本文主要是介绍图解图论介绍及应用(4):Twitter的例子: Tweet的触达问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Ayoosh Kathuria
编译:ronghuaiyang
知识图谱是AI领域非常有用的一种工具,知识图谱的基础就是图论,从今天开始,给大家介绍一些图论的基础内容,今天是第5篇,Twitter的例子: Tweet的触达问题。
这是另一种表示,称为邻接矩阵,它在有向图中可能很有用,就像我们在Twitter关注者图中使用的邻接矩阵。
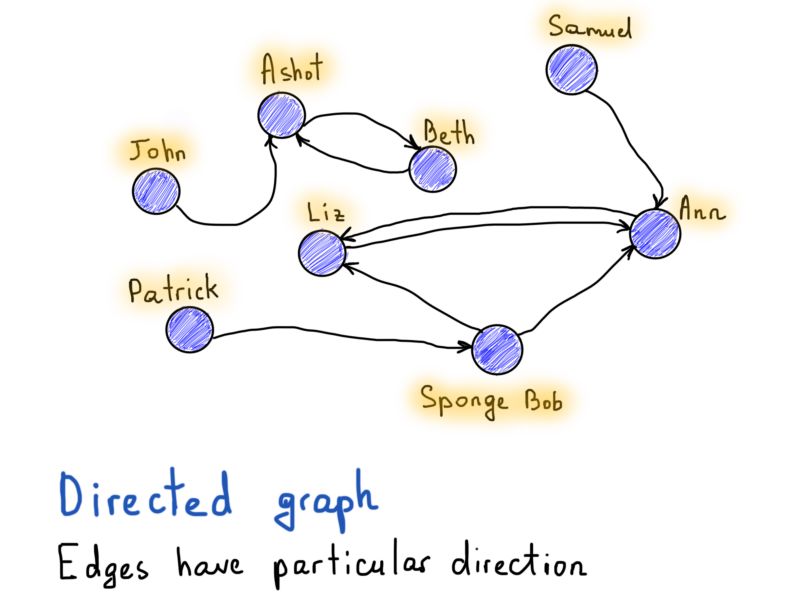
在这个Twitter示例中有8个顶点。所以我们需要表示这个图就是一个|V|x|V|方阵(|V|行和|V|列),如果有一条从v到u的有向边,则矩阵的 [v][u]为真,否则为假。
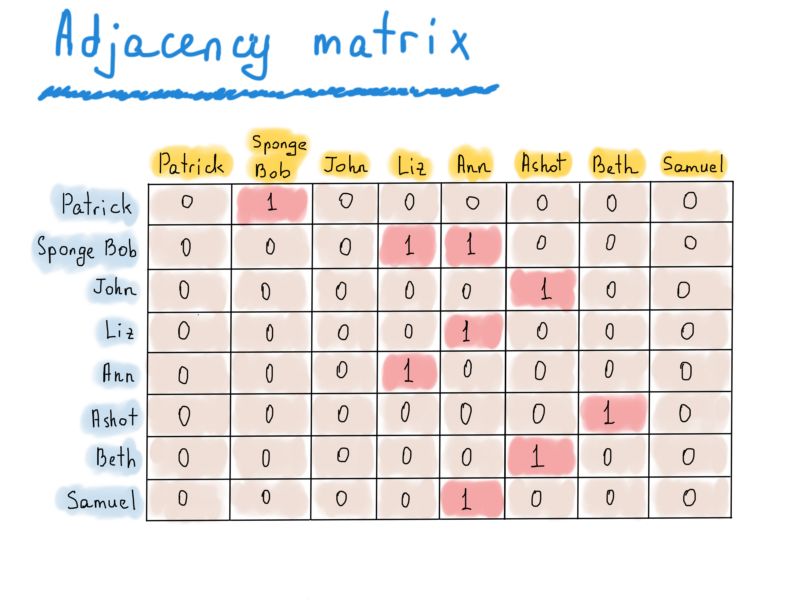
正如你所看到的,这个矩阵太稀疏了,但是可以快速访问。要查看Patrick是否follows了Sponge Bob,我们可以检查矩阵 ["Patrick"]["Sponge Bob"]的值。为了得到Ann的follower者列表,我们只需要处理整个“Ann”的列(标题为黄色)。为了发现Sponge Bob在follower谁(听起来很奇怪),我们处理整行“Sponge Bob”。邻接矩阵也可以用于无向图,如果a有一条从v到u的边,我们应该把两个值都设为1,例如adjmatrix [v][u] = 1,adjmatrix [u][v] = 1,而不是只设置一个1。无向图的邻接矩阵是对称的。
