本文主要是介绍NCL论文简单解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NCL
Nested Collaborative Learning for Long-Tailed Visual Recognition
引言
- 论文链接
- 官方代码
先看一波实验结果(数据来自paperswithcode,截图时间2022年5月10日)
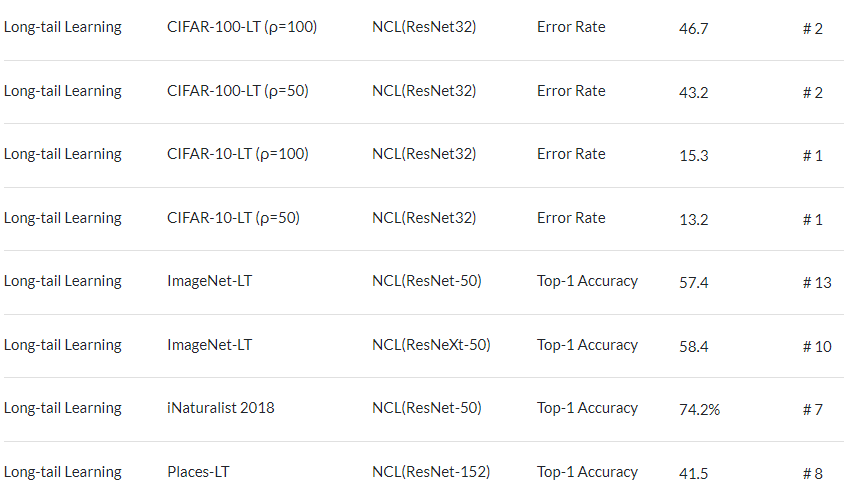
可以看到,两个第一,两个第二,效果海星。
请注意,下文中,多专家就是多模型
摘要
提出了一种嵌套协作学习(NCL),它通过协作学习多个模型来解决这个问题。 NCL由两个核心组件组成,即嵌套个体学习(NIL)和嵌套平衡在线蒸馏(NBOD),分别侧重于单个模型的个体监督学习和多个模型之间的知识转移。
为了更彻底地学习表示,NIL 和 NBOD 都以嵌套的方式制定,其中不仅从完整的角度对所有类别进行学习,而且从部分角度对一些困难的类别进行学习。关于部分视角的学习,我们通过使用提出的硬类别挖掘(HCM)专门选择具有高预测分数的负类别作为硬类别。在 NCL 中,两个角度的学习是嵌套的、高度相关的和互补的,不仅有助于网络捕捉全局和鲁棒的特征,而且捕捉到细致的区分能力。此外,自监督进一步用于特征增强。
广泛的实验证明了我们的方法的优越性,无论是通过使用单个模型还是集成模型,都优于最先进的方法。
正文
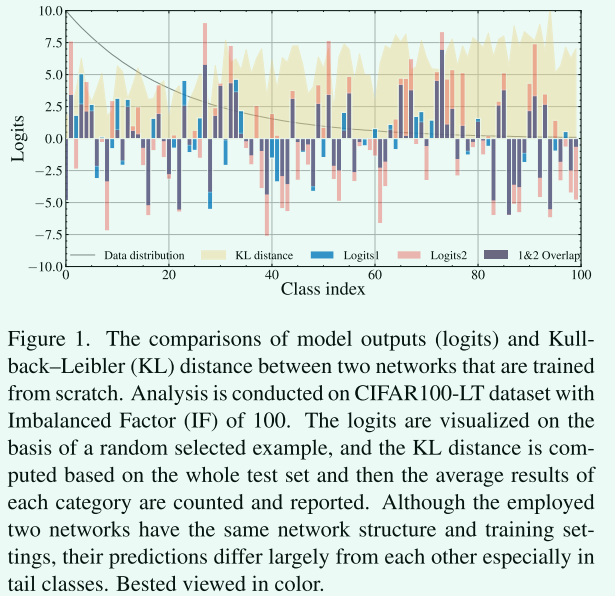
受到如图1所示的简单实验的启发:不同的网络变化很大,特别是在尾部类中,即使它们具有相同的网络结构和相同的训练设置。这意味着学习过程中的巨大不确定性。减轻不确定性的一种可靠的解决方案是通过多个专家进行协作学习,即每个专家可以是其他人的老师,也可以是学生来学习其他人的额外知识。
基于此,我们提出了一种用于长尾视觉识别的嵌套协作学习 (NCL)。NCL包含两个主要的重要组成部分,即嵌套的个人学习 (NIL) 和嵌套的平衡在线蒸馏 (NBOD),前者旨在增强每个网络的区分能力,而后者则在任何两个专家之间协作地转移知识。
NCL和NBOD都以嵌套方式执行,其中NCL或NBOD从所有类别的完整角度进行有监督的学习或蒸馏,并且还从专注于某些重要类别的部分角度来实现。此外,我们提出了一种硬类别挖掘 (HCM) 来选择硬类别作为重要类别,其中硬类别被定义为不是真实类别但具有较高预测分数,容易导致分类错误的类别。
