问disk的接口。
-- 调度器负责volume装配和分配
装配:
- 按node类型树进行类型分组
- 按空间平衡+擦写次数平衡选择node
分配:
- 按类型聚合
- 数据分片MVCC+基于租约的volume_range保护机制
元数据
mds集群提供分布式元数据服务,支持最终一致性事务,在线线性扩展。
任务层
包含GC、Disk_Rebuild、数据迁移、数据均衡、数据/介质健康扫描、生命周期、配额、计量归并等任务。
任务通过管理器Task_mgr,分发到Task_agent分布式并行执行。
task_mgr进行任务策略配置、调度、资源使用控制。
Service_mgr
服务部署、升级、配置,单例服务故障转移,集群服务扩展等。
三、产品特性
1. 分布式元数据
很多存储系统采用无元数据服务架构,比如一致性Hash。无元数据服务架构在超大规模分布式系统中存在许多缺点:
-
无法在统一的逻辑上管理元数据,不支持事务,会导致很多一致性问题。
-
没有元数据的范围查询能力,查询范围会放大到整个集群,导致海量对象场景下元数据列举开销大性能差。
-
rebalance过程复杂,要扫描所有需rebalance的数据进行处理并完成状态转换,且网络故障、节点临时离线和永久离线等会进一步增加rebalance复杂度。
FOSS采用分布式元数据服务架构:
-
元数据服务线性平滑,网络故障和节点故障不影响服务的可用性
-
元数据三副本冗余
-
支持热点消除(主键单调递增的元数据,采用shard_bit打散)
-
支持高性能的事务聚合批处理(batch和scan)
-
低延迟(亚毫秒级)
依靠分布式元数据服务,FOSS简洁高效的实现了单桶无限数量对象、快速对象列举、volume调度、全域GC和磨损平衡等高级功能。
2. 存储冷热分层
FOSS存储分层设计的主旨,是为了同时满足超高性能和超大容量需求。FOSS的数据存储包括2层:
(热)高性能层
- 热volume_group
- 读缓存集群
高性能层满足要求极低延迟的高性能场景。高并发写入通过写请求聚合提高IOPS;小文件的低延迟读取,通过热数据读缓存优化。
通常,变冷的数据会迁移到大容量层。只需要高性能层的特例客户,也可以独立使用高性能层,不部署大容量层。
(冷)大容量层
- 冷volume_group
大容量层必须依赖高性能层存在。tier_migrate任务将高性能层的数据批量迁移到冷volume 。
批量迁移采用顺序大IO写入,使大尺度SSD可以得到优化使用。
3. 资源多租户
S3服务资源多租户
通过service_mgr配置租户独占的S3服务资源,为特定租户建立专属的s3_serv_group 。
通过service_mgr配置s3_serv_group和volume_group的映射关系。
存储资源多租户
bucket可以代表租户的分类存储空间,多租户的空间管理通过bucket的存储策略进行。
支持设置bucket的数据放置策略(对应的volume_group),比如可指定bucket放置到特定性能分类(SSD|HDD)的volume 。
4. 优秀的扩展性
FOSS支持容量和性能的横向线性扩展,元数据的横向线性扩展,通过分布式元数据服务mds实现:
-
mds_kv集群的扩展
mds_kv采用全局字典序range方式进行key的sharding;支持在线增加kv节点,IOPS随kv节点个数线性增长。
-
mds事务服务集群的扩展
mds事务服务集群,采用配置订阅方式扩展;支持在线增加事务服务,IOPS随事务服务个数线性增长。
数据存储的横向线性扩展,通过开放介质存储(OpenMediaStorage-OMS)层实现:
-
存算分离的架构下,数据存储的横向扩展简化为存储后端网的横向扩展。
-
存储后端网按分组进行水平扩展,每个分组后端网独立组网,扩展简单。
增加volume_group中node,即增加了分组的存储量和IOPS;当volume_group内的扩展到达上限后,可以通过新建volume_group进行扩展。
5. 绿色节能
FOSS通过数据写入volume分配算法和分类聚合算法,实现(冷)数据层的disk节能。
volume分配算法
数据写入分配volume时,在满足性能吞吐需求的条件下,一段时间内分配的volume使用尽量少的同一批disk。(其他disk这段时间处于节能状态,存储规模越大,节能比例越高)
分类聚合算法
应用按时间批量读取数据的时候,因为应用写入数据按时间聚合,读关联的disk和写入时是相同的,同样只是少数的一批disk。
四、产品愿景
以全闪绿色节能信创存储的创新技术:
为客户提供自运维的私有云存储,应存尽存;
在企业存储领域促进国产SSD对进口HDD的替代;
作为智能云平台的存储底座,助力数据处理的智能化,发掘数据的真正价值。
《FOSS全闪对象存储技术白皮书》详见官网大道云行 TaoCloud - 新一代全闪软件定义存储领导者 (taocloudx.com)
这篇关于首发 | FOSS分布式全闪对象存储系统白皮书的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