注意,我们可以存储一些“更有用的”东西,比如边的权值,而不是在邻接矩阵中存储1和0。最好的例子之一可能是带有距离信息的位置图。
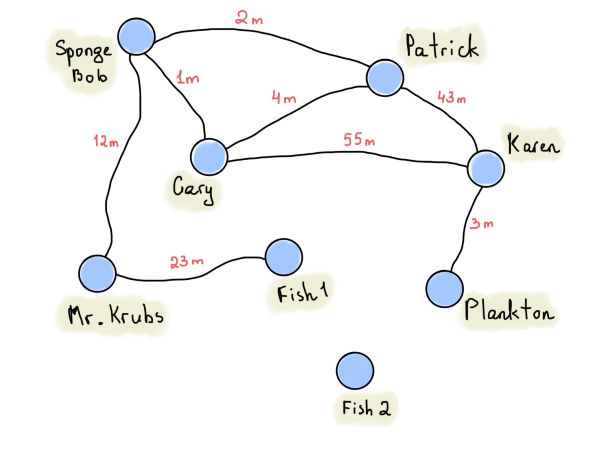
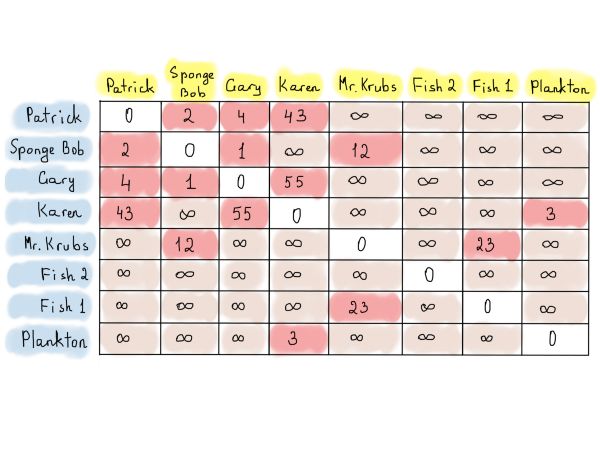
上图为Patrick、Sponge Bob等房子之间的距离(也称为加权图)。如果顶点之间没有直接的路径,我们就用“无穷大”符号。这并不意味着根本就没有路线,同时也不意味着一定有路线。它可能只是用在应用算法来寻找顶点之间的路径时定义的(有一种更好的方法来存储与之关联的顶点和边,称为关联矩阵)。

虽然邻接矩阵似乎很好地应用于Twitter的followe图,但是为近3亿用户(每月活跃用户)保存一个方阵需要3亿 * 3亿 * 1字节(存储布尔值)。也就是说,~82000 Tb (Tb),即1024 * 82000 Gb。用Bitsets吗?BitBoard可以帮助我们节省一点,将所需的大小减少到~10000 Tb。但是还是太大了。如上所述,邻接矩阵过于稀疏。它迫使我们使用比实际需要更多的空间。这就是为什么使用与顶点关联的边列表可能是有用的。关键是,邻接矩阵允许我们同时保留“follow”和“doesn 't follow”信息,而我们所需要的只是知道关于以下内容的信息,比如:
