本文主要是介绍Linux0.11内核源码解析-malloc,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
malloc介绍
Linux内核版本0.11中的`malloc.c`文件实现了内存分配的功能。在这个版本的Linux内核中,`malloc.c`文件包含了内核级别的内存分配函数,用于分配和释放内核中的内存。这些函数可以帮助内核管理可用的内存,并允许内核动态地分配和释放内存,以便在运行时满足不同模块或进程的内存需求。基本上,它实现了类似C标准库中的`malloc()`和`free()`函数的功能,但是是针对内核级别的操作而设计的。
C标准库和内核中malloc区别
为了加以区分后面malloc命名为kmalloc,free命名为kfree
C标准库中的`malloc`函数和内核中的`malloc`函数之间存在一些关键区别:
1. **作用域不同**:C标准库中的`malloc`函数是用于用户空间程序的内存分配,而内核中的`malloc`函数是用于操作系统内核的内存管理。
2. **权限不同**:C标准库中的`malloc`函数只能操作用户空间的内存,而内核中的`malloc`函数可以直接操作系统的内存,包括内核空间的内存。
3. **实现不同**:C标准库中的`malloc`函数通常基于用户空间的堆实现,而内核中的`malloc`函数是基于内核空间的内存管理机制实现的,因此更加底层且复杂。
4. **用途不同**:C标准库中的`malloc`函数主要用于用户空间程序的动态内存分配,而内核中的`malloc`函数用于操作系统内核的动态内存分配,包括内核数据结构和缓冲区的分配。
bucket分配算法
Bucket(桶)内存分配算法是一种用于管理动态内存分配的方法,通常应用于用户空间的内存分配库。这种算法基于固定大小的内存块(或桶),每个桶大小相同,并且事先确定。这些桶可以是不同大小的内存块,以适应不同大小的内存需求。
其基本思想是将内存空间分割成预定义大小的桶(或块),例如8字节、16字节、32字节等。当程序请求分配一定大小的内存时,分配器会根据请求大小找到合适大小的桶,然后从这个桶中分配内存。如果某个桶中没有足够大小的内存可用,它会尝试从较大的桶中拆分出适当大小的内存块来满足请求。
这种算法的优点在于:
1. **降低内存碎片化**:通过使用预定义大小的桶,可以减少内存碎片化,因为每个桶大小是固定的,不会出现零散的小内存碎片。
2. **快速分配**:由于预定义了多个固定大小的桶,分配器只需根据请求大小找到对应的桶,因此分配速度相对较快。
不过,Bucket内存分配算法也有一些限制:
1. **内存浪费**:当需要的内存大小不完全匹配桶的大小时,可能会导致一定程度的内存浪费。
2. **固定桶大小**:由于每个桶大小是固定的,可能难以适应特定大小的内存需求。
结构体介绍
`struct bucket_desc`表示一个桶的描述符,包含以下字段:
- `void *page`:指向桶的起始地址。
- `struct bucket_desc *next`:指向下一个桶的描述符,用于构建链表。
- `void *freeptr`:指向桶中空闲内存的起始地址。
- `unsigned short refcnt`:引用计数,用于跟踪桶的使用情况。
- `unsigned short bucket_size`:桶的大小,表示每个桶可以分配的内存块大小。
`struct _bucket_dir`表示桶的目录,包含以下字段:
- `int size`:桶的目录大小,表示桶的数量。
- `struct bucket_desc *chain`:指向桶链表的头部,用于管理所有桶的分配情况。
这些结构体的设计是为了实现Bucket内存分配算法的核心功能。通过`struct bucket_desc`中的链表和引用计数,可以跟踪和管理每个桶的使用情况。而`struct _bucket_dir`中的链表头部和目录大小,可以帮助定位和管理所有桶的分配情况。
struct bucket_desc { /* 16 bytes */void *page;struct bucket_desc *next;void *freeptr;unsigned short refcnt;unsigned short bucket_size;
};struct _bucket_dir { /* 8 bytes */int size;struct bucket_desc *chain;
};struct _bucket_dir bucket_dir[] = {{ 16, (struct bucket_desc *) 0},{ 32, (struct bucket_desc *) 0},{ 64, (struct bucket_desc *) 0},{ 128, (struct bucket_desc *) 0},{ 256, (struct bucket_desc *) 0},{ 512, (struct bucket_desc *) 0},{ 1024, (struct bucket_desc *) 0},{ 2048, (struct bucket_desc *) 0},{ 4096, (struct bucket_desc *) 0},{ 0, (struct bucket_desc *) 0}}; /* End of list marker *//** This contains a linked list of free bucket descriptor blocks*/
struct bucket_desc *free_bucket_desc = (struct bucket_desc *) 0;

空闲存储桶
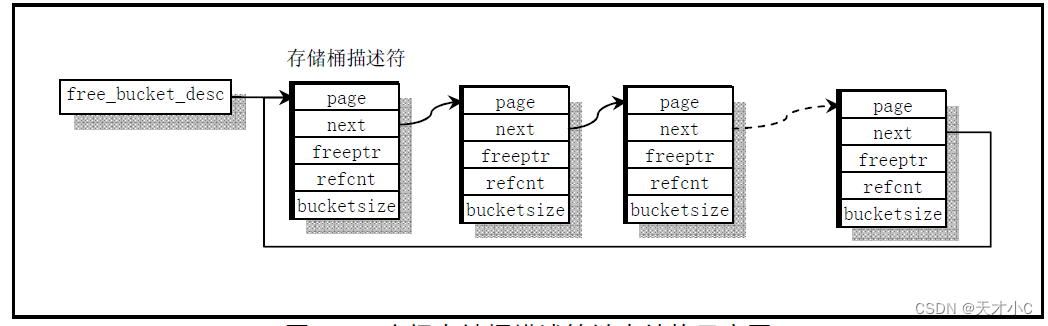
bucket结构体初始化
初始化桶描述符,建立空闲桶描述符链表
/** This routine initializes a bucket description page.*/
static inline void init_bucket_desc()
{struct bucket_desc *bdesc, *first;int i;申请一页内存first = bdesc = (struct bucket_desc *) get_free_page();if (!bdesc)panic("Out of memory in init_bucket_desc()");计算一页内存可存放桶描述符数量for (i = PAGE_SIZE/sizeof(struct bucket_desc); i > 1; i--) {bdesc->next = bdesc+1;bdesc++;}/** This is done last, to avoid race conditions in case * get_free_page() sleeps and this routine gets called again....*/将空闲桶描述指针加入链表bdesc->next = free_bucket_desc;free_bucket_desc = first;