不同角度的学习方式是嵌套的,相关的和互补的,这有助于全面的表征学习。此外,受自监督学习的启发 ,为每个专家采用了一个额外的移动平均模型来进行自监督,从而以无监督的方式增强了特征学习。
在提出的 NCL 中,每个专家都与其他专家协作学习,允许任何两个专家之间的知识转移。 NCL 促进每个专家模型达到更好甚至可与集成模型相媲美的性能。因此,即使使用单个专家,它也可以胜任预测。我们的贡献可以总结如下:
- 提出了一种嵌套协作学习(NCL)来同时协作学习多个专家,这使得每个专家模型都可以从其他人那里学习额外的知识
- 提出了嵌套个体学习(NIL) 和嵌套平衡在线蒸馏(NBOD) 来从对所有类别的全面视角和专注于困难类别的部分视角进行学习。
- 所提出的方法在包括 CIFAR-10/100-LT、Places-LT、ImageNet-LT 和 iNaturalist 2018 在内的五个流行数据集上获得了优于现有技术的显着性能。
相关工作的缺点
- 类重新平衡提高了整体性能,但通常会牺牲头部类的准确性。
- 多阶段训练方法可能依赖于启发式设计。
- 当前的多专家方法大多采用不同的模型从不同方面学习知识,而它们之间的相互监督是不足的。
- 一般使用一组模型来进行预测,这导致推理阶段的复杂性增加。
方法
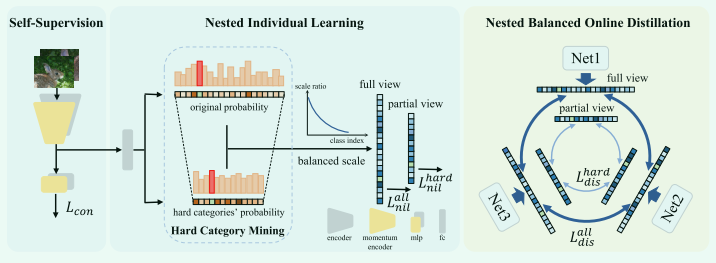
难(硬)类别挖掘(HCM)
hard category 是指不是真实类别但具有高预测分数的类别。 可以通过比较模型输出的值来选择难的类别
硬类别挖掘,说是自己提出来的,就有点脸皮厚了。其实大家好多都这么搞的。
嵌套个体学习 (NIL)
没什么好讲的,只是在loss设计上加上了难类别的损失
嵌套平衡在线蒸馏(NBOD)
对所有类别进行蒸馏,而且对 HCM 挖掘的一些困难类别进行蒸馏,这有助于网络捕获精细的区分能力。 采用 Kullback Leibler (KL) 散度来执行知识蒸馏。
loss设计同NIL,考虑难类别的loss
通过自监督增强特征
采用实例判别作为自监督代理任务,其中每个图像被视为一个不同的类别。
类似moco使用了队列
这篇关于NCL论文简单解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