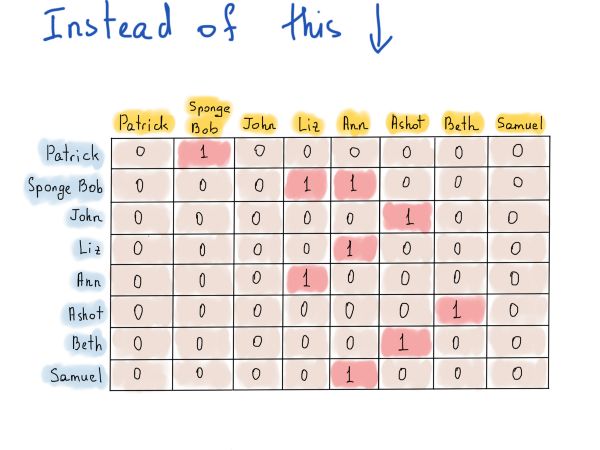
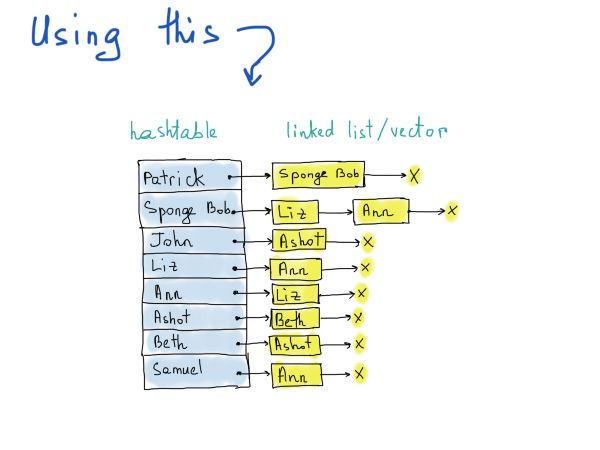
下边的插图称为邻接表。每个表描述了图中一个顶点的一组邻居。顺便说一下,图表示法作为邻接表的实际实现也是不同的。在插图中,我们突出显示了一个hashtable的用法,这是合理的,因为任何顶点的访问都是O(1),对于相邻顶点的列表,我们没有提到确切的数据结构,而是从链表转向了向量。你可以自由选择。
关键是,为了查明Patrick是否关注了Liz,我们应该访问hashtable(常量时间)并遍历列表中的所有项,将每个元素与“Liz”元素进行比较(线性时间)。在这一点上,线性时间并没有那么糟糕,因为我们只需要循环与“Patrick”相邻的固定数量的顶点。空间的复杂性呢,在Twitter上使用可以吗?我们需要至少3亿个hashtable记录,每个记录指向一个向量(选择向量以避免链表的左/右指针的内存开销),其中包含多少?这里没有统计数据,只发现twitter的平均粉丝数为707(谷歌搜索)。
因此,如果我们考虑每个hashtable记录指向一个由707个用户id组成的数组(每个值为8字节),并且假设hashtable的开销只是它的键,同样是用户id,因此hashtable本身需要3亿* 8字节。总的来说,哈希表有3亿* 8字节+每个哈希表键有707 * 8字节,即3亿* 8 * 707 * 8字节= *~ 12tb *。不能说感觉好多了,但是感觉比10000 Tb好多了。