}malloc函数
分配动态内存函数
void *malloc(unsigned int len)
{struct _bucket_dir *bdir;struct bucket_desc *bdesc;void *retval;/** First we search the bucket_dir to find the right bucket change* for this request.*/找到合适的桶for (bdir = bucket_dir; bdir->size; bdir++)if (bdir->size >= len)break;if (!bdir->size) {printk("malloc called with impossibly large argument (%d)\n",len);panic("malloc: bad arg");}/** Now we search for a bucket descriptor which has free space*/cli(); /* Avoid race conditions */寻找对应的桶空闲空间的桶描述符for (bdesc = bdir->chain; bdesc; bdesc = bdesc->next) if (bdesc->freeptr)break;/** If we didn't find a bucket with free space, then we'll * allocate a new one.*/if (!bdesc) {char *cp;int i;if (!free_bucket_desc) init_bucket_desc();bdesc = free_bucket_desc;free_bucket_desc = bdesc->next;bdesc->refcnt = 0;bdesc->bucket_size = bdir->size;bdesc->page = bdesc->freeptr = (void *) (cp = get_free_page());if (!cp)panic("Out of memory in kernel malloc()");/* Set up the chain of free objects */for (i=PAGE_SIZE/bdir->size; i > 1; i--) {*((char **) cp) = cp + bdir->size;cp += bdir->size;}*((char **) cp) = 0;bdesc->next = bdir->chain; /* OK, link it in! */bdir->chain = bdesc;}返回指针即等于该描述符对应页面的当前空闲指针retval = (void *) bdesc->freeptr;调整空闲指针指向下一个对象bdesc->freeptr = *((void **) retval);引用+1bdesc->refcnt++;开发中断sti(); /* OK, we're safe again */return(retval);
}free释放内存
/** Here is the free routine. If you know the size of the object that you* are freeing, then free_s() will use that information to speed up the* search for the bucket descriptor.* * We will #define a macro so that "free(x)" is becomes "free_s(x, 0)"*/
void free_s(void *obj, int size)
{void *page;struct _bucket_dir *bdir;struct bucket_desc *bdesc, *prev;bdesc = prev = 0;/* Calculate what page this object lives in */page = (void *) ((unsigned long) obj & 0xfffff000);/* Now search the buckets looking for that page */for (bdir = bucket_dir; bdir->size; bdir++) {prev = 0;/* If size is zero then this conditional is always false */if (bdir->size < size)continue;for (bdesc = bdir->chain; bdesc; bdesc = bdesc->next) {if (bdesc->page == page) goto found;prev = bdesc;}}panic("Bad address passed to kernel free_s()");
found:cli(); /* To avoid race conditions */*((void **)obj) = bdesc->freeptr;bdesc->freeptr = obj;bdesc->refcnt--;if (bdesc->refcnt == 0) {/** We need to make sure that prev is still accurate. It* may not be, if someone rudely interrupted us....*/if ((prev && (prev->next != bdesc)) ||(!prev && (bdir->chain != bdesc)))for (prev = bdir->chain; prev; prev = prev->next)if (prev->next == bdesc)break;if (prev)prev->next = bdesc->next;else {if (bdir->chain != bdesc)panic("malloc bucket chains corrupted");bdir->chain = bdesc->next;}free_page((unsigned long) bdesc->page);bdesc->next = free_bucket_desc;free_bucket_desc = bdesc;}sti();return;
}这篇关于Linux0.11内核源码解析-malloc的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