老实说,我不知道这个12Tb的数字是否合理。但是考虑到我花了大约30美元在一台32gb RAM的专用服务器上,那么存储(分片)12tb至少需要385台这样的服务器,再加上一对控制服务器(用于数据分发控制),最多需要400台。所以我每月要花1.2万美元。
考虑到数据应该被复制,而且总是会出错,我们将服务器数量增加三倍,然后再添加一些控制服务器,假设我们至少需要1500台服务器,这每月将花费4.5万美元。当然,这对我来说并不好,因为我几乎不能保存一个服务器,但是对于Twitter来说似乎还可以(与真正的Twitter服务器相比,它实际上什么都不是)。让我们假设Twitter真的没问题。
现在,我们还好吧?还没有,那只是关于关注者的数据。Twitter的主要内容是什么?我的意思是,从技术上讲,它最大的问题是什么?如果你说这是Twitter的快速传递,我绝对支持。不是快,而是闪电般的快。比方说Patrick发了一条关于他对食物的想法的Twitter,他的所有关注者都应该在合理的时间收到这条Twitter。需要多长时间?我们在这里不做任何假设,也不使用任何我们想要的抽象,但是我们对现实世界的生产系统很感兴趣,所以,让我们来挖掘一下。以下是人们发Twitter时通常会发生的情况。
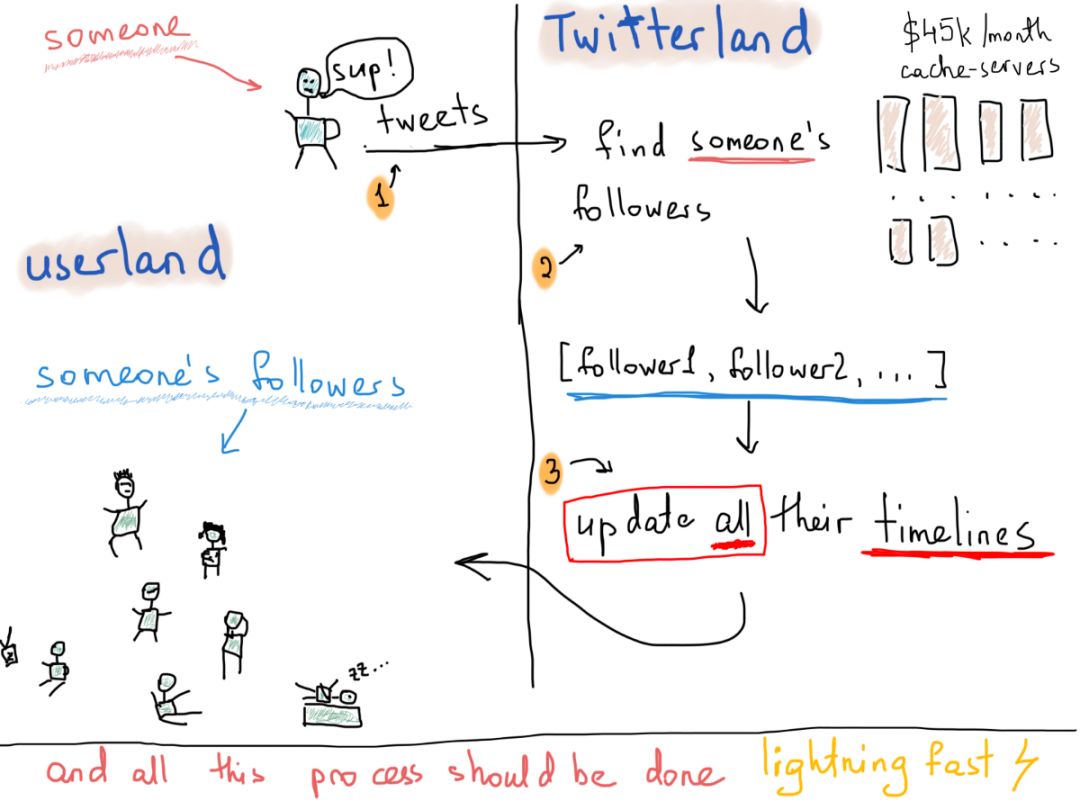
同样,我们也不知道一条推文需要多长时间才能到达所有的关注者,但是公开的统计数据告诉我们,每天大约有5亿条推文。每天!
以上过程每天发生5亿次。我真的找不到任何关于推特发送速度的东西。我依稀记得,一条推文最多能在5秒内到达所有关注者。同时也要注意“‘heavy cases”,即拥有100多万粉丝的名人。他们可能会在推特上发布一些关于他们在海滨别墅享用美味早餐的消息,但推特非常努力地将这些超级有用的内容传递给数百万粉丝。
为了解决推文传递问题,我们并不需要关注者的图,而是需要另外一个被关注者的图。前面的图(带有散列表和一组列表)允许我们高效地找到所有用户后面跟着的任何的特定用户。但是,它不允许我们有效地找到跟踪某个特定用户的所有用户,在这种情况下,我们必须扫描所有散列表键。这就是为什么我们应该构造另一个图,它与我们为追随者构造的图是对称的。这个新的图将再次由一个包含所有3亿个顶点的哈希表组成,每个顶点都指向一个相邻顶点列表(结构保持不变),但这一次,相邻顶点列表将表示追随者。
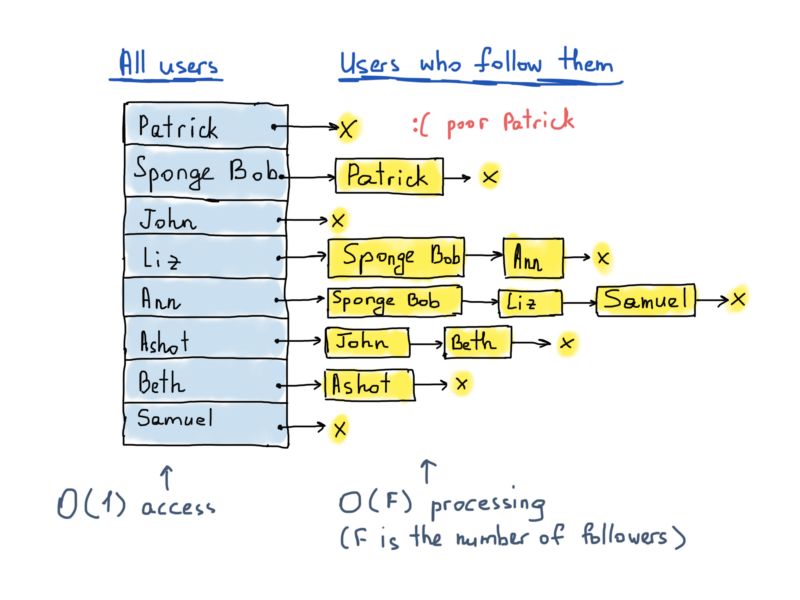
所以根据这个例子,无论什么时候Liz发了什么,Sponge Bob和Ann必须在有限时间内看到这条推文。实现此目的的一种常见技术是为每个用户的时间轴保留单独的结构。对于Twitter的3亿多用户,我们可能会假设至少有3亿多时间轴(每个用户)。基本上,无论用户何时发布tweet,我们都应该获取用户追随者的列表,并更新他们的时间轴(将相同的tweet插入其中的每一条)。时间轴可以表示为链表,也可以表示为平衡树(tweet datetimes作为节点键)。
// 'author' represents the User object, at this point we are interested only in author.id
//
// 'tw' is a Tweet object, at this point we are interested only in 'tw.id'
void DeliverATweet(User* author, Tweet* tw)
{ // we assume that 'tw' object is already stored in a database // 1. Get the list of user's followers (author of the tweet) vector<User*> user_followers = GetUserFollowers(author->id); // 2. insert tweet into each timeline for (auto follower : user_followers) { InsertTweetIntoUserTimeline(follower->id, tw->id); }
}这只是我们从实际的时间轴表示中抽象出来的一个基本概念,当然,如果我们使用多线程,我们可以使实际的交付更快。这对于“‘heavy cases”来说是至关重要的,因为对于数百万关注者来说,那些位于列表末尾的事件要比那些位于列表前列的事件处理得晚。
下面的伪代码试图阐明这个多线程交付思想:
// Warning: a bunch of pseudocode ahead
void RangeInsertIntoTimelines(vector<long> user_ids, long tweet_id)
{ for (auto id : user_ids) { InsertIntoUserTimeline(id, tweet_id); }
}
void DeliverATweet(User* author, Tweet* tw)
{ // we assume that 'tw' object is already stored in a database // 1. Get the list of user's (tweet author's) followers's ids vector<long> user_followers = GetUserFollowers(author->id); // 2. Insert tweet into each timeline in parallel const int CHUNK_SIZE = 4000; // saw this somewhere for (each CHUNK_SIZE elements in user_followers) { Thread t = ThreadPool.GetAvailableThread(); // somehow t.Run(RangeInsertIntoTimelines, current_chunk, tw->id); }
}因此,只要关注者刷新他们的时间轴,他们就会收到新的推文。
公平地说,我们只是触及了Airbnb或Twitter真正问题的冰山一角。在Twitter、谷歌、Facebook、亚马逊(Amazon)、Airbnb等复杂系统中,要实现如此伟大的成果,需要非常长的时间和非常有才华的工程师的辛勤工作。在阅读这篇文章时,请记住这一点。
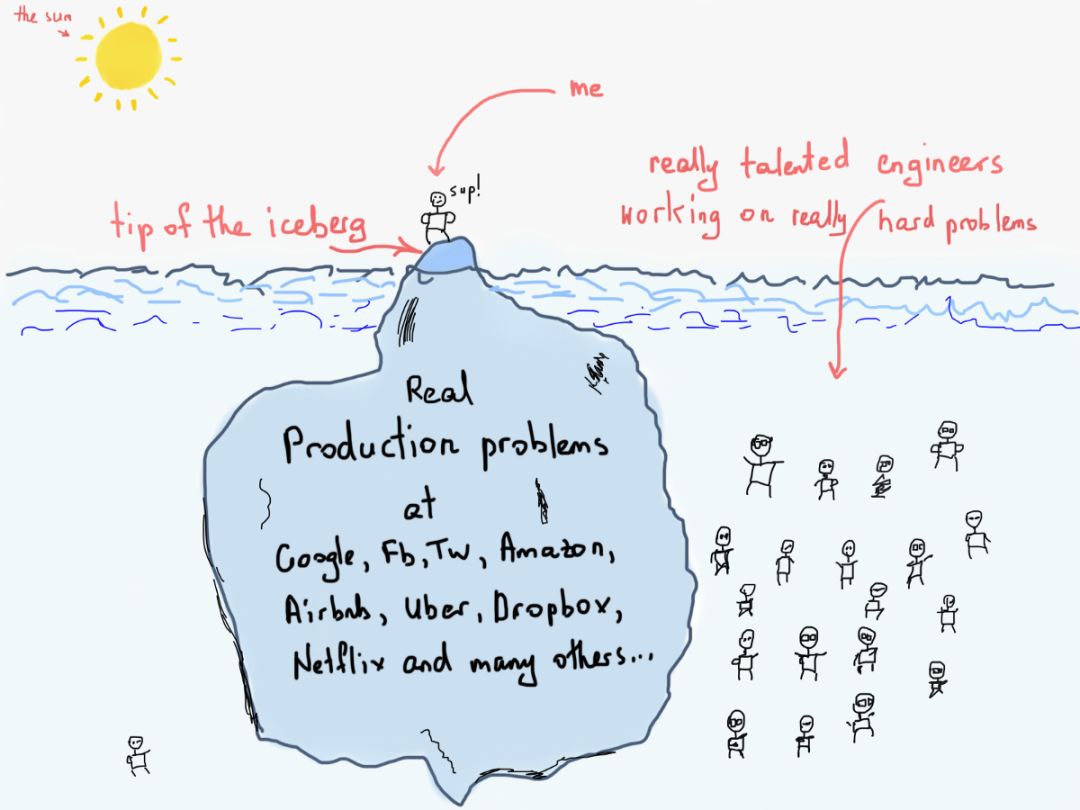
演示Twitter的推文交付问题的重点是使用图,尽管我们没有使用任何图算法,我们只是使用了图的表示。当然,我们为发送tweet用伪代码写了一个函数,但这是我们在搜索解决方案的过程中发现的。
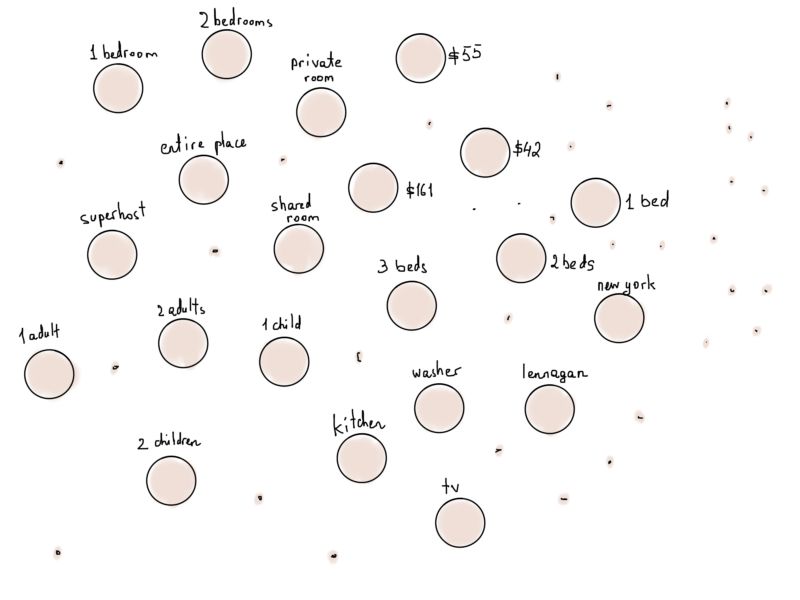
我所说的“任意的图算法”是指任何算法。图论和图算法应用大到足以让程序员哭笑不得,乍一看,它们有些不同。我们在讲完图表示之前讨论了Airbnb房屋和高效过滤,最明显的问题是无法有效地过滤多个过滤键的房屋。有什么可以用图算法来做的吗?嗯,我们不能肯定,但至少我们可以试试。如果我们把每个过滤器表示为一个单独的顶点呢?
每个过滤器,甚至所有的价格从10美元到1000美元以上,所有的城市名称,国家代码,设施(电视,Wi-Fi,和所有其他),成年人的数量,和每个数字作为一个单独的图形顶点。
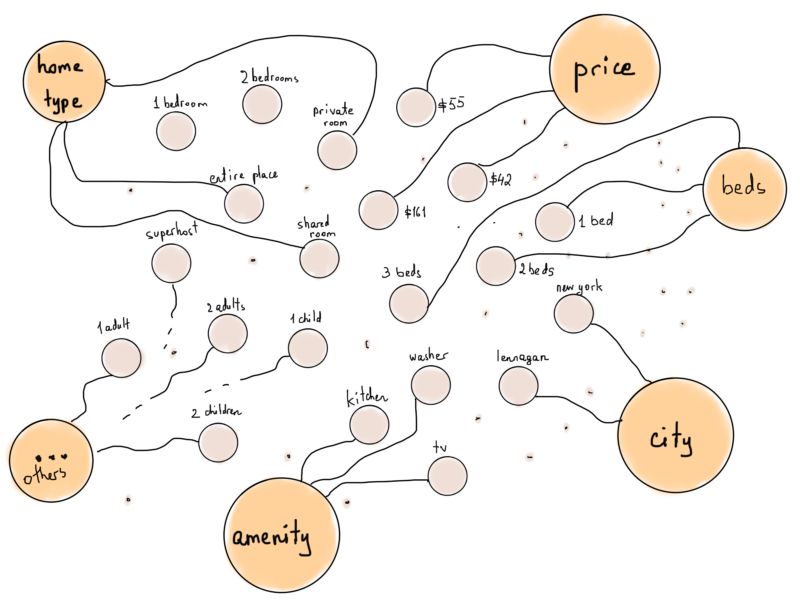
我们甚至可以使这组顶点更加“友好”,如果我们添加“类型”顶点,就像“便利设施”连接到所有代表便利过滤器的顶点。
现在,如果我们将Airbnb的home表示为顶点,然后如果home支持相应的过滤器,则将每个home与“filter”顶点连接(例如,如果home 1的便利设施中有“kitchen”,则将“home 1”与“kitchen”连接),结果会怎样?
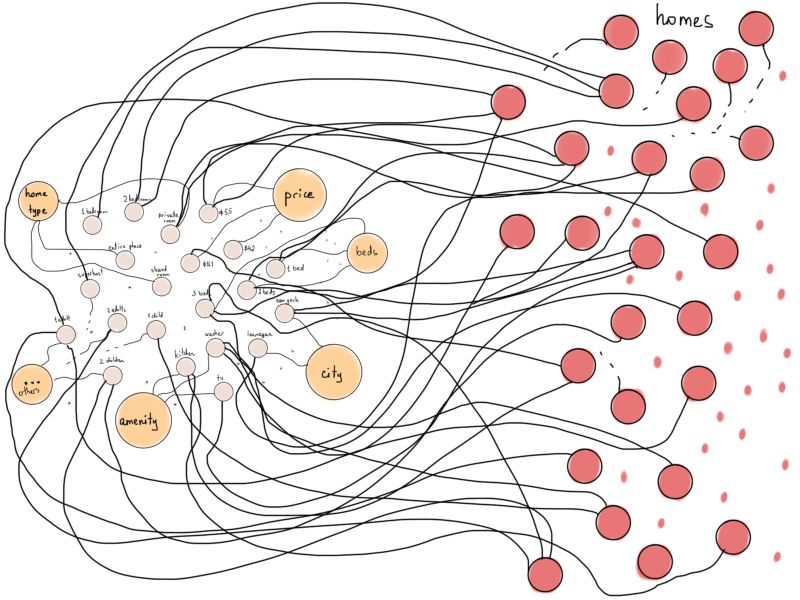
这个图的一个细微变化使它更可能类似于一种特殊类型的图,称为二分图。
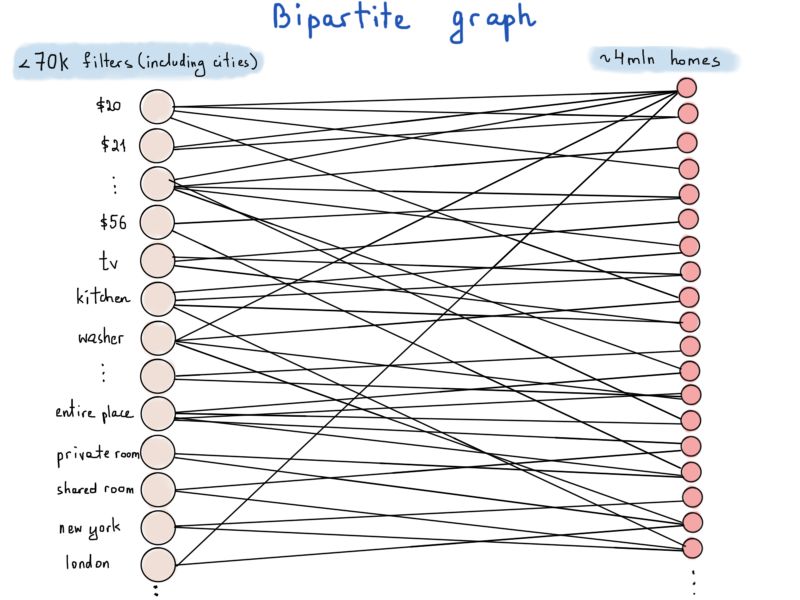
二分图是一个图,它的顶点可以被分成两个不相交的独立集合,这样每条边都将一个集合中的顶点连接到另一个集合中的顶点。
在我们的例子的一个集代表过滤器(F)我们会表示,另一个是一套房子(用H)。例如,如果价格有10万户家庭价值62美元,然后价格顶点标记“62美元”每个顶点将有10万条边。如果我们测量空间复杂性的最坏情况,即每个家庭都有满足所有过滤器的所有属性,那么要存储的边总数将是70,000 * 4,000,000。如果我们将每条边表示为一对两个id: {filter_id;如果我们重新考虑id,为过滤器使用4字节(int)数字id,为home使用8字节(long)数字id,那么每条边至少需要12个字节。因此,存储70,000 * 4,000,000个12字节的值将需要大约3Tb的内存。
由于Airbnb上活跃着6.5万个城市,过滤器的数量约为7万个。好消息是,同一个home不能位于一个以上的城市。也就是说,我们与城市配对的实际边的数量是400万个(每个家庭位于一个城市)。我们将计算70k - 65k = 5000个过滤器,这意味着我们需要5000 * 400万* 12字节的内存,这小于0.3 Tb。听起来不错。但是是什么给了我们这个二分图?最常见的一个网站/移动请求将包括几个过滤器,例如:
house_type: "entire_place",
adults_number: 2,
price_range_start: 56,
price_range_end: 80,
beds_number: 2,
amenities: ["tv", "wifi", "laptop friendly workspace"],
facilities: ["gym"]我们所需要的就是找到上面所有的“过滤器顶点”,并处理所有与这些“过滤器顶点”相邻的“主顶点”。这就引出了一个可怕的话题。
(未完待续)
 — END—
— END— 英文原文:https://medium.com/free-code-camp/i-dont-understand-graph-theory-1c96572a1401

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于图解图论介绍及应用(4):Twitter的例子: Tweet的触达问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





